高并发系统的认知
1 | # 一、什么是高并发系统 |
搭建生产级系统
1 | # 三、生产级系统框架设计细节 |
- 正向代理、反向代理
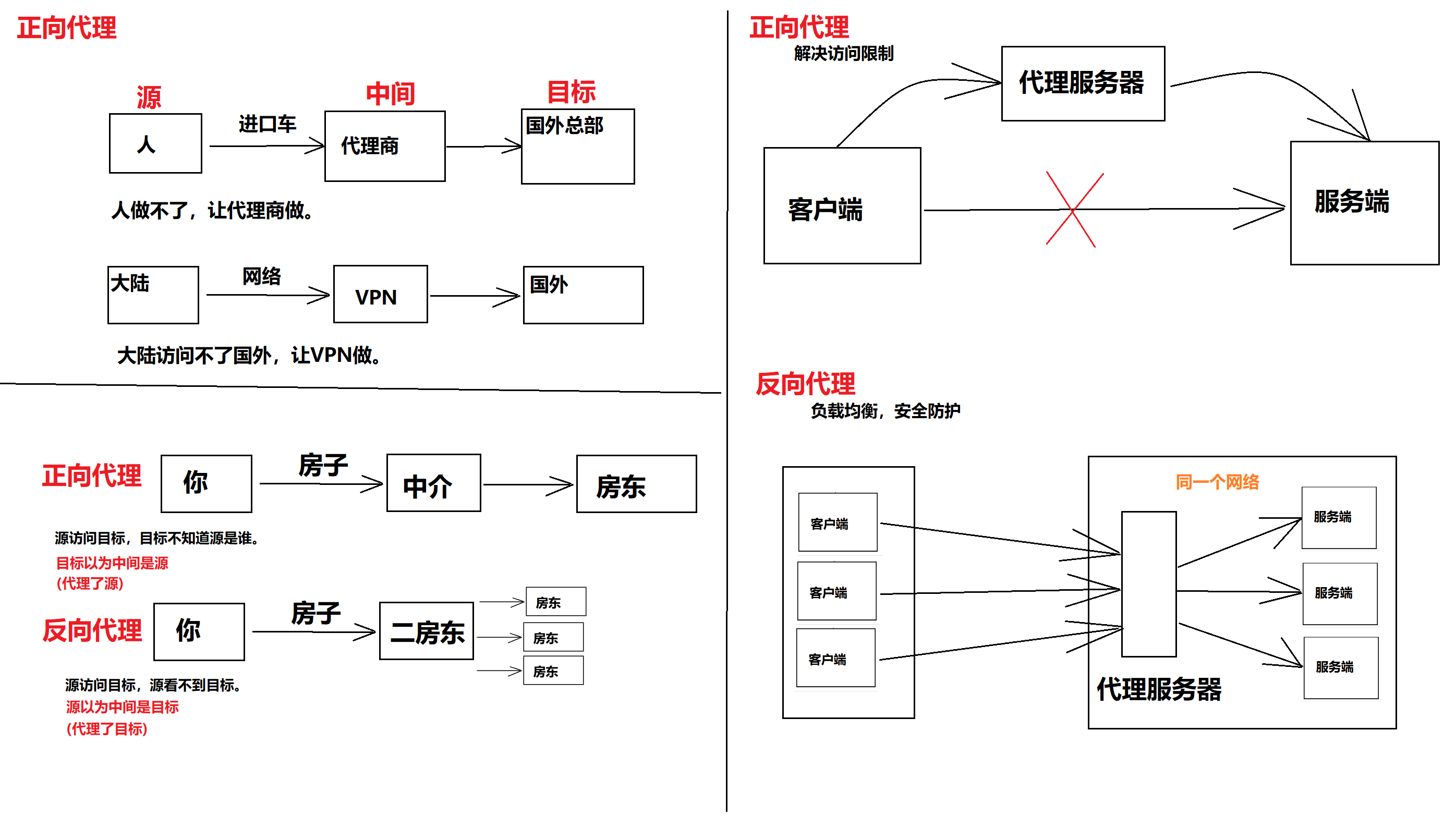
生产环境监测
1 | # 五、生产环境监测 |
- TOP命令,CPU 飙高,CPU架构,进程上下文
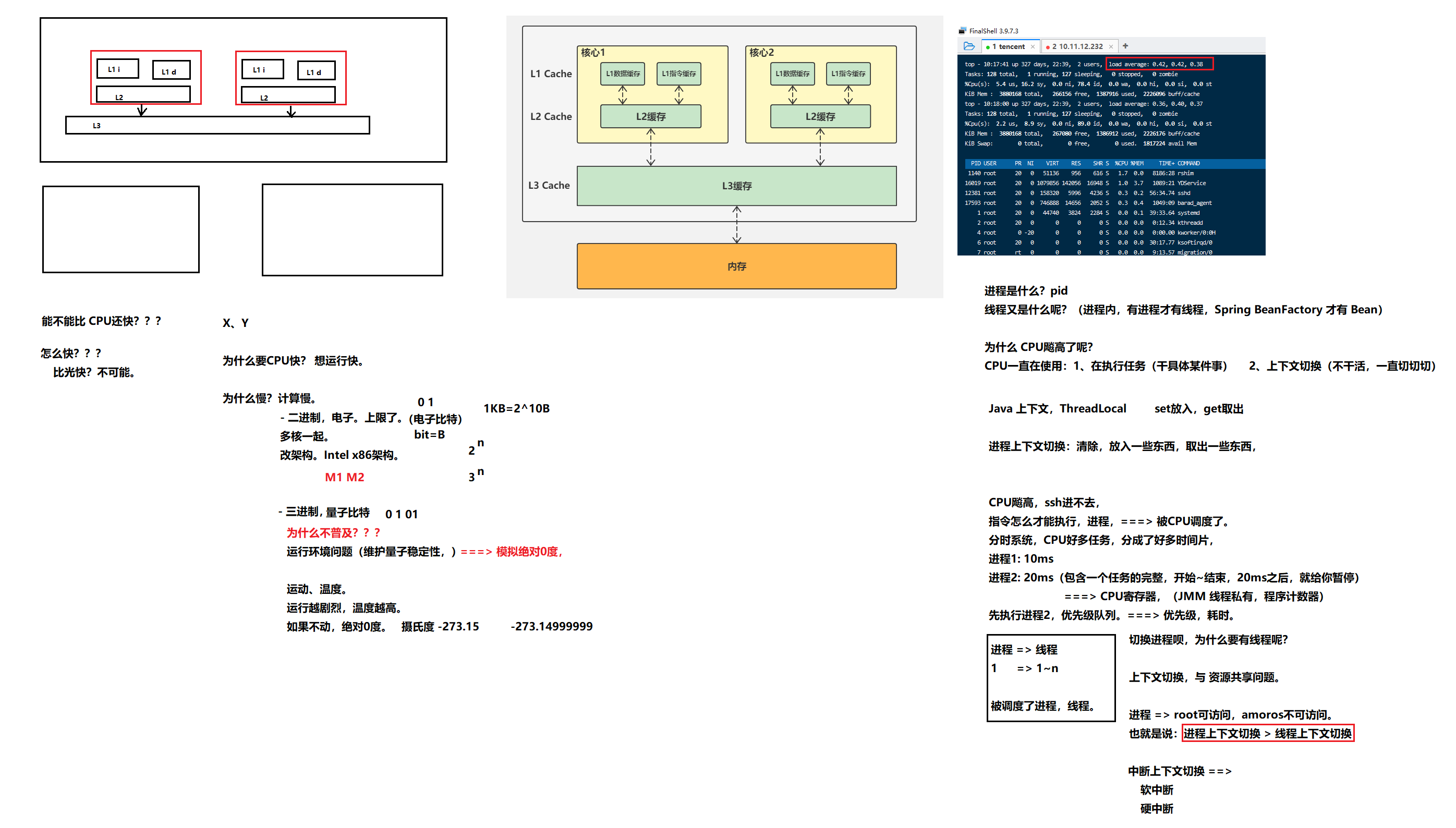
应用集群化
1 | # 六、应用集群化 |
- 单机架构、集群架构、分布式架构
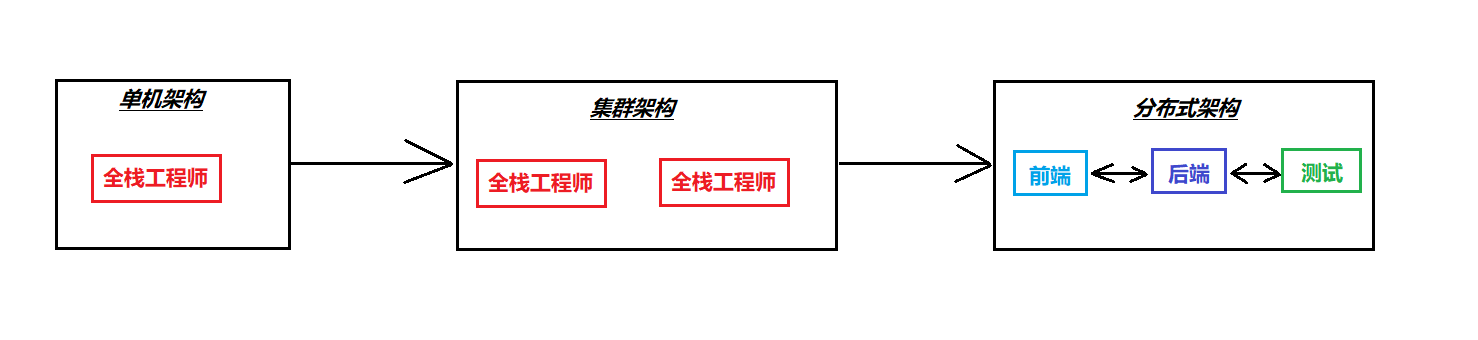
167页
【日期标记】2022-11-23 07:49:26 以上同步完成
缓存设计
1 | # 七、缓存设计 |
182页
1 | 8. 缓存组件的选择 |
- Redis 主进程中的四个线程
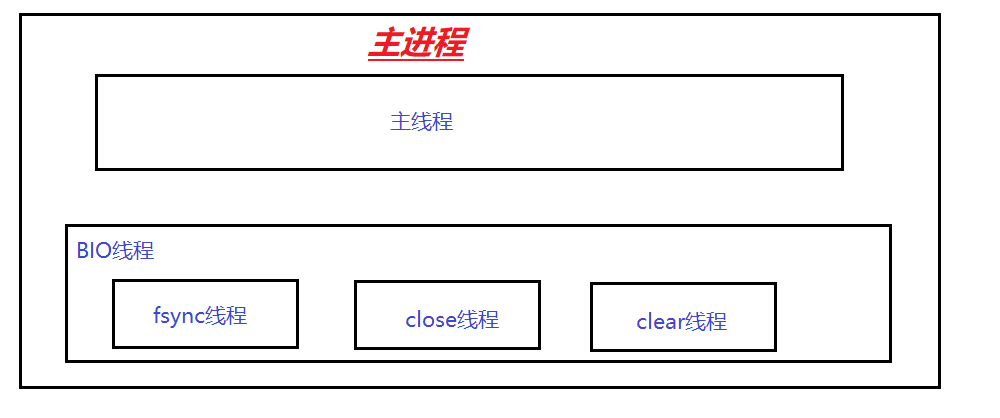
187页
【日期标记】2022-11-23 09:51:43 以上同步完成
1 | 9. 缓存分布的设计 |
- 取模算法、一致性hash算法

1 | 10. Redis主从:读写分离 |
关于主从复制、读写分离,之前也有提到过。参考这里:主从复制,读写分离
- Redis 读写分离、主从复制

1 | 11. 缓存雪崩 |
- 缓存雪崩

1 | 12. 缓存穿透 |
- 缓存穿透

1 | 13. Redis集群 |
- Redis集群

1 | 14. 实战:朋友圈点赞、查找附近的人 |
- 朋友圈点赞、查找附近的人

212页
【日期标记】2022-11-24 09:36:51 以上同步完成(未整理)
【日期标记】2022-11-25 10:20:53 以上同步完成
(因为之前有看过《Redis设计与实现》,在读这一块可以很快,但是我还是慢慢理解了一下里面不一样的点,比如:GEO二维变一位 52位整数。MOVED 不同处理 Dummy客户端,Smart客户端。…等)
(读到这里,我确定的认为,这是一本好书,讲的不晦涩,也很深入一点,还讲到了一些实操,以及实际会遇到的问题点,还有对比总结和分析,)
第八章:存储系统设计
1 | 1. 池化技术 |
- 协程:应用程序创建

1 | 主从复制:基于Binlog来同步,进行数据重放 |
- MySQL数据库 主从复制

- 读写分离、数据不一致(主从延迟)

1 | 分库分表 |
- 数据库 分库分表

239页
【日期标记】2022-11-30 09:39:33 以上同步完成(未整理)
【日期标记】2022-12-02 11:04:27 以上同步完成
第九章:搜索引擎
1 | 倒排索引 |
256页
【日期标记】2022-12-01 09:02:20 以上同步完成
第十章:消息中间件
1 | 消息幂等 |
- RocketMQ 架构原理

281页
【日期标记】2022-12-02 08:21:12 以上同步完成
第十一章:微服务系统拆分
299页(不打算记录)
第十二章:API网关
1 | zuul => servlet 阻塞式I/O |
315页
第十三章:高并发设计
1 | 高并发通用设计 |
- 高并发设计
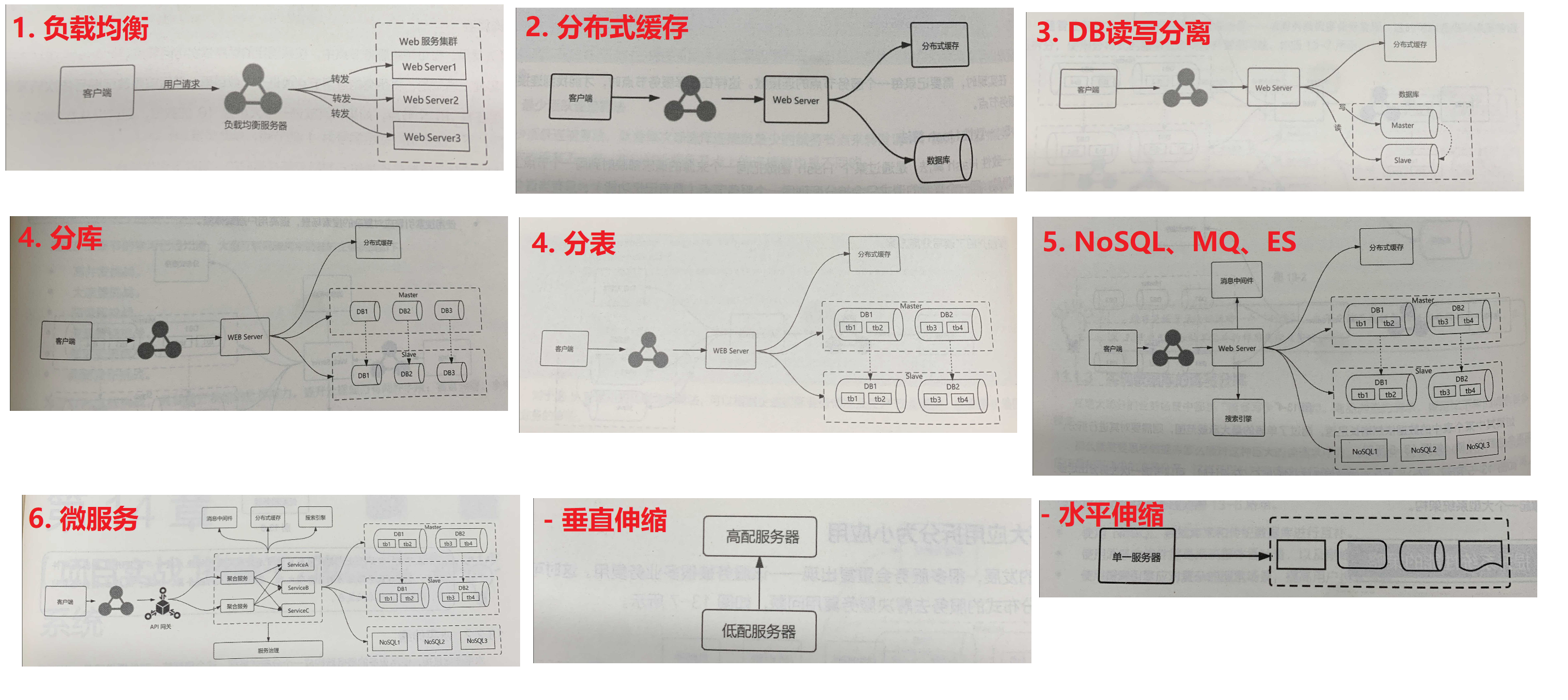
326页
1 | 这四章,看的贼快,感觉没太大用途! |
