购买链接
在线阅读 https://icyfenix.cn/
实在太多了,只能开辟新篇。
分布式共识算法
前置知识
关于分布式中 CAP 问题,请先阅读“分布式事务”中的介绍,后文中提及的一致性、可用性、网络分区等概念,均有过介绍。
1 | # 工业界 -> 学术界 |
Paxos
分布式共识算法
世界上只有一种共识协议,就是 Paxos,其他所有共识算法都是 Paxos 的退化版本。
—— Mike Burrows,Inventor of Google Chubby
1 | # Paxos => 一种基于消息传递的协商共识算法 |
Paxos 的诞生
1 | # 希腊城邦 => 民主制 |
算法流程
1 | 讲完段子吃过西瓜,希望你没有被这些对 Paxos 的“困难”做的铺垫所吓倒,反正又不让你马上去实现它。 |

工作实例

有人读到这里可能又懵了,别急,别急!上栗子,上栗子!!!
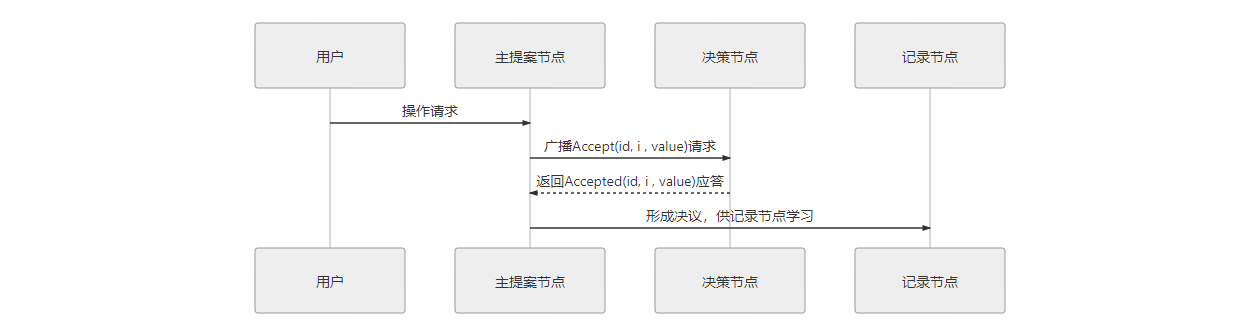
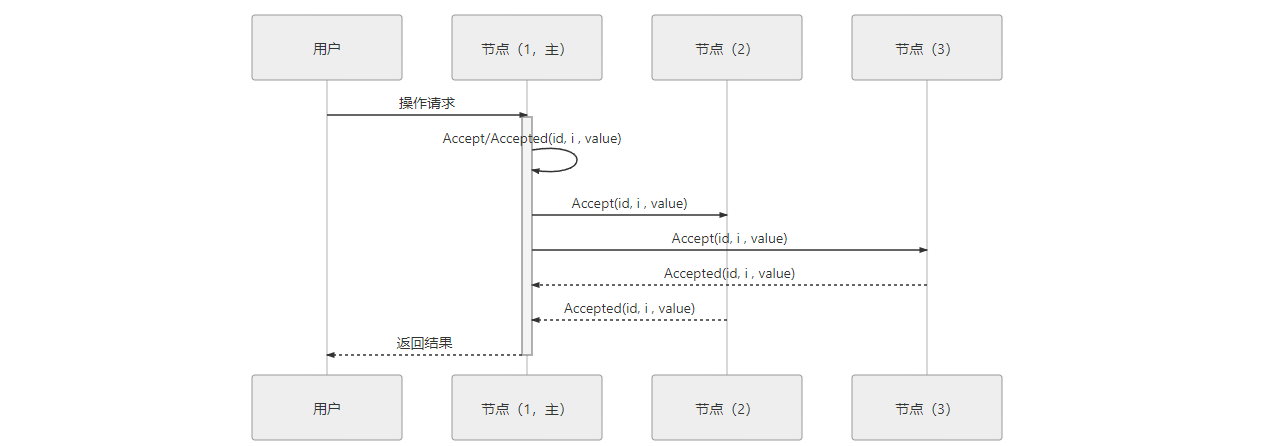
假设一个分布式系统有五个节点,分别命名为 S1、S2、S3、S4、S5,这个例子中只讨论正常通信的场景,不涉及网络分区。全部节点都同时扮演着提案节点和决策节点的身份。此时,有两个并发的请求分别希望将同一个值分别设定为 X(由 S1作为提案节点提出)和 Y(由 S5作为提案节点提出),以 P 代表准备阶段,以 A 代表批准阶段,这时候可能发生以下情况:
情况一 => 正常情况:过半Promise应答 和 过半Accepted应答
例如,S1选定的提案ID 是 3.1(全局唯一且自增ID+节点编号),先取得了过半决策节点的 Promise 和 Accepted 应答;此时 S5选定提案ID 是 4.5,发起 Prepare 请求,收到的过半应答中至少会包含 1 个此前应答过 S1的决策节点,假设是 S3,那么 S3提供的 Promise 中必将包含 S1已设定好的值 X,S5就必须无条件地用 X 代替 Y 作为自己提案的值,由此整个系统对“取值为 X”这个事实达成一致,如下图所示。
1 | # 再次解释 |
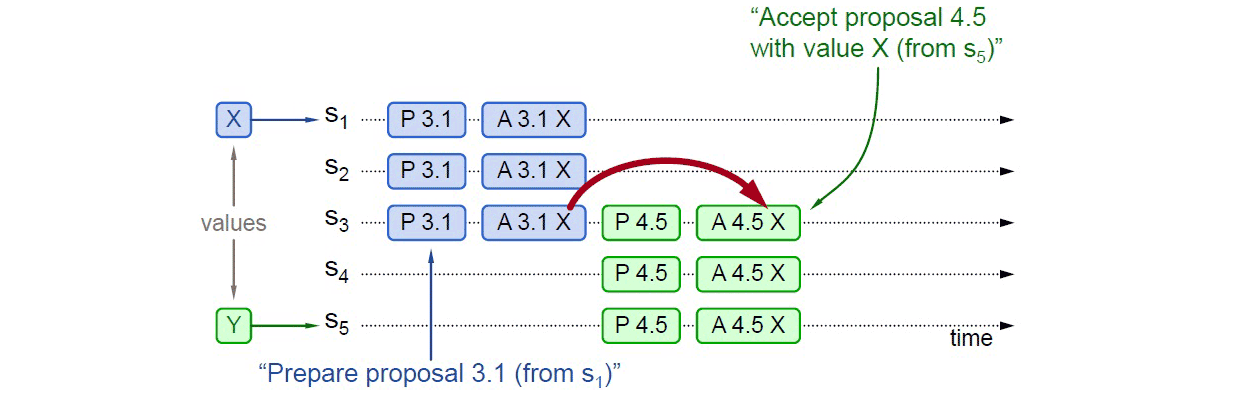
情况二 => 已处理过 Accept请求
事实上,对于情况一,X 被选定为最终值是必然结果,但从情况一的图中可以看出,X 被选定为最终值不是需要过半的共同批准,而是取决于 S5提案时 Promise 应答中是否已包含了批准过 X 的决策节点;如下图所示,S5发起提案的 Prepare 请求时,X 并未获得过半批准,但由于 S3已经批准的关系,最终共识的结果仍然是 X。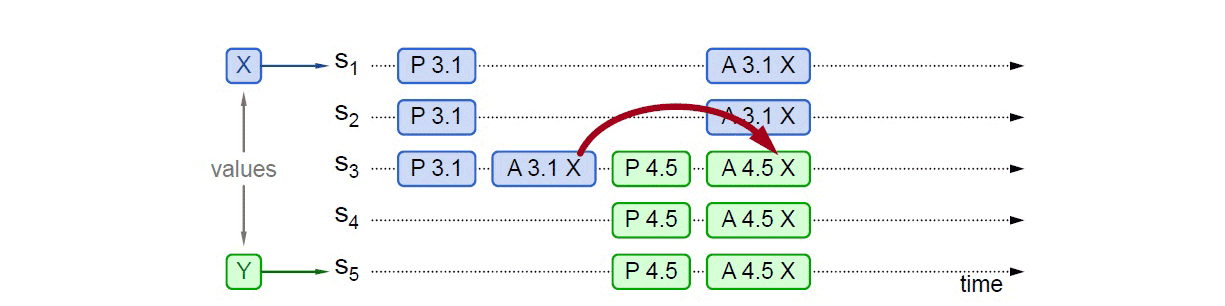
情况三 => 忽略 Accept请求(提案ID小于当前)
当然,另外一种可能的结果是 S5提案时 Promise 应答中并未包含批准过 X 的决策节点,例如应答 S5提案时,节点 S1已经批准了 X,节点 S2、S3未批准但返回了 Promise 应答,此时 S5以更大的提案ID 获得了 S3、S4、S5的 Promise,这三个节点均未批准过任何值,那么 S3将不会再接收来自 S1的 Accept 请求(因为它的提案ID 已经不是最大的了),这三个节点将批准 Y 的取值,整个系统最终会对“取值为 Y”达成一致,如下图所示。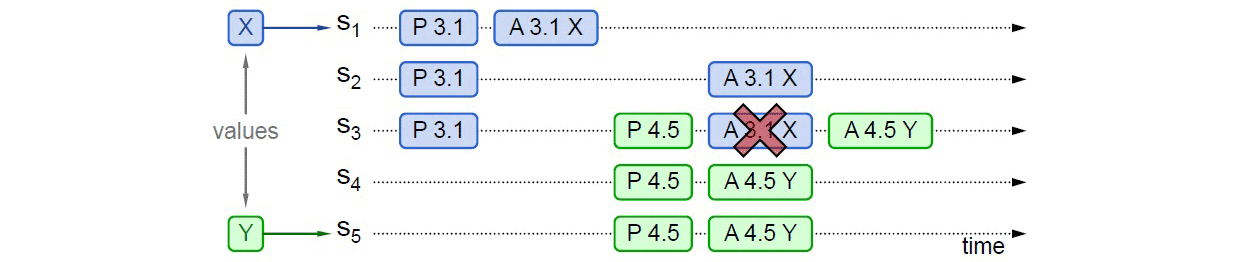
情况四 => 活锁(Accepted应答一直未过半,不会结束共识)
从情况三可以推导出另一种极端的情况,如果两个提案节点交替使用更大的提案ID 使得准备阶段成功,但是批准阶段失败的话,这个过程理论上可以无限持续下去,形成活锁(Live Lock),如下图所示。=> 在算法实现中会引入随机超时时间来避免活锁的产生。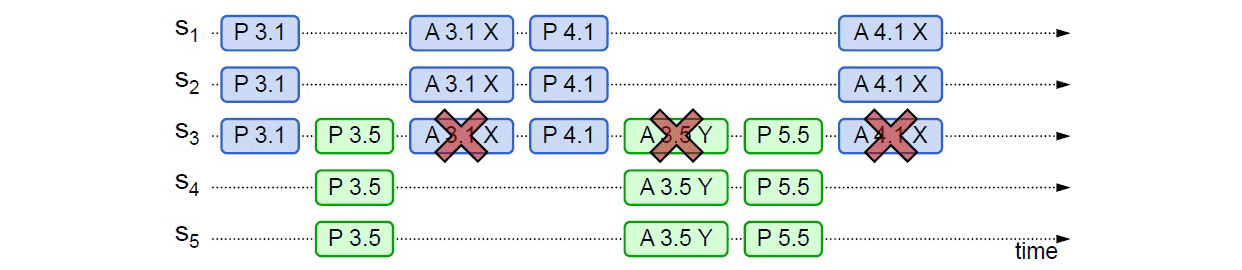
1 | # Basic Paxos => 坏处:单个值决议,两次网络请求和应答(准备和批准阶段各一次),极端会活锁 |
【日期标记】2022-08-17 15:15:34 以上同步完成
Multi Paxos
选主:Raft、ZAB
1 | # Basic Paxos改进版 => Multi Paxos(仅主节点提案) |
1 | # 二元组 => 三元组(任期:单调递增,用于解决多主问题) |
1 | # 一致性 => 三个子问题 |
Gossip 协议
1 | # Gossip 协议 |
1 | # Gossip 优点 |
【日期标记】2022-08-17 16:51:04 以上同步完成
从类库到服务
通过服务来实现组件
微服务架构也会使用到类库,但构成软件系统组件的主要方式是将其拆分为一个个服务。
—— Martin Fowler / James Lewis, Microservices, 2014
1 | # 微服务设计原则:通过服务来实现独立自治的组件 |
服务发现
1 | # 类库 |
服务发现的意义
1 | # 三元组定位服务:全限定名,端口号,服务标识 |
可用与可靠
1 | # 服务发现三个过程:注册,鸡掰(剔除),服务名(坐标) |

1 | # 服务发现+配置中心 |
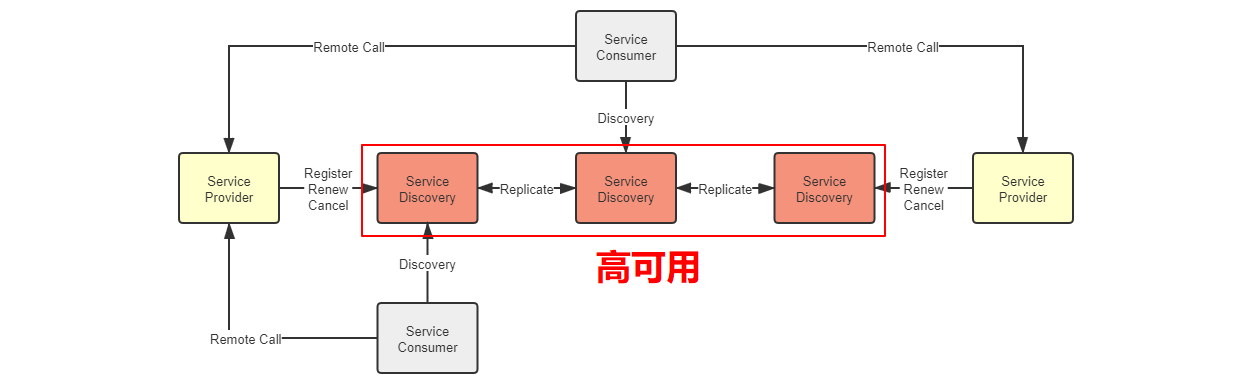
1 | # CAP问题 |
注册中心实现
1 | # 权衡 => 先选ap/cp,其次才是性能/功能/方便 |
网关路由
1 | # 嘛叫“网关” => 内部的边缘,与外部交互 |
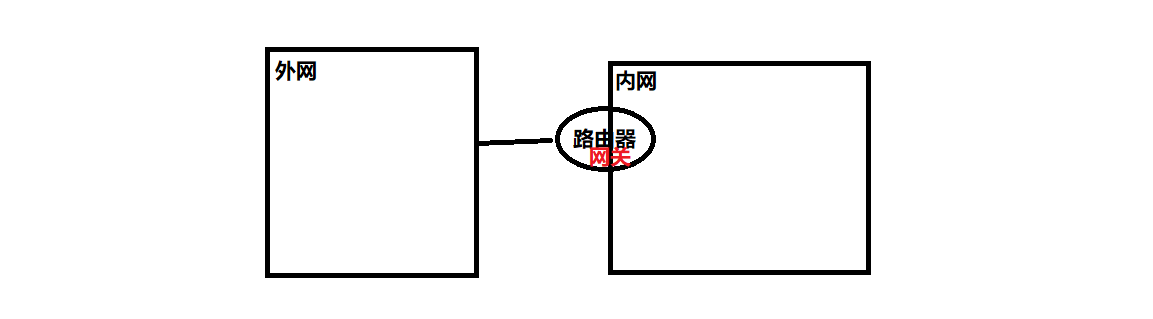
网关的职责
1 | # Gateway |
网络 I/O 模型
看这篇文章之前,可以先看看之前的一篇:I/O 模型
1 | # 网络I/O => Socket读写 |
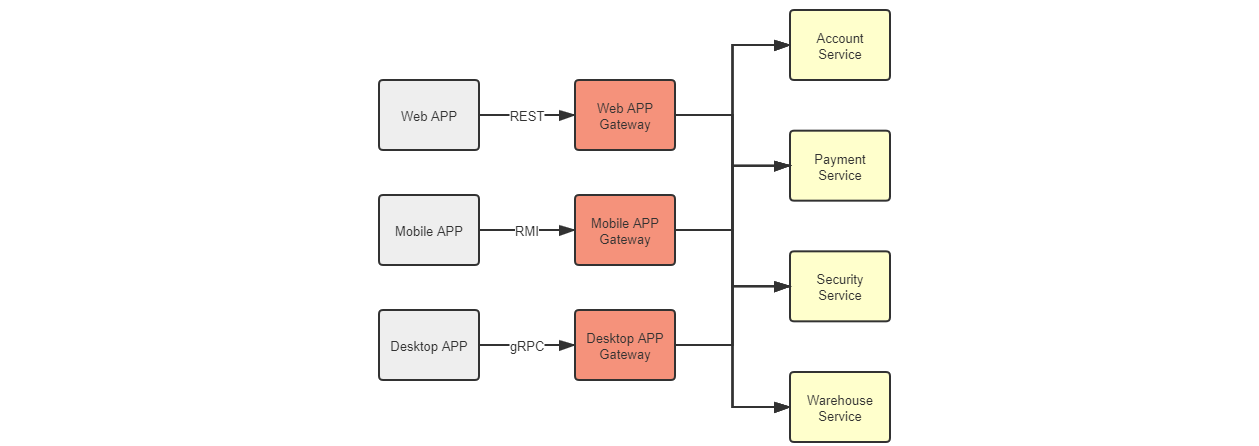
BFF 网关
1 | 提到网关的唯一性、高可用与扩展,例如顺带也说一下近年来随着微服务一起火起来的概念“BFF”(Backends for Frontends)。【哈哈哈,迪卡侬】 |
客户端负载均衡
LB
前置知识:可以先参考之前讲的 “负载均衡”。
1 | # LB => “从服务集群中寻找到一个合适的服务来调用” |
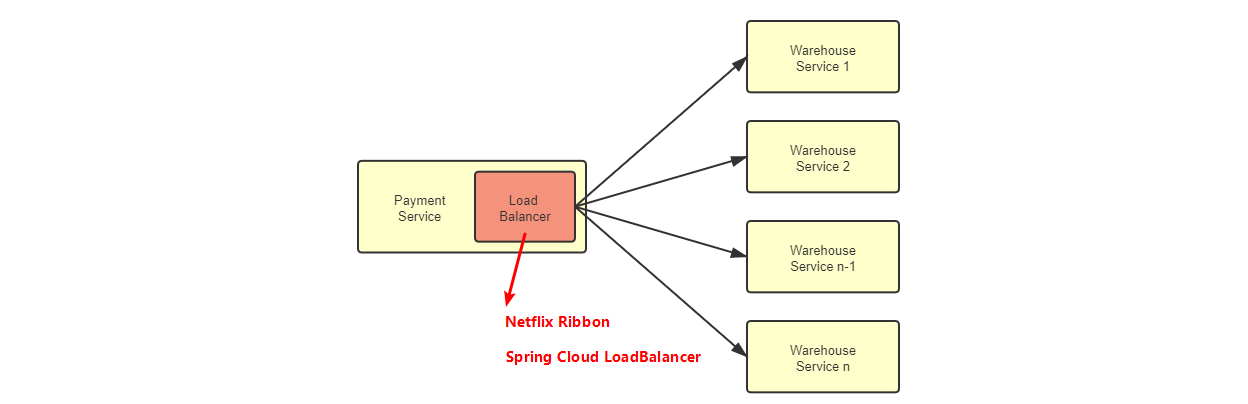
客户端负载均衡器
Netflix Ribbon
Spring Cloud Load Balancer
1 | 对于任何一个大型系统,负载均衡器都是必不可少的设施。 |
1 | # 好处 |
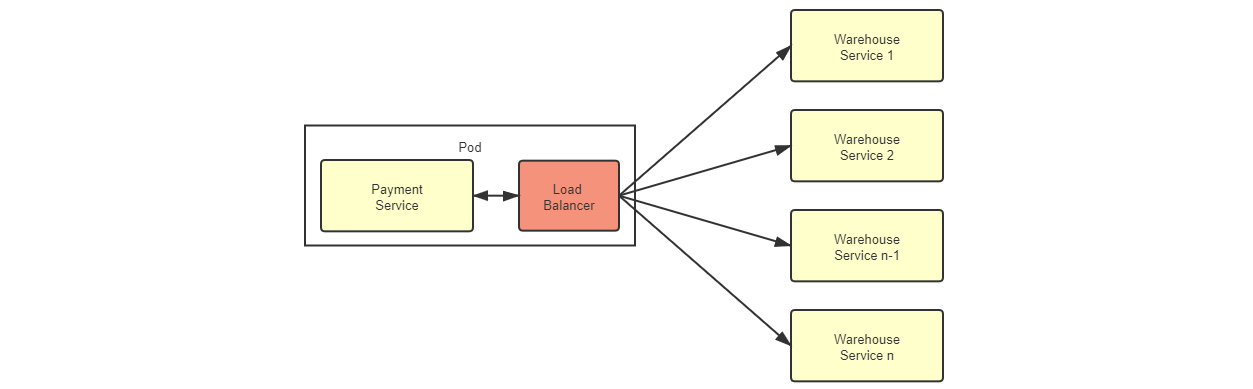
代理负载均衡器
Service Mesh 服务网格
1 | 在 Java 领域,客户端均衡器中最具代表性的产品是 Netflix Ribbon 和 Spring Cloud Load Balancer,随着微服务的流行,它们在 Java 微服务中已积聚了相当可观的使用者。 |
1 | # 不同进程 |
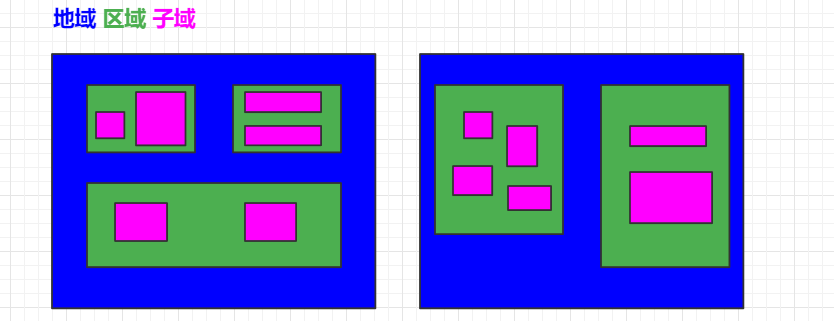
地域与区域
1 | 最后,借助前文已经铺设好的上下文场景,想再谈一个与负载均衡相关,但又不仅仅应用于负载均衡的概念:地域与区域。 |
流量治理
服务容错
容错策略
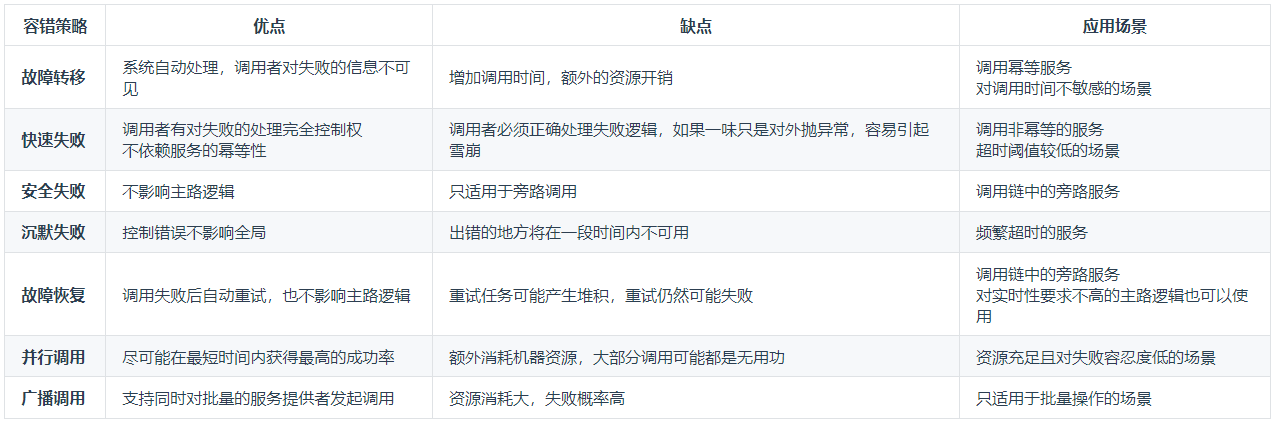
容错设计模式
1 | 1. 断路器模式 |
流量控制
流量统计指标
1 | 1. 每秒事务数(Transactions per Second,TPS):TPS 是衡量信息系统吞吐量的最终标准。 |
限流设计模式
1 | 1. 流量计数器模式 |
分布式限流
1 | # 例如:Redis限流 |
可靠通讯
服务安全
建立信任
1 | # 私密 × |
可观测性
1 | # 职责:记录离散事件 |

事件日志
1 | 日志用来记录系统运行期间发生过的离散事件。相信没有哪一个生产系统能够缺少日志功能,然而也很少人会把日志作为多么关键功能来看待。 |

输出
收集与缓冲
1 | Logstash Java 1G(负重) -> Filebeat Golang(轻) |
加工与聚合
1 | # 日志 -> 非结构化数据(需要做结构化处理) |
存储与查询
1 | # Elasticsearch 日志分析 -> 无可替代 |
链路追踪
追踪与跨度
1 | # 追踪 Trace、跨度 Span |
数据收集
1 | # 基于日志的追踪(Log-Based Tracing) |
聚合度量
1 | 度量(Metrics)的目的是揭示系统的总体运行状态。 |
指标收集
1 | # 推 push、拉 pull |
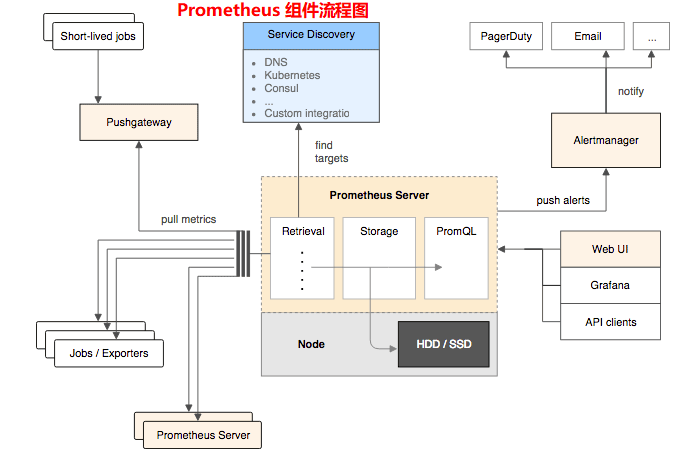
1 | 一般来说,度量系统只会支持其中一种指标采集方式,因为度量系统的网络连接数量,以及对应的线程或者协程数可能非常庞大,如何采集指标将直接影响到整个度量系统的架构设计。 |
存储查询
1 | # 关系型数据库 => 不适合度量 |
监控预警
1 | 指标度量是手段,最终目的是做分析和预警。 |
【日期标记】2022-08-18 19:00:01 以上同步完成