File类
路径分隔符&目录分隔符
1 | String pathSeparator = File.pathSeparator; |
相对路径&绝对路径
1 | 绝对路径:是一个完整的路径 |
构造方法
public File(String pathname)通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例
0. 可传相对路径,绝对路径。
- 一个File对象代表硬盘中实际存在的一个文件或者目录。
- 无论该路径下是否存在文件或者目录,都不影响File对象的创建。
构造方法
两种创建的方式public File(String pathname)public File(String parent, String child)
1 | System.out.println(new File("D:\\Everything\\a").getAbsolutePath());// D:\Everything\a |
常用方法
public String getAbsolutePath()获取绝对路径public String getPath()获取路径public File getAbsoluteFile()获取绝对文件public String getParent()获取文件的父级路径。public String getName()文件或目录名称,不存在也会返回。public long length()获取文件字节数。文件或目录不存在是0。目录一般返回扇区空间4096或8192等
public boolean exists()是否存在public boolean isFile()是文件吗public boolean isDirectory()是目录吗
public boolean createNewFile()创建新文件,不能创建目录,路径错误会异常。public boolean delete()删除单个文件或目录,不是空目录返回false。public boolean mkdir()创建单个目录public boolean mkdirs()创建层级目录,已存在返回false
public String[] list()返回目录内的文件和子目录名称public File[] listFiles()返回目录内的文件和子目录File对象
public boolean renameTo(File dest)文件重命名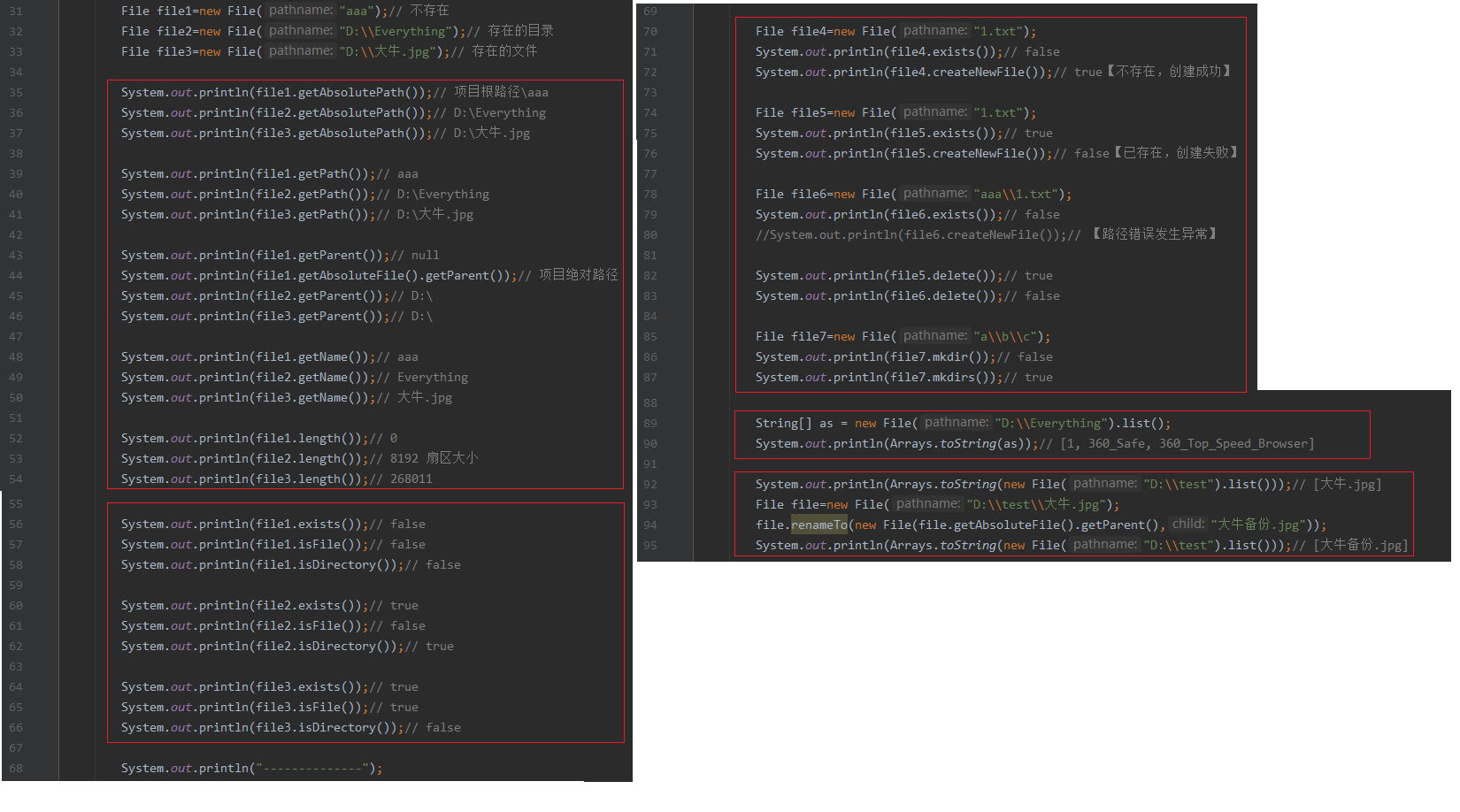
创建&最后访问时间
1 | public static void main(String[] args) throws Exception |
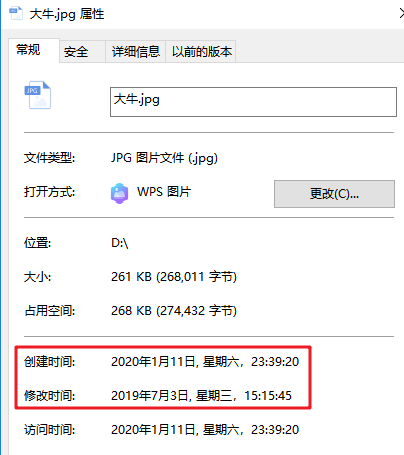
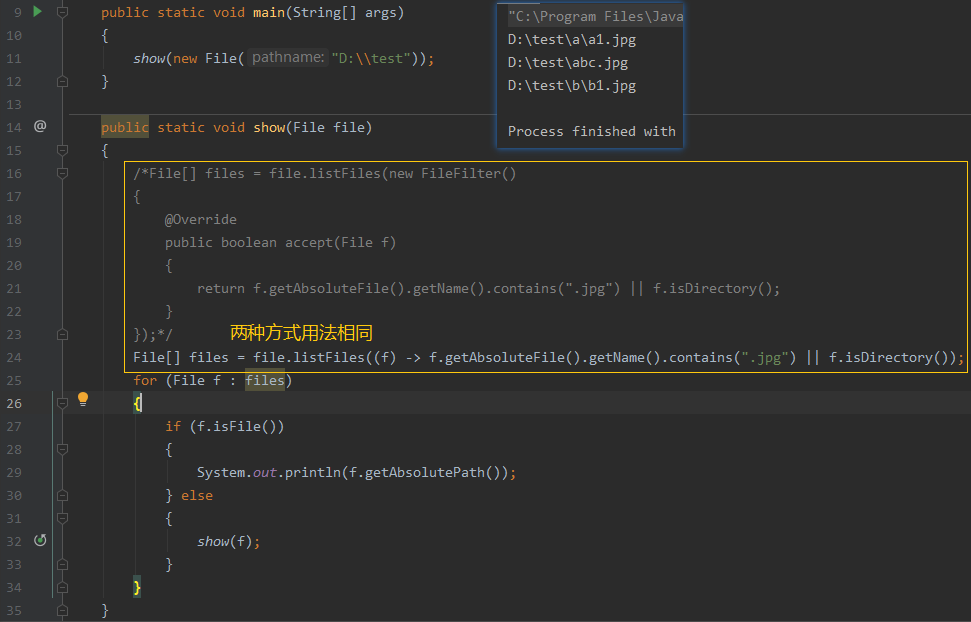
递归案例
遍历目录
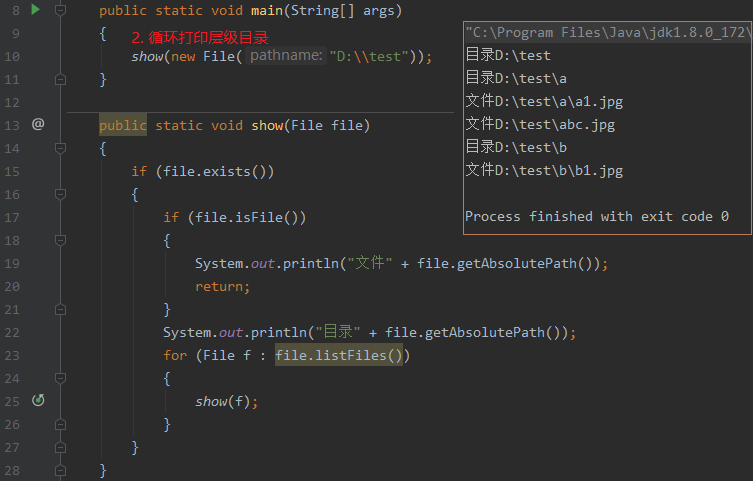
文件搜索
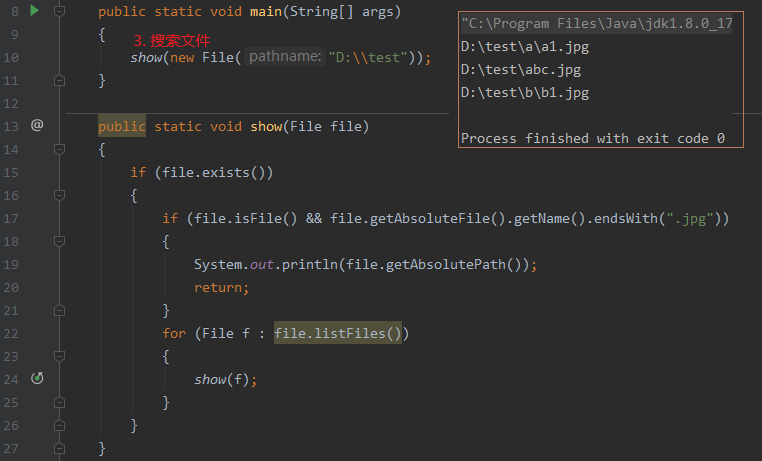
FileFilter简化搜索
字节流
OutputStream字节输出流
java.io.OutputStream字节输出流。此抽象类是表示输出字节流的所有类的超类。
定义了一些子类共性的成员方法:
public void write(int b)一次写入一个字节public void write(byte[] b)一次写入多个字节public void write(byte[] b, int off, int len)从off开始,写入len个字节。public void flush()刷新数据到文件中。public void close()关闭资源,释放内存。
FileOutputStream文件字节输出流
java.io.FileOutputStream extends OutputStream
FileOutputStream:文件字节输出流
作用:把数据写入文件
public FileOutputStream(String name)文件没有会创建,路径不存在会报错public FileOutputStream(String name, boolean append)默认false创建一个新文件覆盖源文件,内容追加true
public FileOutputStream(File file)public FileOutputStream(File file, boolean append)
public void write(int b)一次写入一个字节public void write(byte b[])一次写入多个字节,多用于配合String类的getBytes()方法public void write(byte b[], int off, int len)从off开始,写入len个字节。
public void flush()刷新数据到文件中。public void close()关闭资源,释放内存。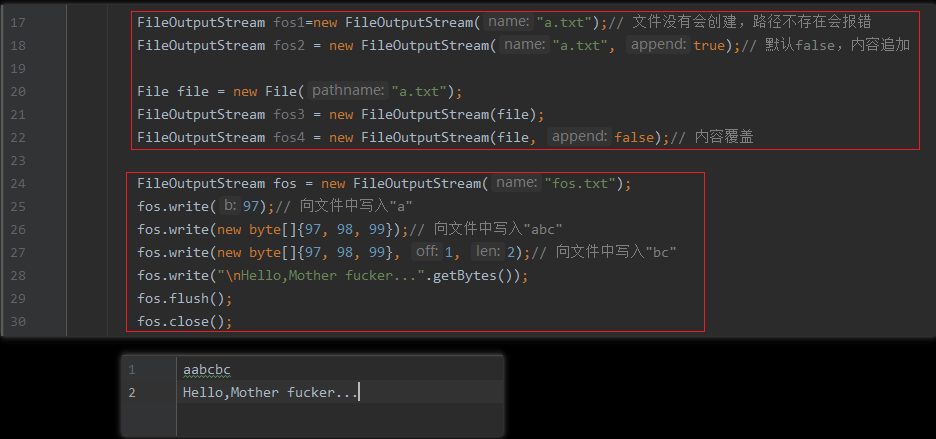
对应ASCII码表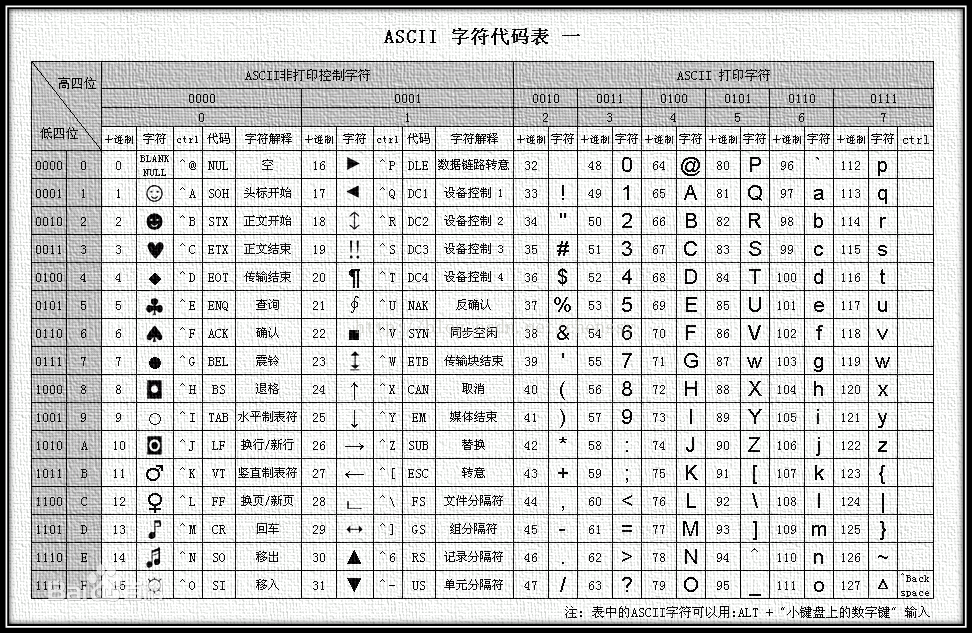
文件存储&记事本打开文件的原理
InputStream字节输入流
java.io.InputStream:字节输入流。此抽象类是表示字节输入流的所有类的超类。
定义了所有子类共性的方法:
int read()从输入流中读取数据的下一个字节。int read(byte[] b)从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。int read(byte b[], int off, int len)从off开始,读取len个字节。void close()关闭资源,释放内存。
FileInputStream文件字节输入流
java.io.FileInputStream extends InputStream
FileInputStream:文件字节输入流
作用:从文件中读取数据public FileInputStream(String name)public FileInputStream(File file)
int read()从输入流中读取数据的下一个字节。int read(byte[] b)从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。int read(byte b[], int off, int len)从off开始,读取len个字节。可参考文件复制案例。
void close()关闭资源,释放内存。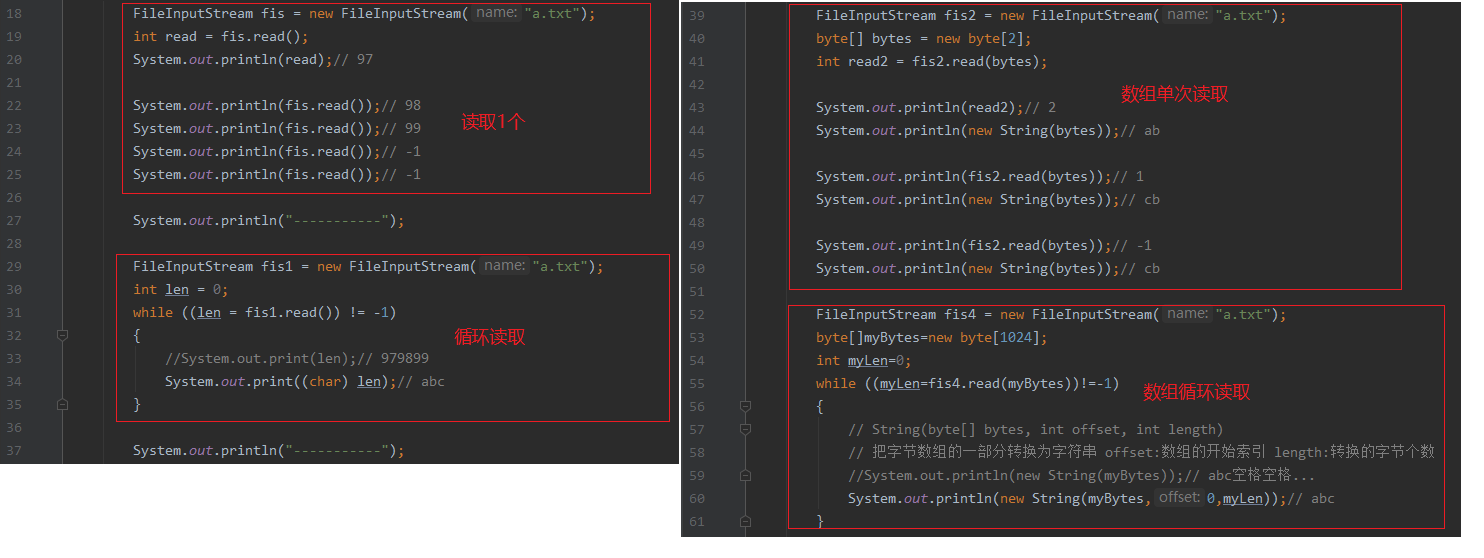
字节流读取文件的原理

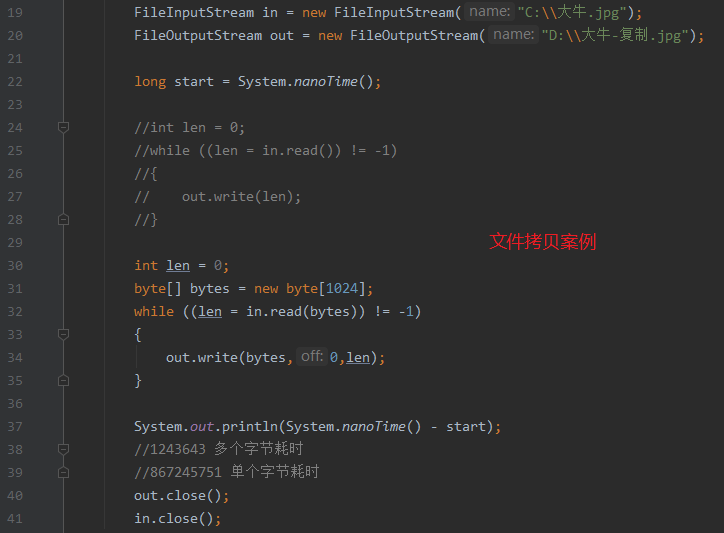
文件复制案例
文件读取中文乱码问题
解决方式可使用Reader字符流进行解决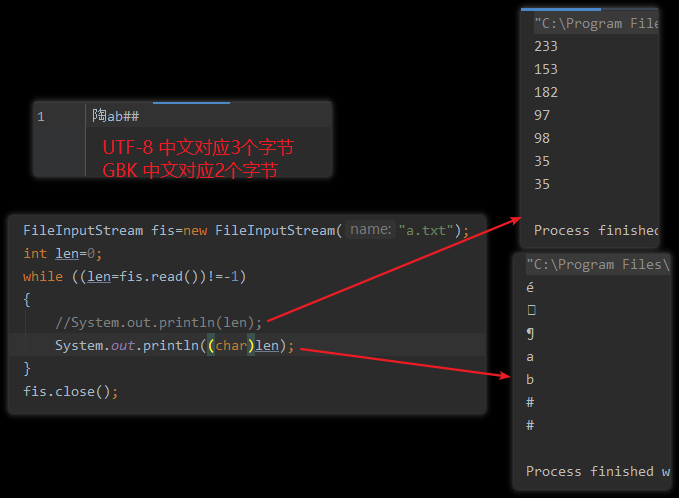
字符流
当使用字节流读取文本文件时,可能会有一个小问题。
就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储。
所以Java提供一些字符流类,以字符为单位读写数据,专门用于处理文本文件。
Reader字符输入流
java.io.Reader抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。
它定义了字符输入流的基本共性功能方法。
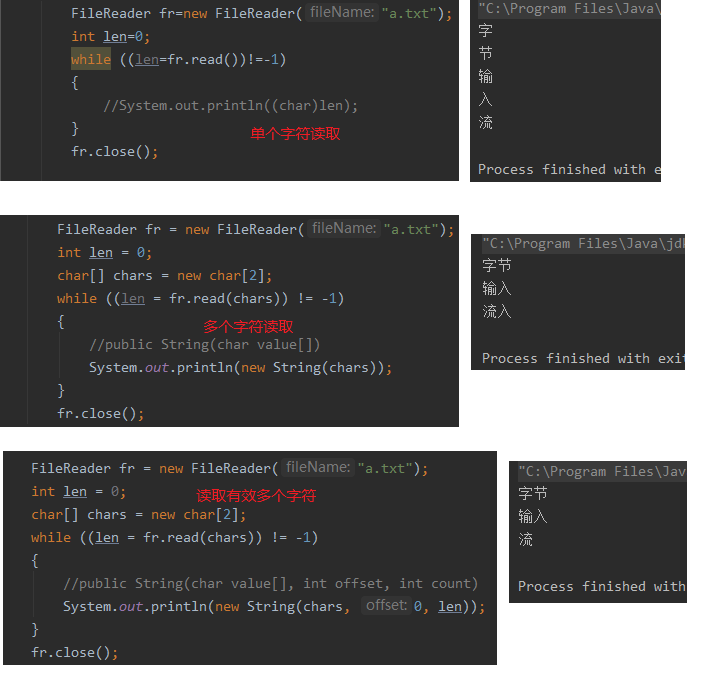
public int read()读取一个字符。public int read(char[] cbuf)读取多个字符。public int read(char cbuf[], int off, int len)从off开始,读取len个字符。public void close()关闭资源。
FileReader文件字符输入流
java.io.FileReader文件字符输入流。Windows系统的中文编码默认是GBK编码表。
构造时使用系统默认的字符编码和默认字节缓冲区。
类似于文件字节输入流FileInputStreampublic FileReader(String fileName)public FileReader(File file)
Writer字符输出流
java.io.Writer抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。
它定义了字节输出流的基本共性功能方法。
void write(int c)写入单个字符。void write(char[] cbuf)写入字符数组。void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。void write(String str)写入字符串。void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。void flush()(重点)刷新该流的缓冲。void close()关闭此流,但要先刷新它。
FileWriter文件字符输出流
java.io.FileWriter文件字符输出流。Windows系统的中文编码默认是GBK编码表。
构造时使用系统默认的字符编码和默认字节缓冲区。
类似于文件字节输出流FileOutputStreampublic FileReader(String fileName)public FileReader(File file)public FileWriter(String fileName, boolean append)public FileWriter(File file, boolean append)
1 | 字符输出流的使用步骤(重点): |

flush与close区别
flush:刷新一下缓冲区,不关闭流。
close:刷新一下缓冲区,关闭流。
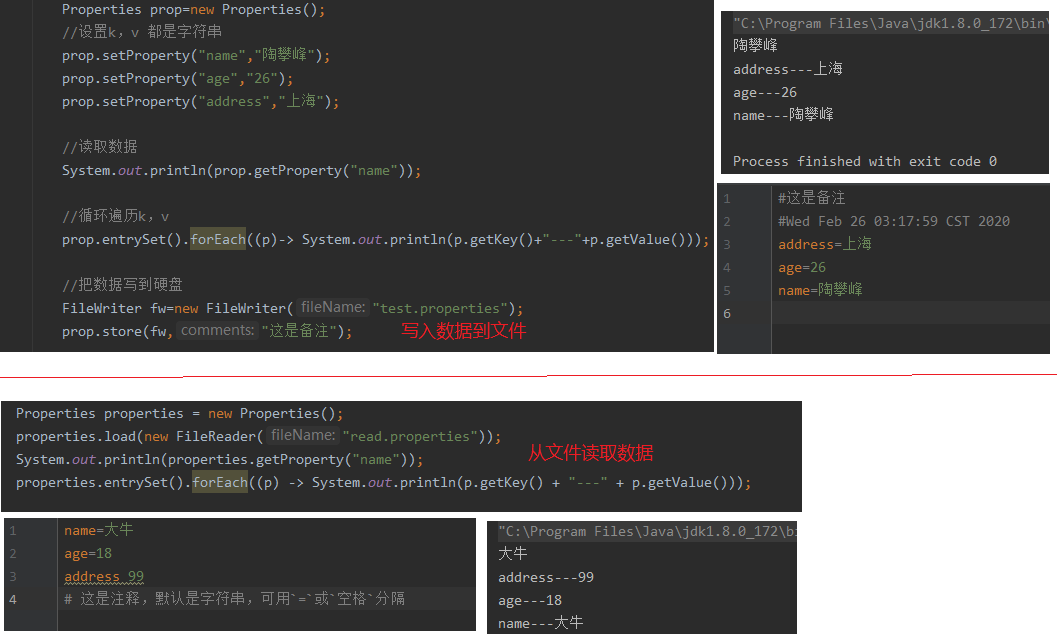
Properties类
缓冲流
相当于对基本流对象的加强,内部封装了缓存数组。
字节缓冲流
对字节流的封装。
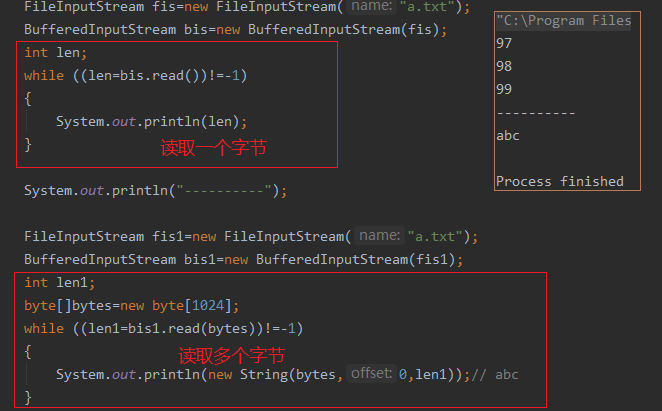
BufferedInputStream
java.io.BufferedInputStream extends InputStream
BufferedInputStream:字节缓冲输入流
继承自父类的成员方法
int read()从输入流中读取数据的下一个字节。int read(byte[] b)从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。int read(byte b[], int off, int len)从off开始,读取len个字节。void close()关闭资源,释放内存。
构造方法
public BufferedInputStream(InputStream in)默认缓冲区大小8192=8KB,提供执行效率。public BufferedInputStream(InputStream in, int size)可指定缓冲区大小
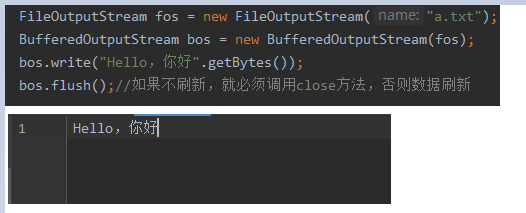
BufferedOutputStream
java.io.BufferedOutputStream extends OutputStreamBufferedOutputStream:字节缓冲输出流
继承自父类的成员方法
public void write(int b)一次写入一个字节public void write(byte b[])一次写入多个字节,多用于配合String类的getBytes()方法public void write(byte b[], int off, int len)从off开始,写入len个字节。public void flush()刷新数据到文件中。如果不刷新也不调用close方法,则缓冲区数据不会刷新到文件中。public void close()关闭资源,释放内存。
构造方法
public BufferedOutputStream(OutputStream out)默认缓冲区大小8192=8KB,提供执行效率。public BufferedOutputStream(OutputStream out, int size)可指定缓冲区大小
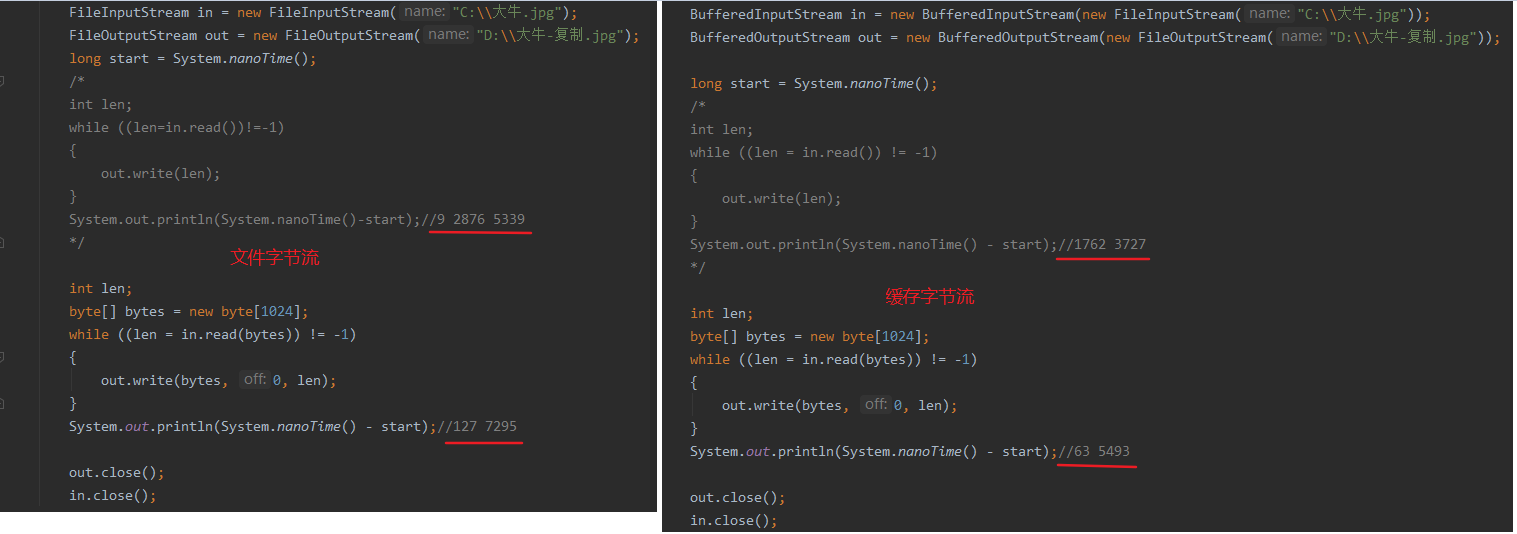
缓冲流效率测试
字符缓冲流
对字符流的封装。
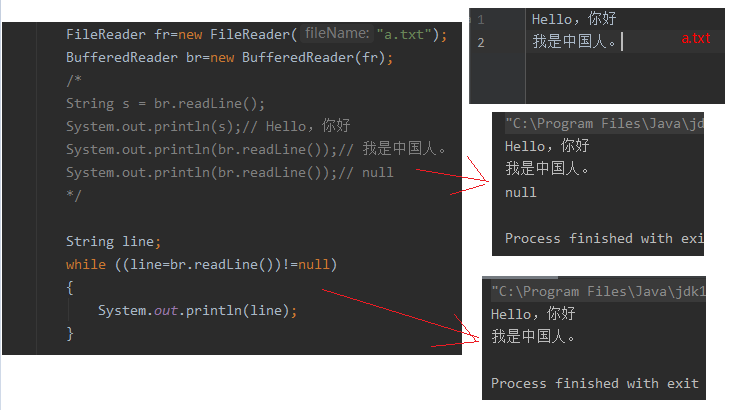
BufferedReader
java.io.BufferedReader extends Reader
BufferedReader:字符缓冲输入流
继承自父类的成员方法
public int read()读取一个字符。public int read(char[] cbuf)读取多个字符。public int read(char cbuf[], int off, int len)从off开始,读取len个字符。public void close()关闭资源。
构造方法
public BufferedReader(Reader in)默认8192=8KBpublic BufferedReader(Reader in, int sz)自定义缓存区大小
特有方法
public String readLine()读取行,以\rMac\nLinux\r\nWindows这三种换行符进行分割。
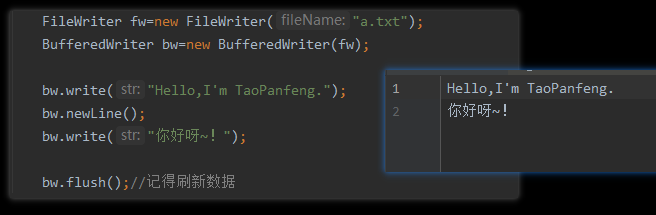
BufferedWriter
java.io.BufferedWriter extends Writer
BufferedWriter:字符缓冲输出流
继承自父类的成员方法
void write(int c)写入单个字符。void write(char[] cbuf)写入字符数组。void write(char[] cbuf, int off, int len)写入字符数组的某一部分,off数组的开始索引,len写的字符个数。void write(String str)写入字符串。void write(String str, int off, int len)写入字符串的某一部分,off字符串的开始索引,len写的字符个数。void flush()(重点)刷新该流的缓冲。void close()关闭此流,但要先刷新它。
构造方法
public BufferedWriter(Writer out)默认8192=8KBpublic BufferedWriter(Writer out, int sz)自定义缓存区大小
特有方法
public void newLine()换行,以\rMac\nLinux\r\nWindows这三种换行符进行分割。
转换流
字符编码和字符集
字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。编码:按照某种规则,将字符存储到计算机中。解码:反之,将存储在计算机中的二进制数按照某种规则解析显示出来。乱码:比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
编码:字符(能看懂的)–>字节(看不懂的)
解码:字节(看不懂的)–>字符(能看懂的)
字符编码Character Encoding : 就是一套自然语言的字符与二进制数之间的对应规则。编码表:生活中文字和计算机中二进制的对应规则
字符集
字符集 Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。
常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。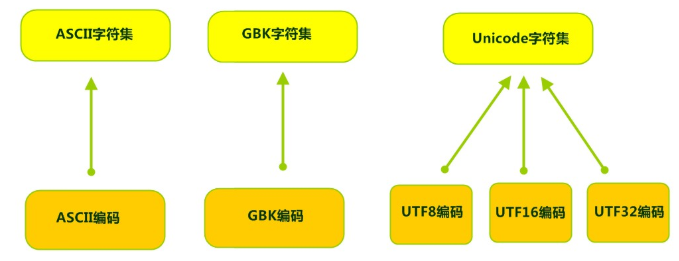
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
编码引出的问题
在IDEA中,使用FileReader 读取项目中的文本文件。由于IDEA的设置,都是默认的UTF-8编码,所以没有任何问题。
但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
下面来讲解如何使用转换流进行解决乱码问题。
转换流原理
转换流InputStreamReader和OutputStreamWriter
InputStreamReader和OutputStreamWriter就是可以转换字符集的字符输入,输出流。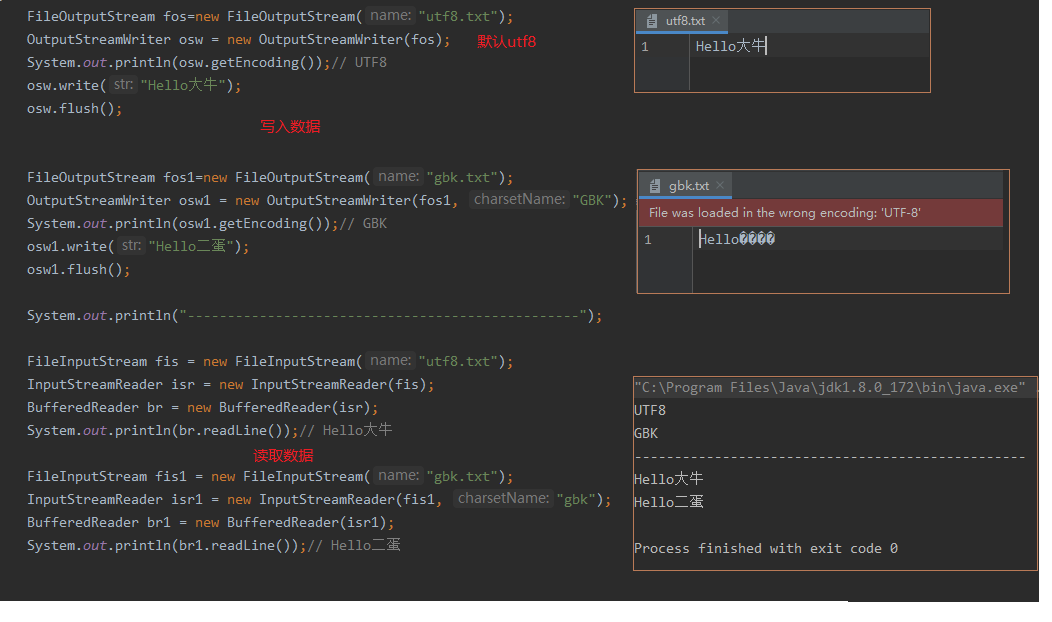
练习_转换文件编码
把一个BGK内容的文件,新建一份并编码设为UTF-8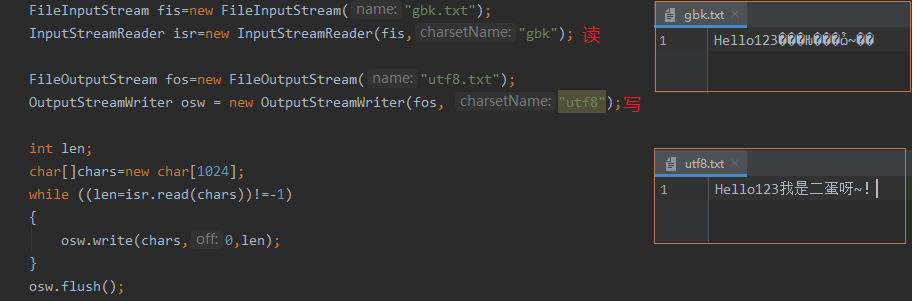
序列化流
对象存储到硬盘上,或是通过网络传输。
序列化与反序列化概述
ObjectInputStream和ObjectOutputStream
它们两个分别继承InputStream OutputStream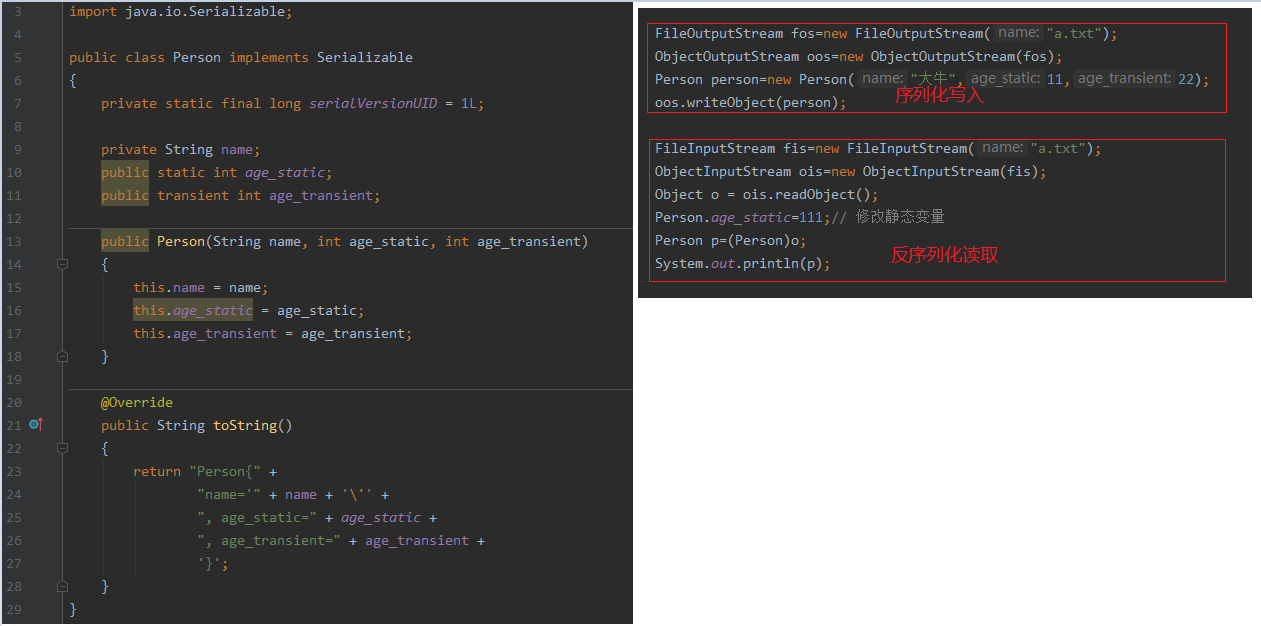
案例(原型模式)
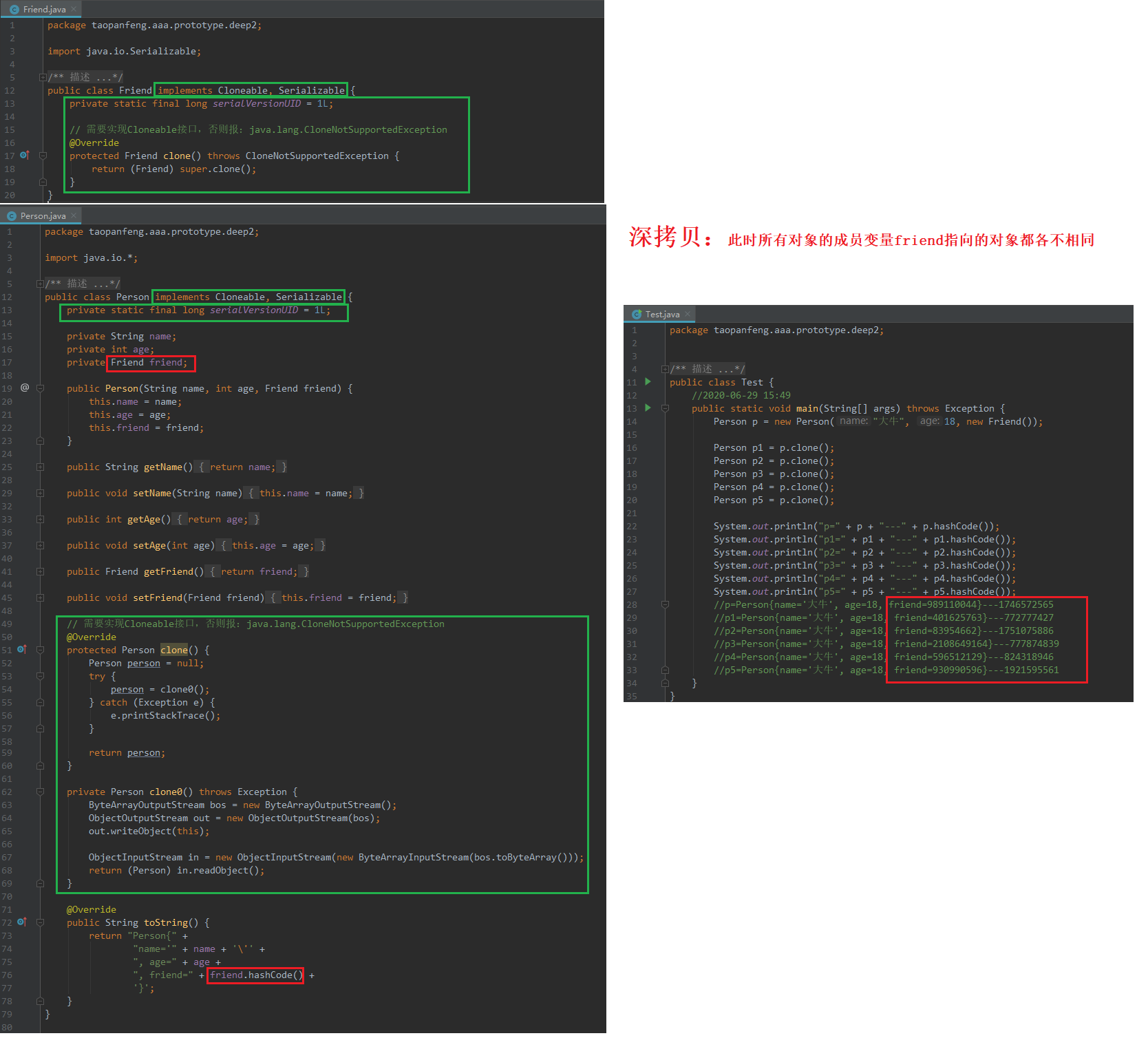
序列化冲突异常&解决方案
总结
- 要想序列化或反序列化,类必须实现
Serializable接口,否则产生异常java.io.NotSerializableException - 成员变量不被序列化可设置为
transient或static transient是单纯不能被序列化。static是方法区中静态区的存在,反序列化的对象也会去找静态区,所以是可变的。可参考static内存图- 序列化之后,类发生变化则会反序列化失败,产生异常
java.io.InvalidClassException。解决方法:给类加上成员变量static final long serialVersionUID = 1L;,值的大小随意。
标注输入输出流
InputStream
InputStream in = System.in;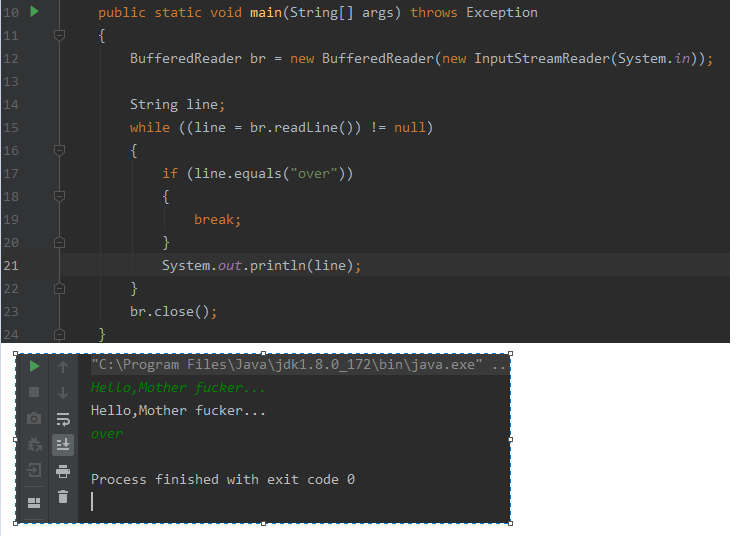
PrintStream
PrintStream out = System.out;PrintStream extends OutputStream继承字节输出流
构造方法
public PrintStream(String fileName)指定文件路径public PrintStream(File file)指定文件public PrintStream(OutputStream out)指定输出流对象public PrintStream(String fileName, String csn)指定文件路径,并设置字符集。默认utf8
继承自父类的成员方法
public void write(int b)一次写入一个字节public void write(byte[] b)一次写入多个字节public void write(byte[] b, int off, int len)从off开始,写入len个字节。public void flush()刷新数据到文件中。public void close()关闭资源,释放内存。
特有方法
void print(任意类型的值)void println(任意类型的值并换行)
注意:
如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表 97->a
如果使用自己特有的方法print/println方法写数据,写的数据原样输出 97->97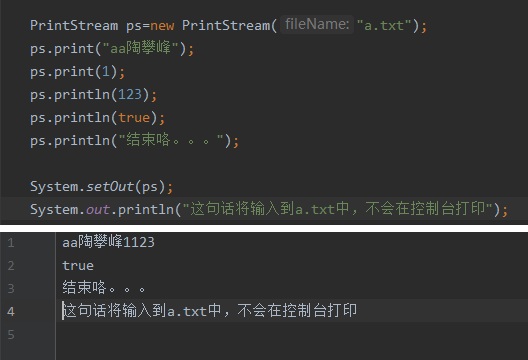
序列流
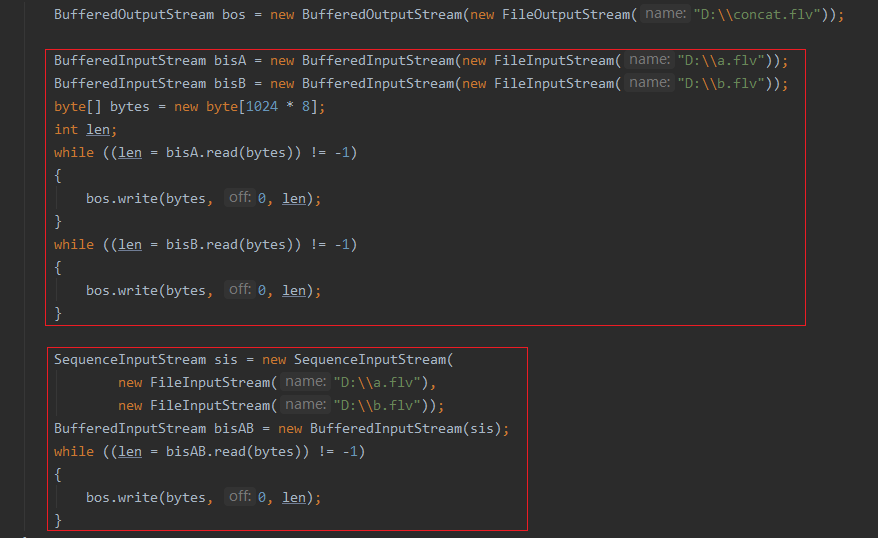
SequenceInputStream文件合并
- 把两个流合并到一个里面【注意:这里只是测试。但不能进行视频正常拼接。】
随机流
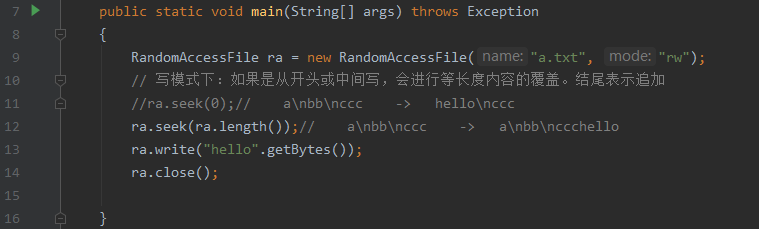
RandomAccessFile可读可写,可指定位置
- 读取

- 写入
- 文件分割
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public static void main(String[] args) throws Exception
{
RandomAccessFile raf = new RandomAccessFile(new File("a.txt"), "rw");
long len = raf.length();// 4891
int blockSize = 1024;// 1024*4=4096
int n = (int) Math.ceil(len * 1.0 / blockSize);// 5
for (int i = 0; i < n; i++)
{
byte[] bytes = new byte[blockSize];
String dir = "test";
new File(dir).mkdirs();
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(dir + "\\" + i + ".txt"));
raf.read(bytes);
if (i == n - 1)// 最后一块
{
blockSize = (int) (len - (long) blockSize * (n - 1));
}
bos.write(bytes, 0, blockSize);
bos.close();
}
}
Common-IO
添加依赖
1 | <dependency> |
使用
获取大小
1 |
|
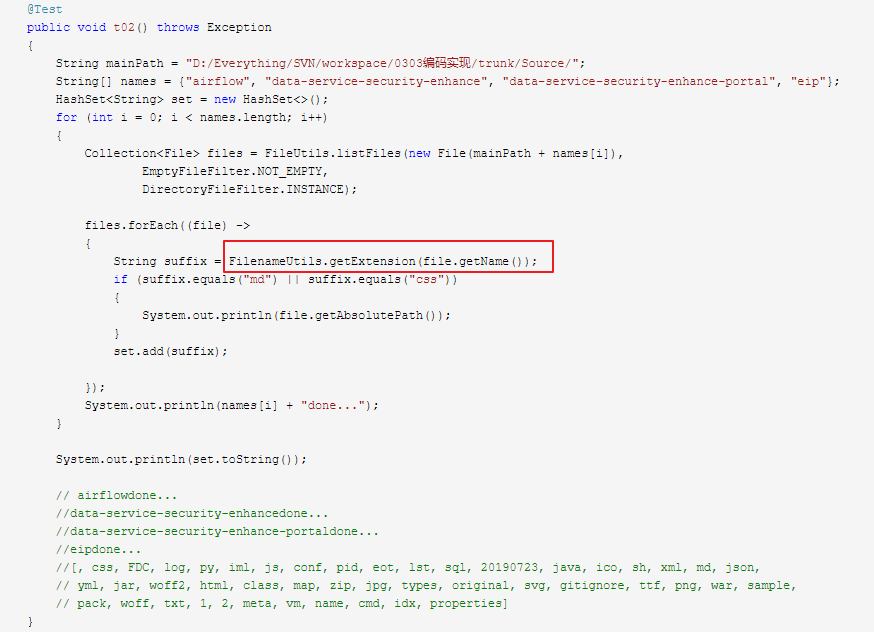
获取文件集合&过滤
1 | @Test |
数据读取
1 |
|
数据写入
1 |
|
拷贝&下载
其内部用的就是NIO的transform拷贝
1 | @Test |
获取后缀名
文件字符集
1 | public static String charset(String path) |