reactor,rxjava 都是实现了 reactive-streams 里的四个核心 API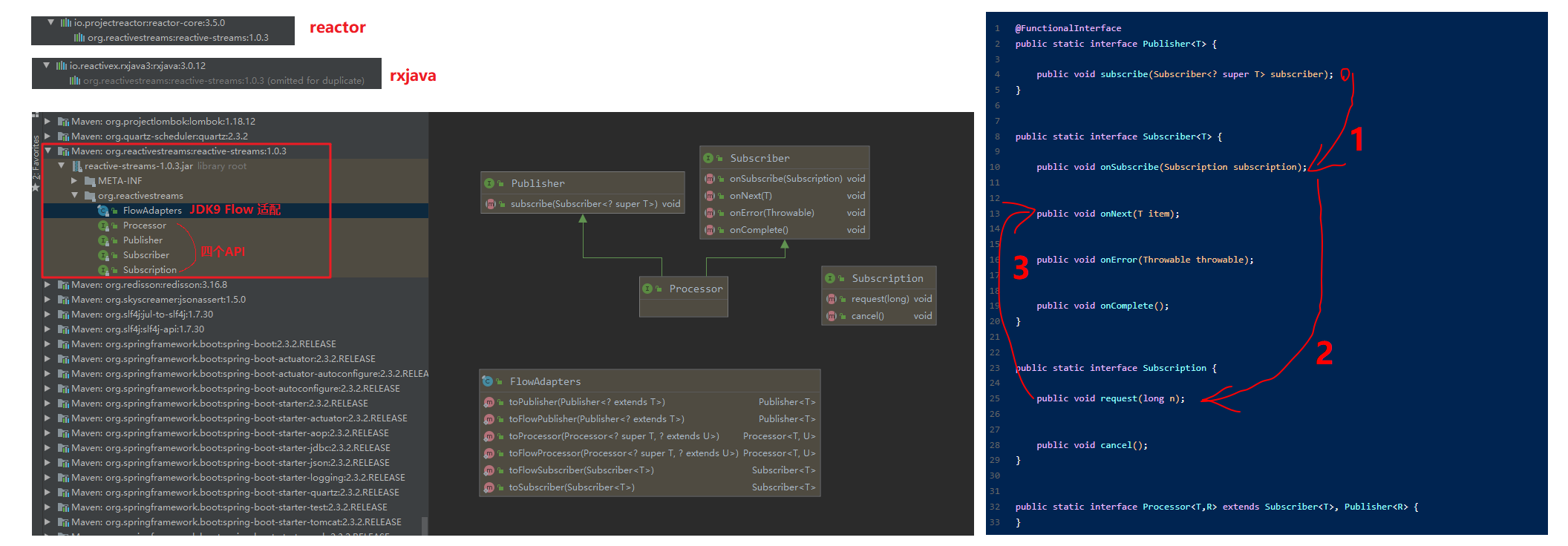
webflux 依赖 reactor-netty,进而依赖了 reactor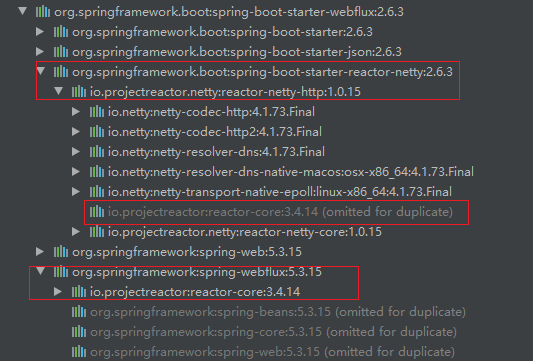
1 | 什么是响应式,就是基于响应的反应。 |
reactor 改进 rxjava create
1 | public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter, OverflowStrategy backpressure) { |
并发更新的安全性
1 | 有两种: |
reactor Flux.create
1 | public abstract class Flux<T> implements CorePublisher<T> { |
2022-12-20 16:53:21 我是真的看不下去了,
百度了一下,看过他书的人评论也很差劲,
但是找到了下面一篇文章,真的好。
—————
2022-12-20…18.53.05 知秋:响应式.txt
2018.9.10 响应式一些内容的分享总结
响应式到底是什么?
现实生活中,当我们听到有人喊我们的时候,我们会对其进行响应,也就是说,我们是基于事件驱动模式来进行的编程。
所以这个过程其实就是对于所产生事件的下发,我们的消费者对其进行的一系列的消费。
从这个角度,我们可以思考,整个代码的设计我们应该是针对于消费者来讲的,
=> 比如看电影,有些画面我们不想看,那就闭上眼睛,有些声音不想听,那就捂上耳朵,
=> 说白了,就是对于消费者的增强包装,我们将这些复杂的逻辑给其拆分,然后分割成一个个的小任务进行封装,于是就有了诸如filter、map、skip、limit等操作。而对于其中源码的设计逻辑,见下文。
并发与并行的关系
可以这么说,并发很好的利用了CPU时间片的特性,也就是操作系统选择并运行一个任务,接着在下一个时间片会运行另一个任务,并把前一个任务设置成等待状态。
其实这里想表达的是并发并不意味着并行。
具体来举几个情况:
有时候多线程执行会提高应用程序的性能,而有时候反而会降低程序的性能。这在关于JDK中其Stream API的使用上体现的很明显,如果任务量很小,而我们又使用了并行流,反而降低了性能。
我们在多线程编程中可能会同时开启或者关闭多个线程,这会产生的很多性能开销,这也降低了程序性能。
当我们的线程同时都在等待IO过程,此时并发也就可能会阻塞CPU资源,其造成的后果不仅仅是用户在等待结果,同时会浪费CPU的计算资源。
如果几个线程共享了一个数据,情况就变得有些复杂了,我们需要考虑数据在各个线程中状态的一致性。为了达到这个目的,我们很可能会使用Synchronized或者是lock来解决。
现在,应该对并发有一定的认知了吧。并发是一个很好的东西,但并不一定会实现并行。并行是在多个CPU核心上的同一时间运行多个任务或者一个任务分为多块执行(如ForkJoin)。单核CPU的话就不要考虑了。
补充一点,实际上多线程就意味着并发,但是并行只发生在当这些线程在同一时间调度分配在不同CPU上执行。也就是说,并行是并发的一种特定的形式。往往我们一个任务里会产生很多元素,然而这些个元素在不做操作的情况下大都只能在当前线程中操作,要么我们就要对其进行ForkJoin,但这些对于我们很多程序员来讲有时候很不好操作控制,上手难度有些高,响应式的话,我们可以简单的通过其调度API就可以轻松做到事件元素的下发分配,其内部将每个元素包装成一个任务提交到线程池中,我们可以根据是否是计算型任务还是IO类型的任务来选择相应的线程池。
这里,需要强调一下:线程只是一个对象而已,不要把其想象成cpu中的某一个执行核心,这是很多人都在犯的错,cpu时间片切换执行这些个线程。
响应式中的背压到底是一种怎样的理解
用一个不算很恰当的中国的成语来讲,就是承上启下。
为了更好的解释,我们来看一个场景,大坝,在洪水时期,下游没有办法一下子消耗那么多水,大坝在此的作用就是拦截洪水,并根据下游的消耗情况酌情排放。
再者,父亲的背,我们小时候,社会上很多的事情首先由父亲用自己的背来帮我们来扛起,然后根据我们自身的能力来适当的下发给我们压力,
也就是说,背压应该写在连接元素生产者和消费者的一个地方,即生产者和消费者的连线者。
然后,通过这里的描述,背压应该具有承载元素的能力,也就是其必须是一个容器的,而且元素的存储与下发应该具有先后的,那么使用队列则是最适合不过了。
1 | 背压,电影的缓冲就是背压 |
reactive-streams
- reactor,rxjava 都是实现了 reactive-streams 里的四个核心 API
- webflux 依赖 reactor-netty,进而依赖了 reactor
如何去看Rxjava或者Reactor的源码
如何去看Rxjava或者Reactor的源码,根据源码的接口的设计我们可以得到一些什么启示
关于响应式的Rx标准已经写入了JDK中:java.util.concurrent.Flow
1 |
|
可以看到,Flow这个类中包含了这4个接口定义,Publisher 通过subscribe方法来和Subscriber产生订阅关系,而Subscriber依靠onSubscribe来首先和上游产生联系,这里就是靠Subscription来做到的,所以说,Subscription往往会作为生产者的内部类定义其中,其用来接收生产者所生产的元素,支持背压的话,Subscription应该首先将其放入到一个队列中,然后根据请求数量来调用Subscriber的onNext等方法进行下发。
这个在Rx编程中都是统一的模式,我们通过Reactor中reactor.core.publisher.Flux#fromArray所涉及的FluxArray的源码来对此段内容进行理解:
1 | final class FluxArray<T> extends Flux<T> implements Fuseable, Scannable { |
各种中间操作的包装我们该如何去做,依据之前的接口定义,我们应该更注重功能的设定,而无论是filter,flatmap,map等这些常用的操作,其实都是消费动作,理应定义在消费者层面,想到这里,我们该如何去做?
这里,我们就要结合我们的设计模式,装饰模式,对subscribe(Subscriber<? super T> subscriber)所传入的Subscriber进行功能增强,即从Subscriber这个角度来讲,使用的是装饰增强模式,但从外面来看,其整体定义的依然是一个Flux或者Mono,这里FluxArray的话就是例子,这样,从这个角度来讲,其属于向上适配,也就是适配模式,这里的适配玩的比较有意思,完全就是靠对内部类的包装然后通过subscribe(Subscriber<? super T> subscriber)衔接来完成的。
所以,我们应该想到中国古代苏轼的题西林壁里有一句话:横看成岭侧成峰 远近高低各不同 讲的就是从不同的角度去看待一个事物,就会得到不同的结果。同样,一百个人心中有一百个哈姆雷特,也是对于同一个事物的看法,从这里,我们应该能学到设计模式千万不要特别刻意的去绝对化!
我们可以结合reactor.core.publisher.Flux#filter涉及的FluxFilter来观察理解上述涉及的内容:
1 | final class FluxFilter<T> extends FluxOperator<T, T> { |
根据这些设计,我们自己也是完全可以作为参考来通过一套api接口设计,可以衍生出很多规范逻辑的开发,比如我们看到的众多的Rx衍生操作API的设计实现,其都是按照一套模板来进行的,我们可以称之为代码层面的微服务设计。
如何去看待众多函数表达式
人类最擅长描述场景,比如一套动作,假如是舞蹈的话,可以讲是什么什么编舞,但是这个编舞又要在一定的框架之下,即有一定的规范,同样,我们施展一套拳法,也需要一个规范,不能踢一脚也叫拳法。而对于这个规范的实现,那就是一套动作,对于拳法来讲,可能就是一个很简单的左勾拳或者右勾拳,也可以是比较复杂的咏春拳,太极拳等,而且一套拳法可能有很多小套路组成,这些小套路也是遵循着这个规范进行的,那么依据这个思路,我们来看下面的函数式接口定义:
1 |
|
可以看到无论是条件判断表达式Predicate还是无返回值动作处理函数BiConsumer都遵循一个标准动作的设计定义思路,并通过default方法来对同类动作进行编排,以达到更加丰富的效果。所以,函数式的应用更加倾向于干净利落,凸显自己要做的事情就好,未来,我会在自己的Java编程方法论- JDK篇中花大量篇幅来解读函数式编程的各种奇特而实用的使用方法,来降低我们复杂接口的设计逻辑难度,做到知名见义,了然于胸的效果。这个在我的Java编程方法论- Reactor与Spring webflux篇中也是有涉及的。
关于响应式的使用性能的考究
响应式编程知识一种模式,用的好与坏全看自己对于api的理解程度,不要想着会多么的降低性能,这个并没有进行什么过度包装这一说的,当讲到jdbc这里如何表现不行的时候,当前并没有一个开源的Reactor-jdbc的框架,也就造成的测试的不合理性,何况新的知识是需要大家一起共同来学习推动的,不好的地方我们推动就好,不需要上来就对其进行否定,mongodb有提供相应的响应式api,但其内部还是之前的方式,同样,关系型数据库也是一个道理,响应式编程注重的是中间过程的处理,关于生产元素的获取它没太多关系,更多的还是看元素生产者的性能,一家之言,可能有偏颇,希望理解,有问题提出就好。
———–
1 | 反应式系统的特质: |
反应式宣言 (Simplified Chinese)
https://www.reactivemanifesto.org/zh-CN
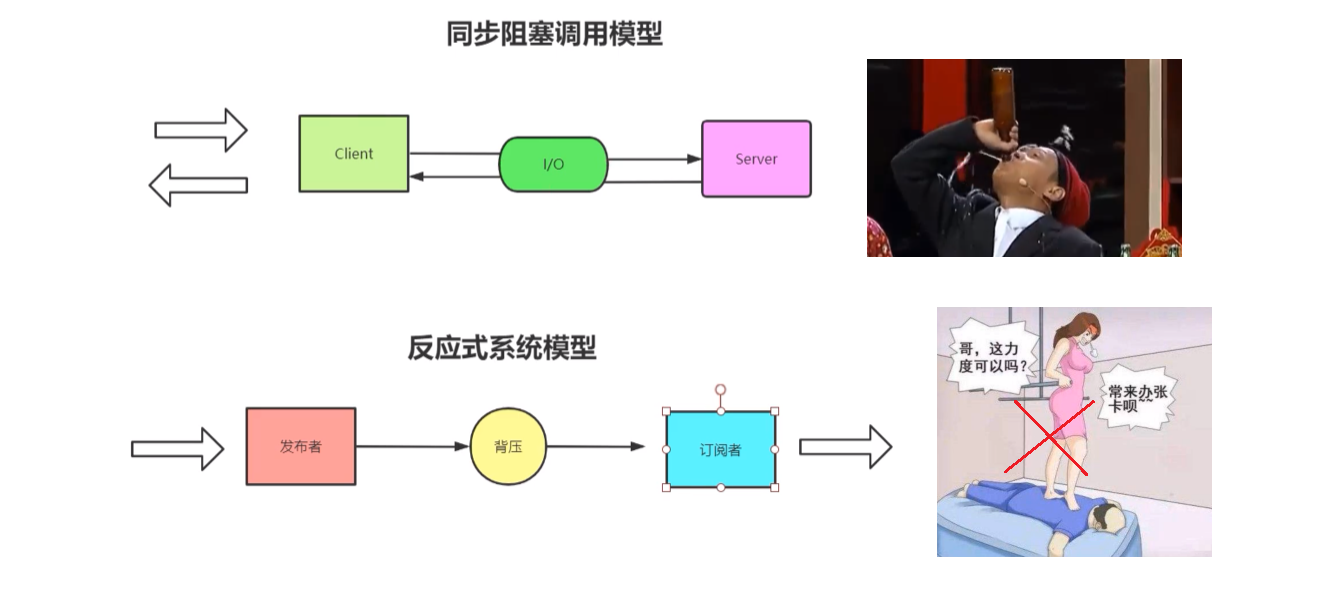
1 | 同步阻塞,喝酒吹瓶,一口喝不下会喷出来。 |
- 同步阻塞调用模型、反应式系统模型
Spring reactive
https://spring.io/reactive
Reactive VS Servlet

背压缓冲、Reactive Stream组件模型
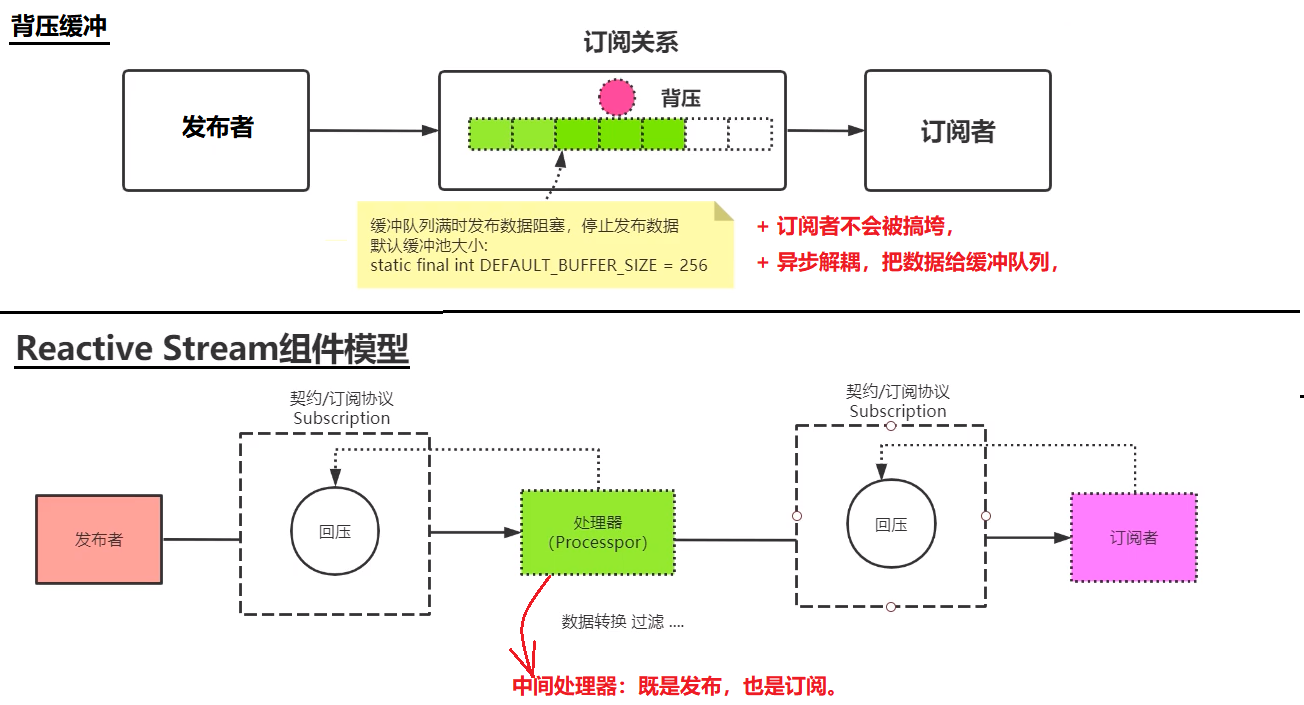
JDK9 Flow
1 | 发布者,订阅者,建立关系 |