参考:BV1Jq4y1p7Rw
Redis数据库设计:hashtable
hashtable:里面只保存index,而index是指向 entry 的,entry 是有 next 指针的。
hash冲突:采用头插法,Redis是内存,表示你先插入的数据,可能最先访问到。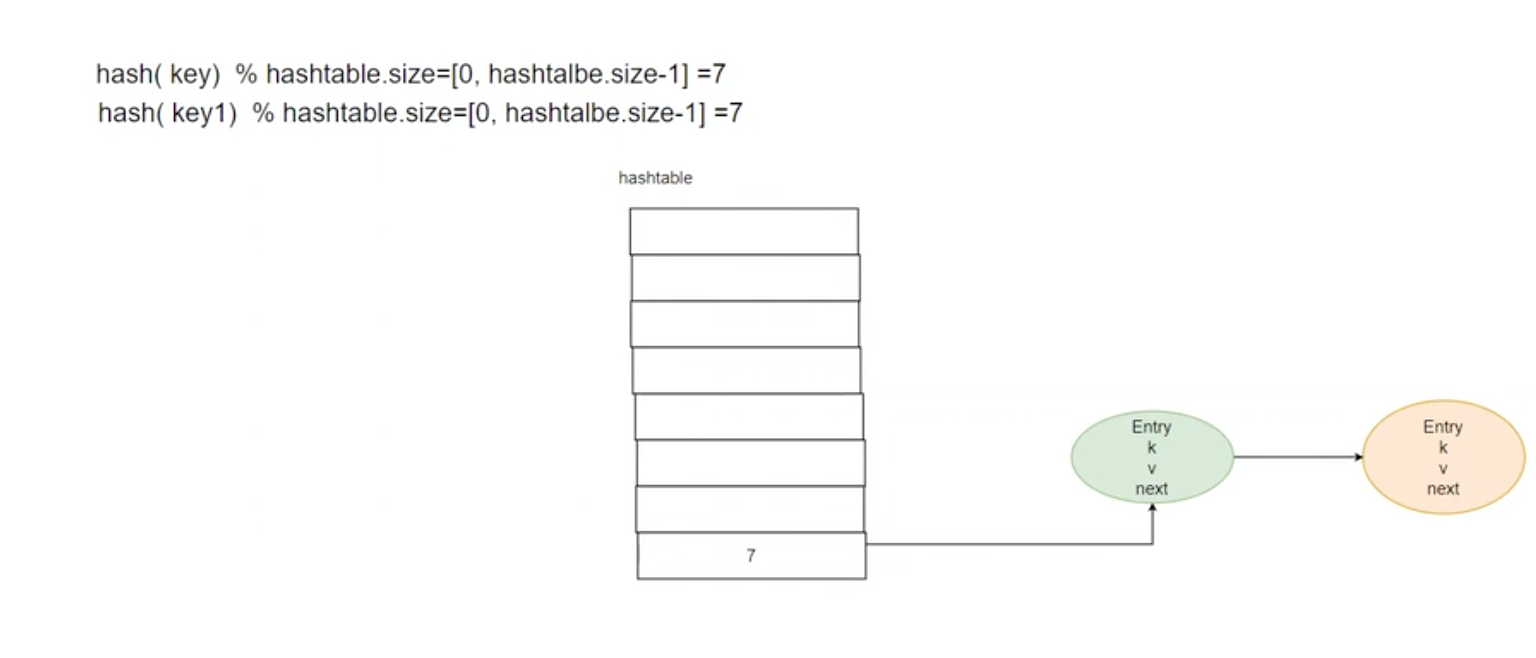
rehash机制
扩容搬运时机 1:访问的时候,定位到 old_index,然后把 old_index 下面的链表搬到 new_index 中。
扩容搬运时机 2:后台还有一个会定时轮询搬运,一次搬运 100 个。(如果直接全部搬运,数据量大的时候,可能会引起卡顿)
两个同时存在,怎么访问呢?
访问:先访问 old ,old 不存在,再访问 new。
插入:会插入到 new 不会插入到 old。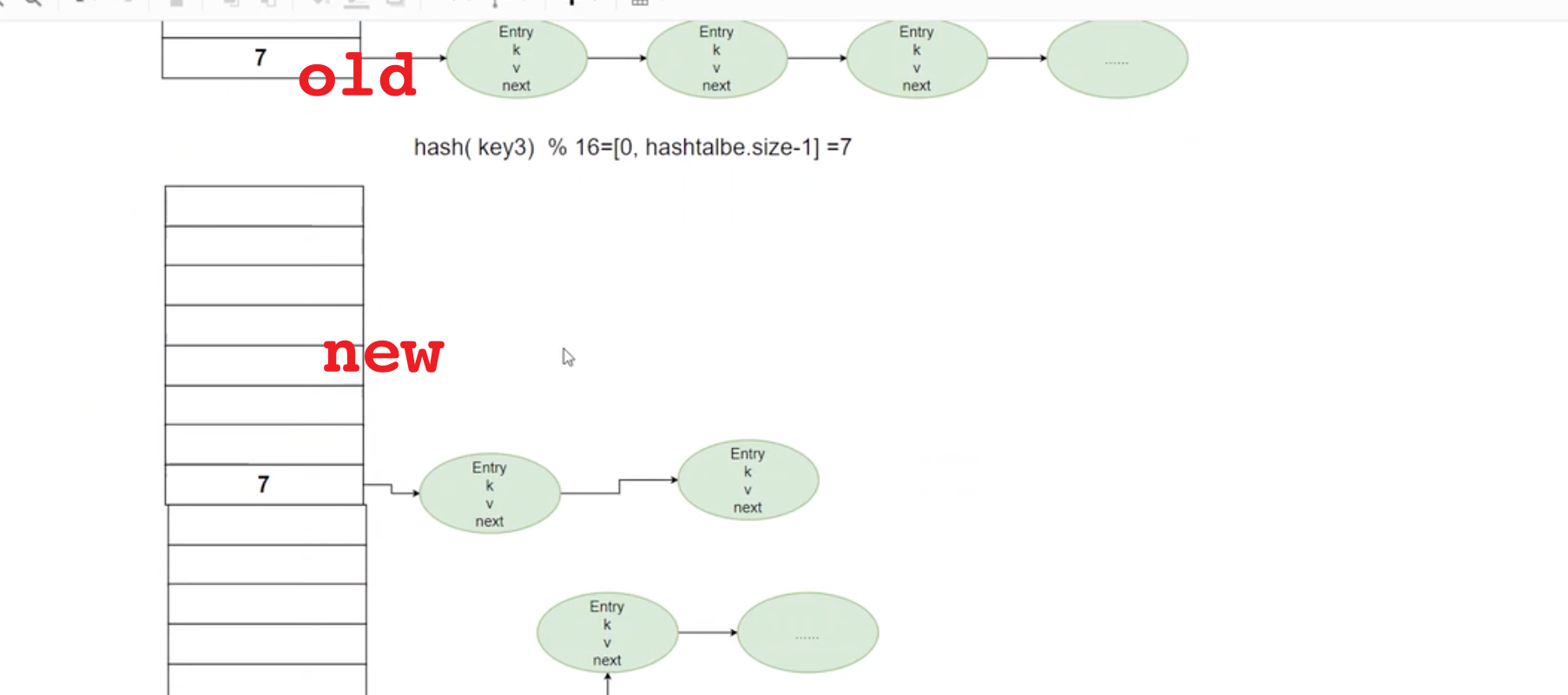
Redis key的数据类型
Redis 的 value 类型有很多:String,List,Set,ZSet,Hash,Geo,Hyperloglog,Bitmap,
那 Redis 的 key 呢,你不论传什么,传音频,视频,server 端也会转换为 String 类型。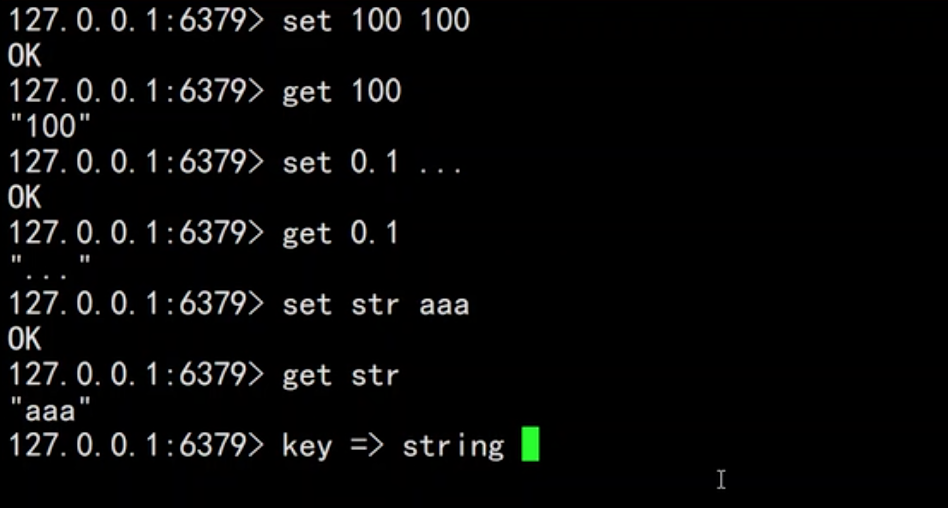
key String 类型设计
1 | string 在 c语言默认是char数组表示的:char [] data=“abc\0” |

RedisDB源码讲解
1 | // Redis database representation. |
stringObject临界长度44
1 |
|
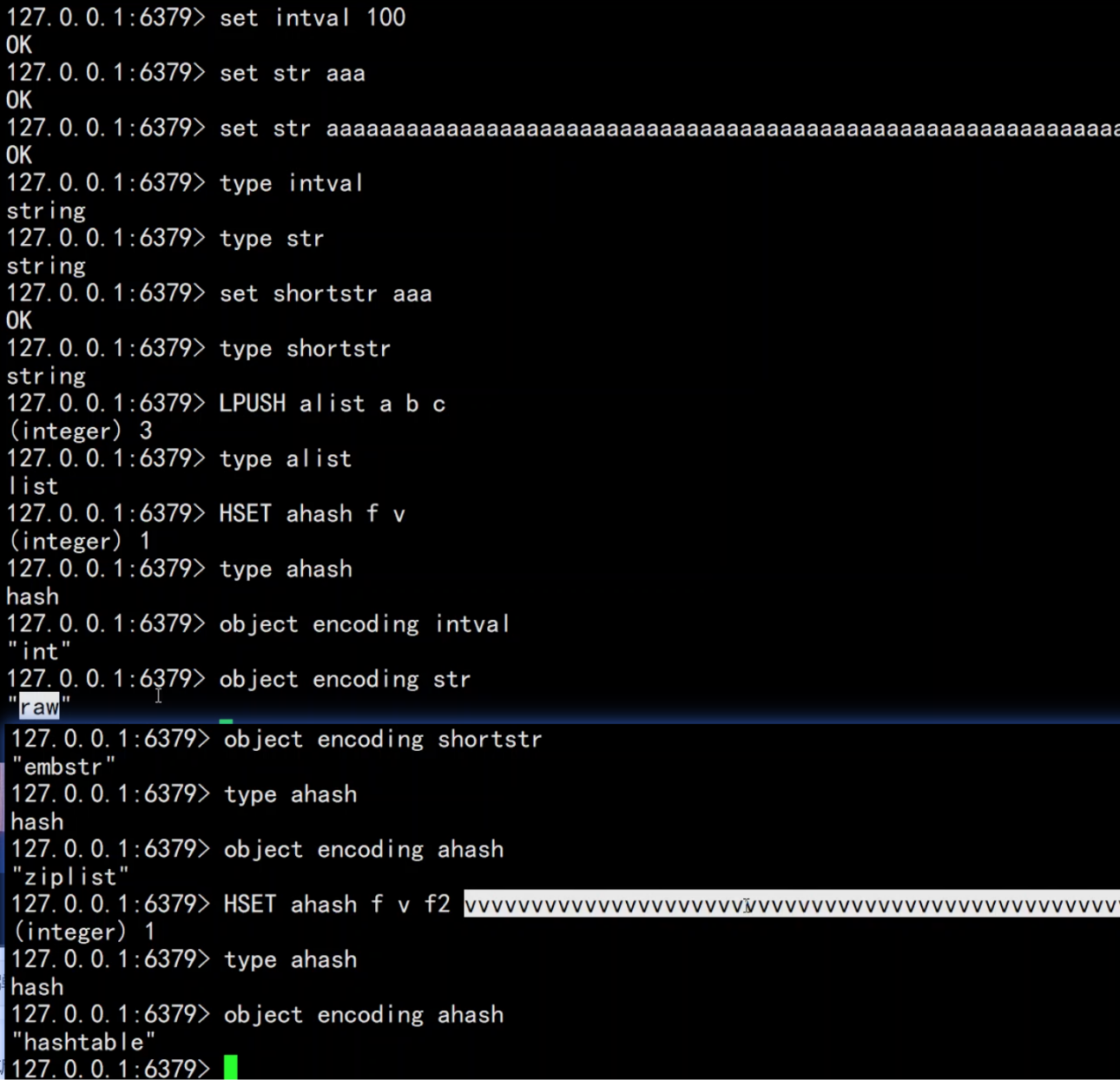
编码转换
int => raw
1 | 127.0.0.1:6379> set k1 1 |
embstr => raw
1 | 127.0.0.1:6379> set k1 v1 |
结语
(2021-11-05 11:35:27 后面我就没写了,我买了一本 《Redis设计与实现》 ,看完后,也是对Redis内部有更近一步了解了。)