可先参读:
问题演进
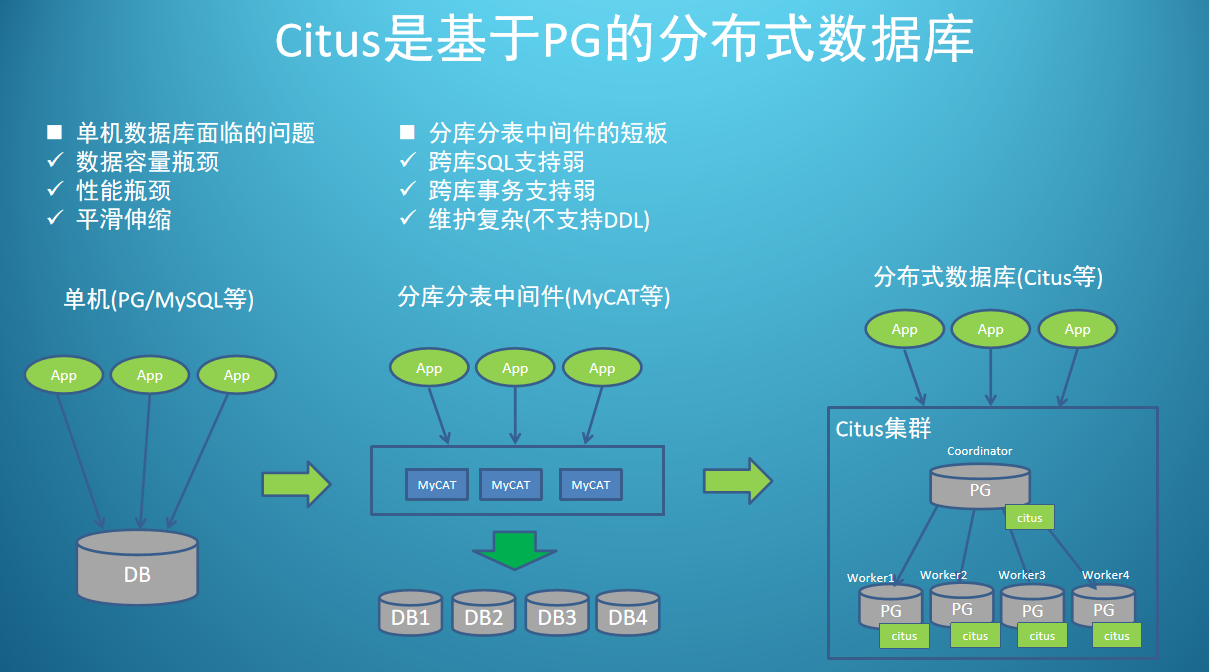
简单来讲:只适用于PG的分布式数据库,以插件的形式集成 PG。
单机
用的最熟悉最多的是单库:比如:MySQL、Postgresql等
业务量大的时候,单机会有瓶颈:数据容量瓶颈,或 性能瓶颈,而且单机扩容会比较麻烦。
分库分表
解析SQL,确定数据在哪一台节点上。把SQL分发到对应的实例上。
问题1:不适合跨库的SQL,有些可以支持但是比较弱,跨库的事务也是。
问题2:维护比较麻烦
分库分表的中间件给用户提供的是两套东西:一套是分库分表的中间件,一套是底下的各个分散的数据库(那么多于业务开发者来讲,他必须要维护这两套东西)。
假设我们要做表结构的变更:加个索引
这样的操作必须是先到数据库里面,去把所有的库的索引都要加好,然后再改中间件上的配置。
分布式数据库
上面这一种就比较麻烦,因此我们有更方便的解决方案:分布式数据库。
像 Citus 属于其中一种,Citus 比较特殊,它是建立在 PG 基础上的(最开始已经提到这一点)。
它在 PG 上安装一个插件,叫 Citus 插件,安装完之后,做一些简单的配置,这样一些普通的 PG 就会变成 Citus 集群。
然后这些业务要和 coordinator(协调节点)打交道,然后 coordinator(协调节点)再把 SQL 分发到底下的各个 worker(工作节点)上。
总结图
分片及工作原理
我们首先看,在这一套架构:Citus 怎么管理数据,数据是怎么分布的。
适用场景:HTAP
数据分布:
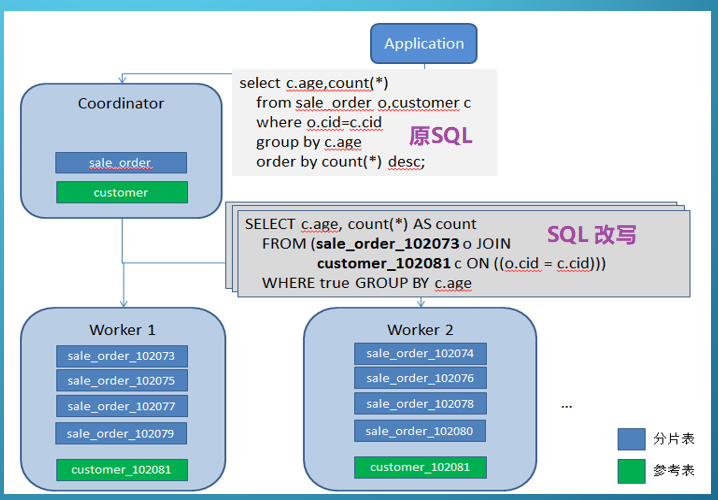
1、分片表(distributed table):rows会分布在 worker节点中。主要用于大量数据的事实表。
hash:按分片字段 hash 值分布数据
》》》按照某个字段进行分片,每个 worker 来管理多个分片。
append:分片 size 增加到一定量自动创建新的分片
2、参考表、广播表(reference table):每个 worker 节点都保存一模一样的数据。主要用于维度表。
仅一个分片,每个 worker 一个副本,主要用于维度表。
》》》主要是维度表,协助分片表做 join。(参考下面案例)
3、本地表
建一个表在上面,不做任何配置。
例如下面:
把 原SQL 改写(逻辑表名 改为 分片表名),把 SQL 分发到各个 SQL 上面执行。
最后再把 worker 上的结果进行收集汇总返回给应用。
主要特性和性能参考
主要特性:
1、PostgreSQL兼容
》》》因为它本身就是工作在PostgreSQL里面(作为插件)。
2、水平扩展
》》》2个 worker 不够可以扩容到 4个 worker。coordinator(协调节点)默认 1个,不够的话也可以扩容到 2个。
3、高并发增删改查
》》》可以作为交易系统,OLTP的交易系统。
4、实时数据分析
》》》分析性的SQL可以快速的给到结果。
5、支持分布式事务
6、支持常用DDL
基于以上:我们可以把 Citus 集群,可以当做一个单库来看待(使用层面)。
性能方面:
OLTP场景:基于主键的随机点查询SQL。
单个 coordinator(协调节点)架构的 QPS 是 PG性能的三分之一 ~ 二分之一。
》》》Citus coordinator(协调节点)1w(单核); PG非预编译语句 1w(单核); PG预编译语句 2.5w(单核);
》》》测试是 Citus 7.4,后面 Citus9以后性能和 PG 就差不多了。
上面是理想场景下,单个小表的随机点查询,单个PG没有多个IO,基本上都是基于内存的情况下。
但是真实场景下:
第一、表变大了,缓存的命中率不一定那么高;
第二、我们的SQL不一定都是简单的单个表查询,可能是复杂的关联查询,Citus的优势就来了,Citus coordinator 节点就简单的做一些计算,它没有 IO。
所以说,真实的场景下,单机的 Citus 可能比单机的 PG 要快。
OLAP场景:最典型的就是聚合分组计算,这样的场景下,Citus 有个很大的好处,它可以做并行,它是做分片并行的。
理想情况下,聚合SQL执行时间和分片数量成反比。
举个例子:
日常维护性能参考(1个 coordinator节点 和 8个 worker节点,96个分片,PG 10 + Citus 7.4)
PG 默认两个并发:count(*)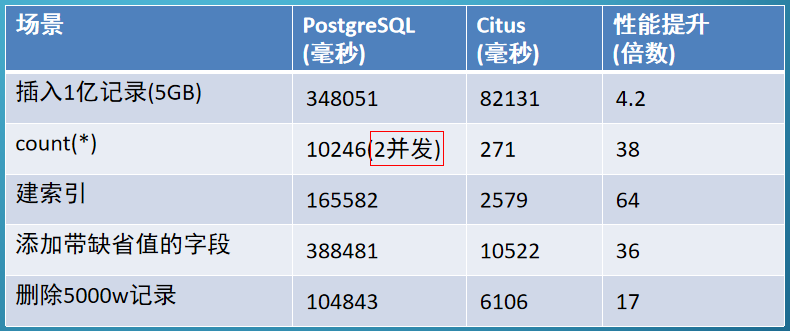
分布式方案对比

Citus 苏宁的应用案例

Citus 环境搭建
1、准备集群资源(一个节点指一套 PG HA 集群,测试环境可以用单实例PG)。
》》》一个coordinator(协调节点);条件允许的话,可以选择高配 CPU 的主机。
》》》2^n (2,4,8,16,…)个 worker (工作节点);(2的幂是为了方便扩容)。
2、安装配置 PostgreSQL:省略
Citus 的日常运维,除了扩缩容,节点迁移外。
其他方面和普通 PG是一样的,例如:HA部署,备份恢复,监控告警…等
3、安装插件
1 | tar xzf citus-9.2.3.tar.gz |
注意:也可以通过社区预编译包安装:postgresql 官方下载地址
4、创建扩展
1 | # 必须将 citus 作为第一个库,作为预加载 |
5、添加 worker (工作节点) ===> 只在 coordinator (协调节点)执行
1 | # 把下面的替换成对应的 IP、PORT 就好了。 |
案例演示:建表
1 | 创建分片表 sale_order |
1 | 创建参考表 customer |
1、在每个 worker 上创建分片
2、更新元数据:pg_list_partition、pg_dist_shard、pg_dist_shard_placement
元数据:三个表



带分片字段的SQL查询
在 citus 里面,所有的查询,为了方便我们理解,所有查询分成两类:一类是带有分片字段的查询,还有一类是不带分片字段的查询。
例如:下面的带有分片字段的SQL,下面的分片字段 oid = 100,coordinator 节点拿到这个 SQL 之后,会解析这个 100,会把 100 算成 hash 值,然后拿这个 hash 值算它属于哪个分片,再看分片的位置,在分片所在的 worker 上执行这条 SQL。
关键点在于 Task Count: 1,这样的执行方式是比较适合高并发的交易系统,交易类的业务的。
为了提升高并发场景的性能,coordinator 会对每个 worker 上的连接做缓存,进行复用提高性能。
不带分片字段的SQL查询
例如下面案例,这里有一个典型的分组的聚合 join。
在这个 SQL 执行的时候,citus 会把这个 SQL 做成子的 join SQL,然后在每个 worker 上按照分组字段先做一次聚集,然后再把所有的结果返回到 coordinator 上,coordinator 收到 worker 的结果之后,再做一次最终的聚合。
这里面,coordinator在执行的时候,它是按照分片在每个 worker 上并发去执行的,并发数主要受分片数影响。
比如,我有 8 个分片,这里就有八个并发同时在跑。
这里有一个参数 max_adaptive_executor_pool_size 可以控制单个 worker 的并发数,防止单个 worker 负载过高。

亲和性概念
前面只是简单的入门,我们想要用好 citus 的话,还要更深入了解它的一些概念。
例如:最基本的亲和的概念。
亲和什么意思?
我们在执行 SQL的时候,会涉及到多张表,最典型的例子就是涉及到 join。
假设两个表做 join,效率最高的就是把每个 worker 上进行两张表进行 join,要做到这一点,就要把这两个表的分片逻辑(分片位置)是一致的,也就是两个表做亲和。

亲和性定义
2022-03-15 08:02:19
亲和性的 join 案例
表定义

亲和 join

非亲和 join

分布式事务
1 | # 1. Citus对各种跨库操作采用2PC保障事务一致 |
跨库事务案例
2022-03-15 09:22:03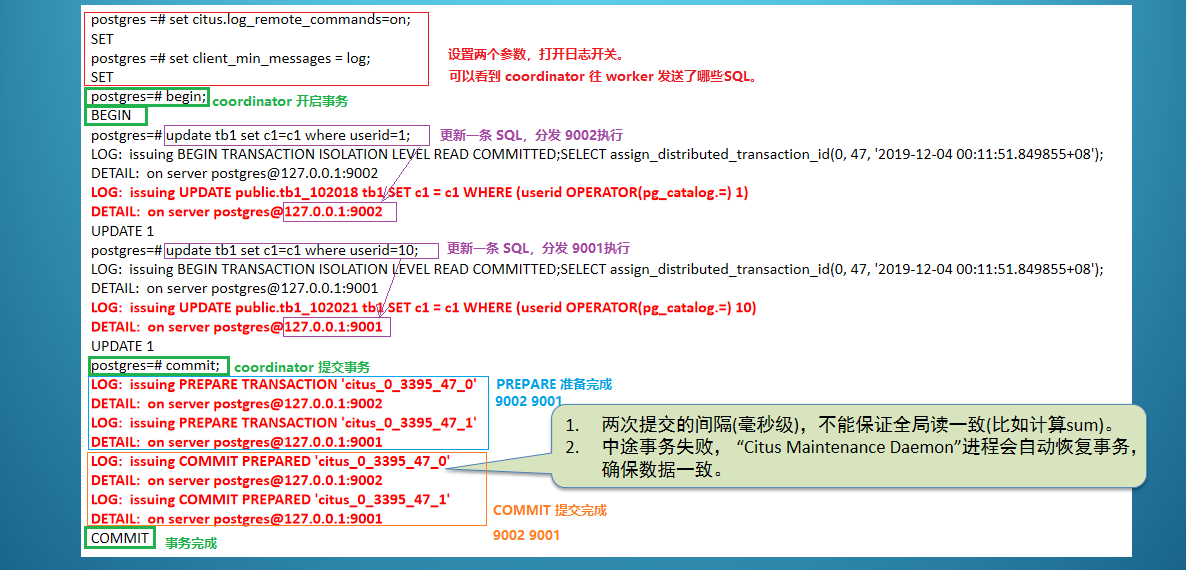
这里会有两个问题:
问题1、9002 COMMIT 完成,此时另外一个来进行 sum 计算,计算完成之后,9001 COMMIT 完成。
》》》这样就会产生全局的不一致性读问题,所以说 Citus 不支持 全局的MVCC。
》》》这种缺陷,所有基于分库分表的中间件方案,也都是有这个问题的,只不过大家分库分表用的那么多,也都没人提这个事情。
问题2、9002 COMMIT 完成,此时9001节点鸡掰,恢复之后,”Citus Maintenance Daemon”进程会自动恢复事务,9001会继续 COMMIT,然后整个事务完成。
表设计
我们一张业务表,究竟要做成那种类型的???分片表、参考表、本地表
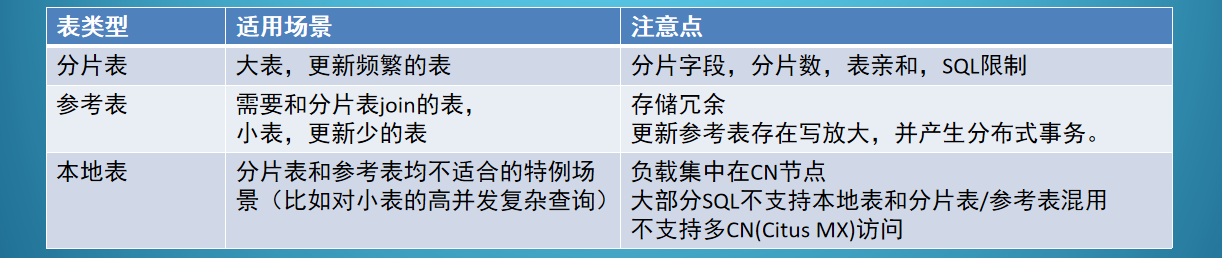
分片表
Citus 的核心肯定是分片表,这个是它的核心价值。它的作用就是把大表拆小,然后把负载分散开来。
但是要注意:分片字段,分片数,表亲和 这些东西。- 参考表
参考表就是为了配合分片表做 join。
为什么小表?因为参考表在每个 worker 上都有,大表的话,worker 占用的空间太大了。
另外每个参考表的更新都会产生分布式事务,都会在每个 worker 上都会更新,这样它也不适合频繁更新的表,那样性能肯定不会好。
- 参考表
本地表
本地表尽量不要用,除非上面分片表,参考表都不适合,又想做小表的高并发查询。
分片字段
- 每个SQL中都带等值条件的字段(比如用户ID)
- join 关联的字段
- 高基数且值分布均匀的字段
- 日期(按天)通常不适合作为分片字段,业务往往倾向于访问最近的数据,容易形成热点
分片数
建议2的乘方。比如: 条件好的话直接 32,64,128…(条件不好的话 2、4、8、16 也可以,顶不住的适合,也可以后续扩容)
》》》前面已经说了,为了方便扩容控制单分片最大记录数和大小(比如1亿,10GB)
》》》超过限制,会影响性能建议不超过worker总core数的2~4倍
》》》防止单 worker 负载过高。
》》》前面已经说了,新版本可以使用:max_adaptive_executor_pool_size 可以控制单个 worker 的并发数,防止单个 worker 负载过高。为今后 worker 扩容保留一定余量
》》》防止意外,要留有余地
分片数影响查询性能
第一类是最简单的带有主键的查询 SQL。
数据量大的时候,分片数越多,数据分布的越散,性能更好(前提是数据量大哟)。
不带分片的话,要到每个 worker 上去执行,所以说,分片越多,性能越差。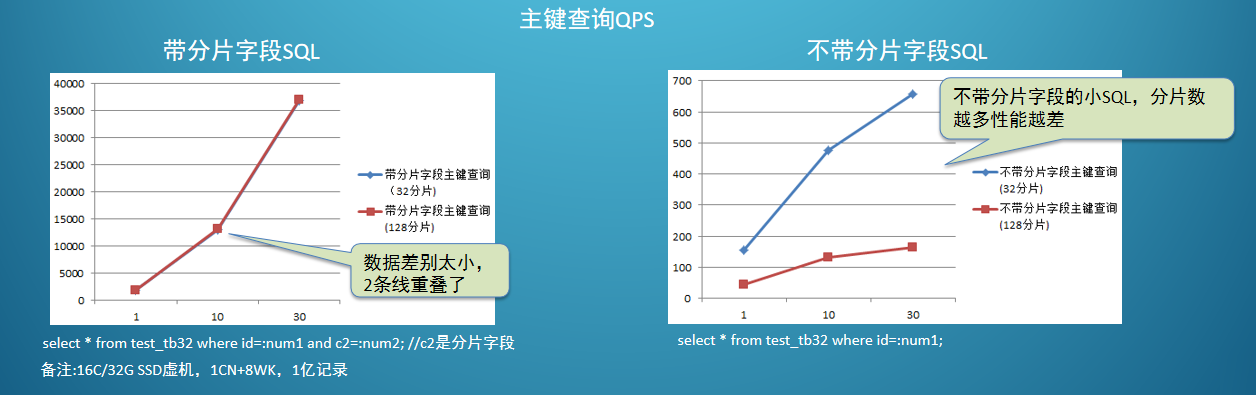
第二类分析类的,分组聚合的 SQL。
也要看场景,分组数少的话,性能差不多。但是分组数多的话,性能差异就会很明显。
因为执行这样 SQL 的时候,每个 worker 上先做 group by,再把结果集返回到 coordinator 上,再做聚合的结果。
但当分片数多的话,结果集就越多,导致 coordinator 的压力越大,执行时间就越长。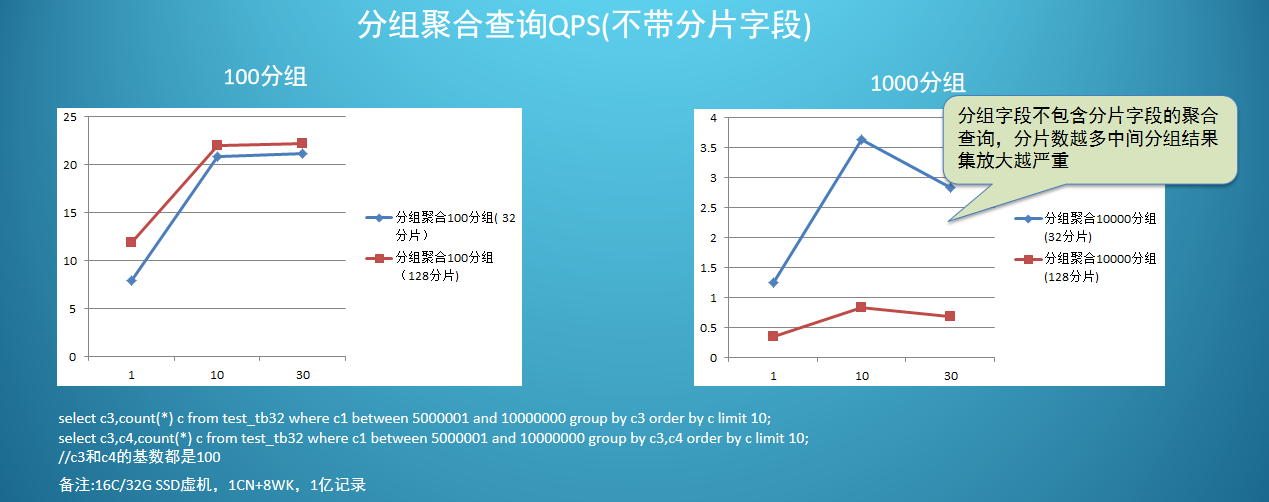
SQL限制
2022-03-15 10:06:23
Citus 的 SQL 兼容性在不断的提升,但我们要用的话,还是要了解它是有哪些 SQL 的不支持的。
1 | # join的限制 |
注:更多限制参考:Citus 不支持 PostgreSQL 哪些功能?
SQL改写
SQL 改写
1
2
3
4
5
6
7
8select a.userid,c1,c3 from tb1 a join tb3 b on(a.userid=b.userid);
-- 改写 ↓↓↓
with b as(
select * from tb3
)select a.userid,c1,c3 from tb1 a join b on(a.userid=b.userid);
-- with 就相同于一个子查询,然后再把子查询结果与 tb1 进行关联。执行计划

FDW改写
FDW是一种变相的”临时表”,如果直接通过临时表回避SQL限制,需要应用把一个SQL拆成多个SQL,增加业务改造成本。
1、在CN上创建本地FDW Server
1 | create extension postgres_fdw; |
2、封装FDW表
1 | CREATE FOREIGN TABLE tb1_fdw(userid integer,c1 text) |
3、SQL改写
1 | select a.userid,c1,c3 from tb1 a join tb3 b on(a.userid=b.userid); |
4、执行计划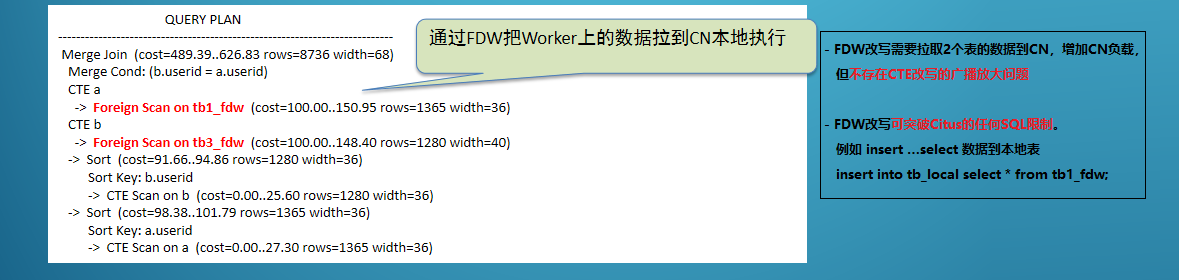
非亲和 inner join 执行性能对比
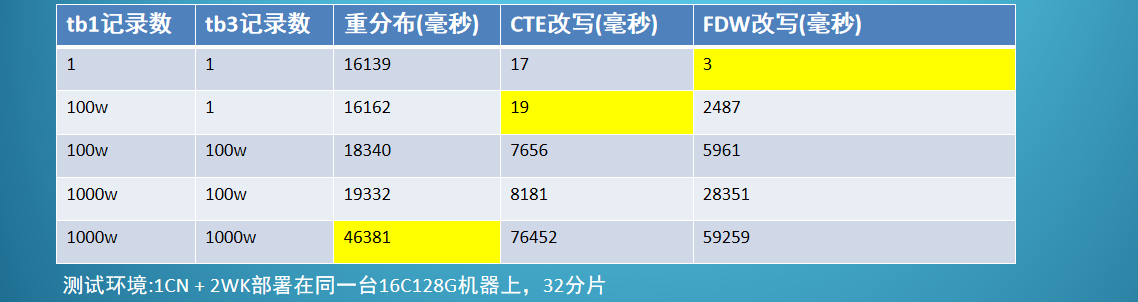
- FDW改写适用于两个小表 join
- CTE改写适用于大表和小表 inner join或大表对小表的 left join
- 重分布适用于大表和大表 inner join
注:大表小表指的是WHERE条件过滤后的结果集大小
DDL支持
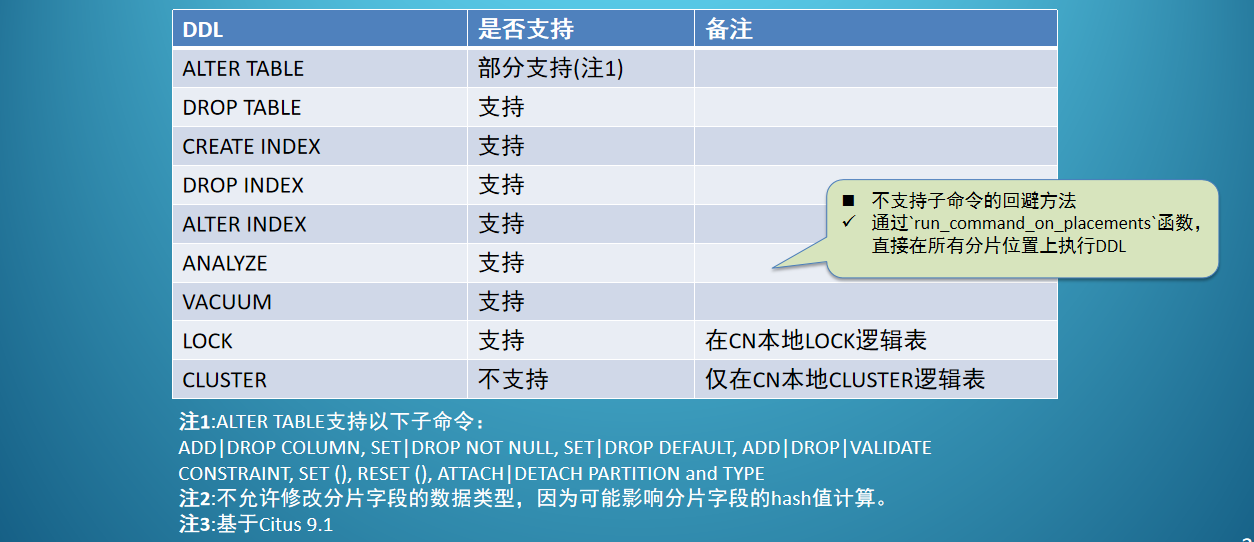
DDL执行案例
Citus不允许修改分片字段类型
1
2
3
4
5create table tbdist(id int,c1 varchar(20));
select create_distributed_table('tbdist','c1');
postgres=# alter table tbdist alter c1 type varchar(50);
ERROR: cannot execute ALTER TABLE command involving partition columnvarchar(20)改成varchar(50)不影响分片字段hash值计算,可以通过修改元数据实现,避免重导数据。
反之:若修改的是字段类型,就要重导数据了。1
2
3
4
5
6SELECT run_command_on_placements('tbdist','ALTER TABLE %s ALTER COLUMN c1 TYPE varchar(50)');
BEGIN;
SET LOCAL citus.enable_ddl_propagation TO off;
ALTER TABLE tbdist ALTER COLUMN c1 TYPE varchar(50);
UPDATE pg_dist_partition SET partkey = column_name_to_column(logicalrelid, 'c1') WHERE logicalrelid = 'tbdist'::regclass;
END;
SQL的连接数控制
不带分片字段SQL的连接数控制
设置 citus 任务执行器
1
SET citus.task_executor_type = 'adaptive'|'task-tracker';
adaptive执行器(默认执行器)
1
2
3
4
5
6
7执行不带分片字段SQL时,CN对所有worker上的所有shard同时发起连接,并执行SQL收集结果。(原real_time执行器的增强版。)
citus.max_adaptive_executor_pool_size:
执行不带分片字段SQL时,每worker发起的最大并发连接数,默认值16。
citus.max_cached_conns_per_worker
每worker缓存的连接数,默认值为1。
- task-tracker执行器
1
2
3
4
5
6
7
8
9
10执行不带分片字段SQL时,CN只和worker上的`task-tracker`进程交互,
调用worker上的`task_tracker_assign_task()`函数将任务分配给`task-tracker`,
然后轮询任务的完成状况,待任务结束后再开一个连接从worker取回结果。
citus.max_running_tasks_per_node:
每个worker同时执行的最大并发数,默认8
》》》通过调参合理控制并发数,避免并发连接过大影响系统稳定。
比如:对数据导出任务,可以设置citus.max_adaptive_executor_pool_size为1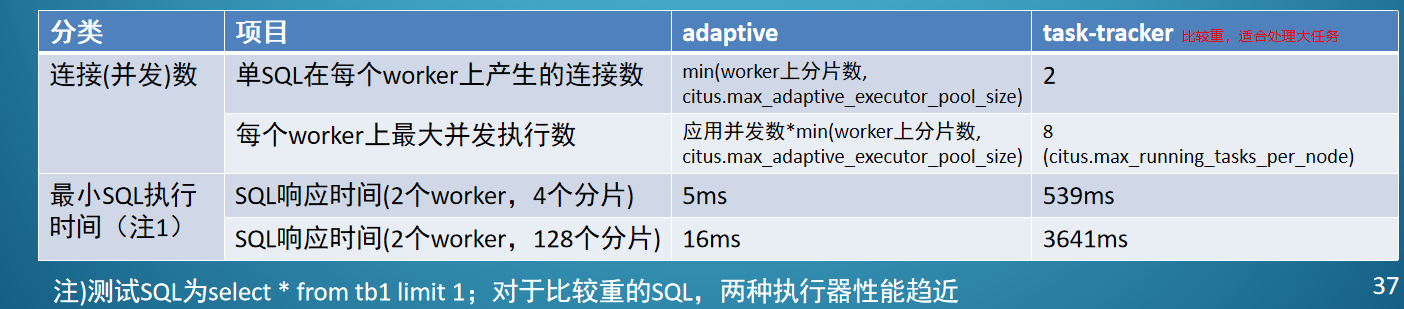
高并发点查询SQL优化示例
不带分片字段的高并发点查询SQL优化示例
对于高并发的业务,我们要尽可能做到这个 SQL 是带分片字段,并且是能够分发到单个分片上去的。
但是,我们有些业务它没办法做到这一点,那么怎么去做优化呢?
- 表定义
1
2
3
4
5
6
7
8
9
10postgres=# \d tb3
Table "public.tb3"
Column | Type | Collation | Nullable | Default
-----------+---------+-----------+----------+---------
productid | integer | | |
userid | integer | | |
c3 | text | | |
Indexes:
"tb3_productid" btree (productid)
"tb3_userid" UNIQUE, btree (userid)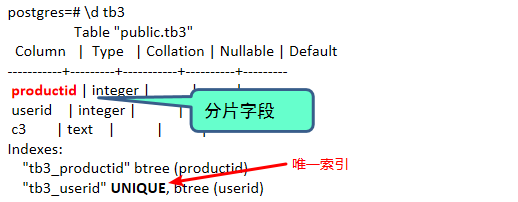
- 原始SQL执行计划(原始SQL)
1
select * from tb3 where userid=9
1
2
3
4
5
6
7
8
9QUERY PLAN
-----------------------------------------------------------------------------------------------------
Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=127.0.0.1 port=9001 dbname=postgres
-> Index Scan using tb3_userid_102081 on tb3_102081 tb3 (cost=0.28..2.50 rows=1 width=11)
Index Cond: (userid = 9)
↓↓↓优化↓↓↓:拆分成2次带分片字段的查询
创建分片字段索引表
1
2
3
4create table tb3map_userid2productid(userid int primary key, productid int);
select create_distributed_table('tb3map_userid2productid', 'userid');
insert to tb3map_userid2productid select userid,productid from tb3;SQL 改写一:应用发起2次SQL
1
2select productid from tb3map_userid2productid where userid=9;
select * from tb3 where productid=? and userid=9;SQL 改写二:通过FDW包装成一个SQL
(改写二只需要改SQL不需要改应用程序,但QPS性能只有方法一的1/3)1
2
3
4
5
6
7create foreign table tb3map_userid2productid_fdw(userid int, productid int)
server server_cn_local
options (table_name 'tb3map_userid2productid');
select * from tb3_fdw where
productid = (select productid from tb3map_userid2productid_fdw where userid=9)
and userid=9;执行计划(SQL 改写二)
1
2
3
4
5QUERY PLAN
--------------------------------------------------------------------------------------------
Foreign Scan on tb3_fdw (cost=246.86..276.08 rows=1 width=40)
InitPlan 1 (returns $0)
-> Foreign Scan on tb3map_userid2productid_fdw (cost=100.00..146.86 rows=15 width=4)
数据导入
INSERT
1、批量插入的数据被CN拆成单条非预编译INSERT发送给Worker
(即使你插入的是预编译SQL发给CN,CN也会拆分非预编译发给Worker)
2、单个insert中如有多个value,属于同一分片的值仍以多value的形式发送给worker
3、JDBC的批更新和reWriteBatchedInserts=true优化参数可一定程度提升插入性能,但整体上INSERT的性能偏低COPY(速度较快,取决于索引和数据量)
1、典型业务表Copy导入速度:大约10w/s(速度依赖部署环境和表定义)
2、索引较多的大表导入速度慢。每个Worker上的所有分片同时导入,容易导致缓存不足。可以通过分区进行优化。官方测试
1
2
3Insert and Update: 10-50k/s
Bulk Copy: 250k/s-2M/s
Citus MX: 50k/s-500k/s
参考表负载不均
应用读参考表时默认始终访问第一个分片,高频访问会造成负载不均衡。
可使用轮询策略:
1 | SET citus.task_assignment_policy TO "round-robin" |