本文简介

数据库瓶颈
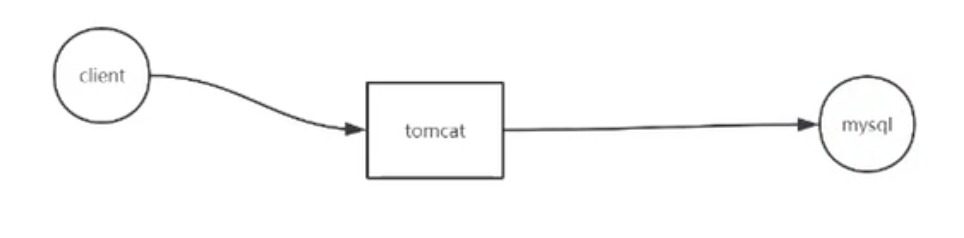
上面是一个客户端连接的情况,假设客户端非常多,Tomcat 和 MySQL 谁先出现瓶颈???
答:mysql 数据库。一般数据库出问题了,就会带来用户体验差,响应时间变长,这是最直观的感受了。
怎么减少数据库的瓶颈???
答:减少数据库的连接,一般使用连接池的概念。
当然,你也可以选择其他的解决方案,例如:分库分表,数据库集群,加缓存层。
Redis 格挡
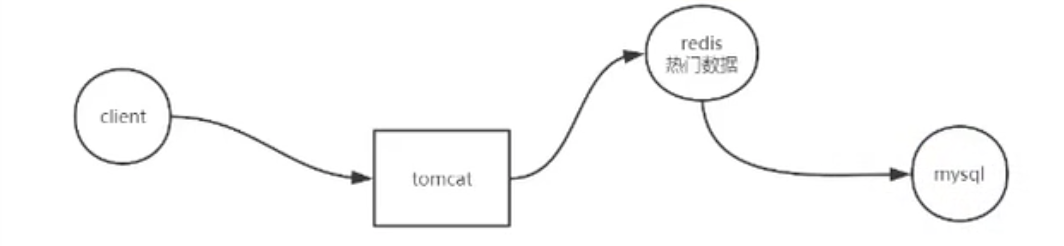
一般来说加缓存 => Redis,这样 Redis 就可以为 MySQL 挡掉一部分请求。
缓存穿透问题
但是,逃不过一个问题:缓存穿透
就是查 Redis 查不到,还是会去 DB 查询。但是 DB 也差不到,就会一直查下去,就把 Redis 这扇门给穿透了。
1、主动刷新
2、数据同步(但是你也不能保证实时的同步)
虽然,我们不能避免低频缓存穿透,我们可以避免高频的缓存穿透。
低频,就是一个黑客,一直访问 id = -1 的数据,Redis 没有,一直去 DB 查,DB 也没有。
高频,就是一直使用 id = -1 就攻击你服务器,使你一直查 DB,这样就瘫痪了。
基于这个,也有一个解决方案:DB 查到 -1 为 null ,我把 id = -1 放入 Redis 不就解决下一次的非法请求了吗。
总结:黑客通过一个固定的 id 来进行攻击,我们可以把这个 id 放入 Redis 来解决对 DB 的攻击。
但是,黑客也没有那么傻,黑客要用 id = UUID 来攻击,你就再使用上面的方案,就会适得其反。
第一次,使用 u1 攻击你,你把查了 Redis,再查 DB,再把 k=u1,v=null 放入 Redis。
第二次,使用 u2 攻击你,你又同上,查 Redis,查 DB,再把 k=u2,v=null 放入 Redis。
那么使用什么呢?
或许你已经猜到了,就是布隆过滤器啊!
过滤器内存紧张问题
在讲布隆过滤器,我们先讲一下过滤器。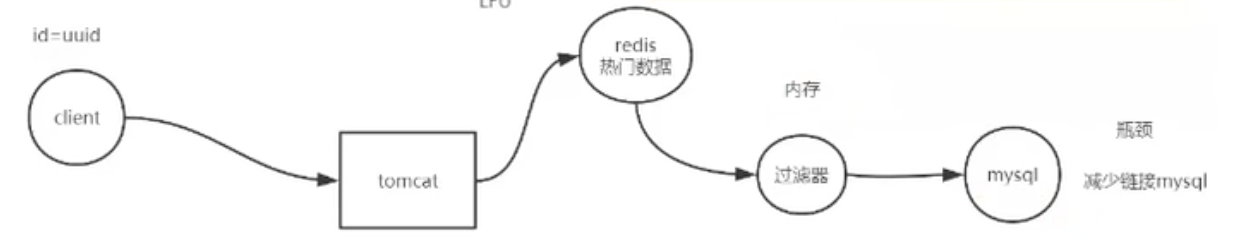
过滤器不可能放入磁盘,为了快要放入内存。但是 MySQL 数据量大的话,就要把 MySQL 所有数据放入过滤器中,会存在内存紧张的问题。
布隆算法
解决内存紧张:布隆算法,会通过一定的错误率来换取空间。
布隆算法原理:通过一个 bit 数组,来标识我们的数据,存储我们的数据。
使用上面过滤器的话,过滤器中会实打实的存的我们数据库中的 id 值。但是通过布隆算法就不是了,会通过一个 bit 数组来标识我们的 id 值。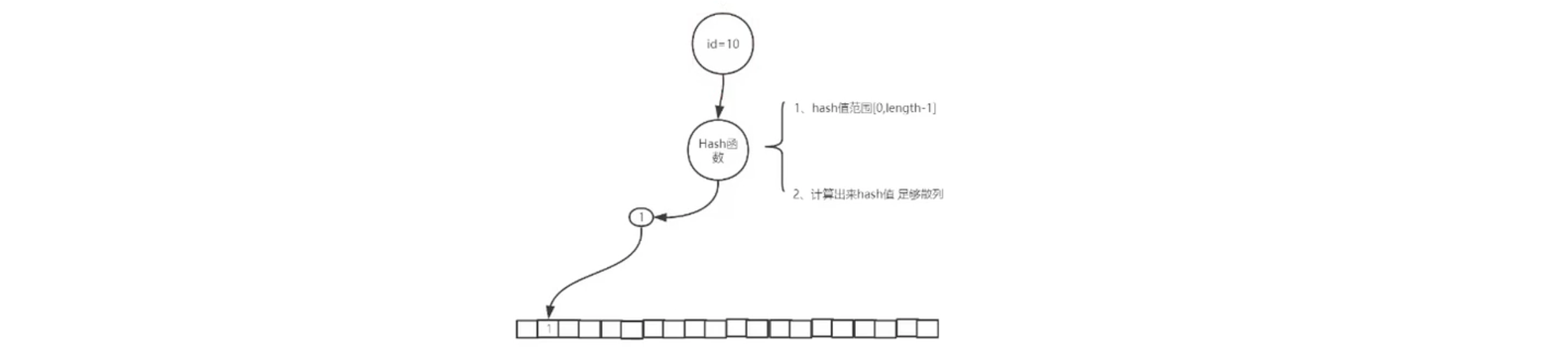
hash函数特点(1、hash值范围[0, leng-1] 2、计算出来的 hash 值足够散列)
假设我们的 id = 10,通过一个 hash函数计算出来是 1,那么就命中 bit 数组的 1 号下标,把 1号下标的 0 改为 1。
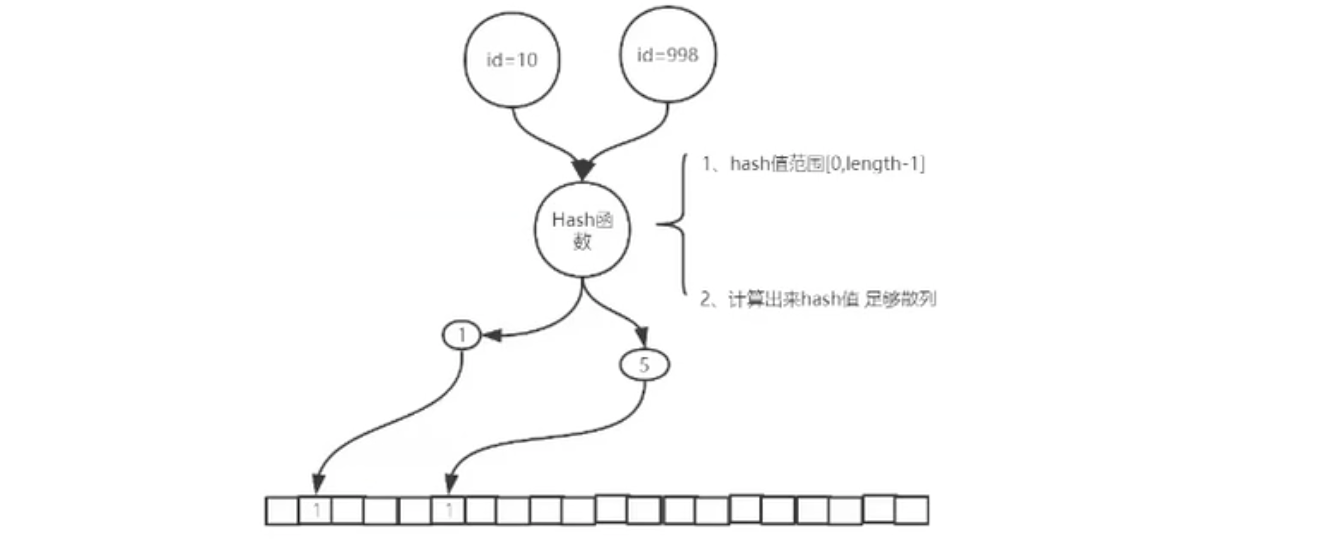
再来一个 id = 998,hash函数计算为 5,定位到下标 5,把下标 5 的位置 0 改为 1。
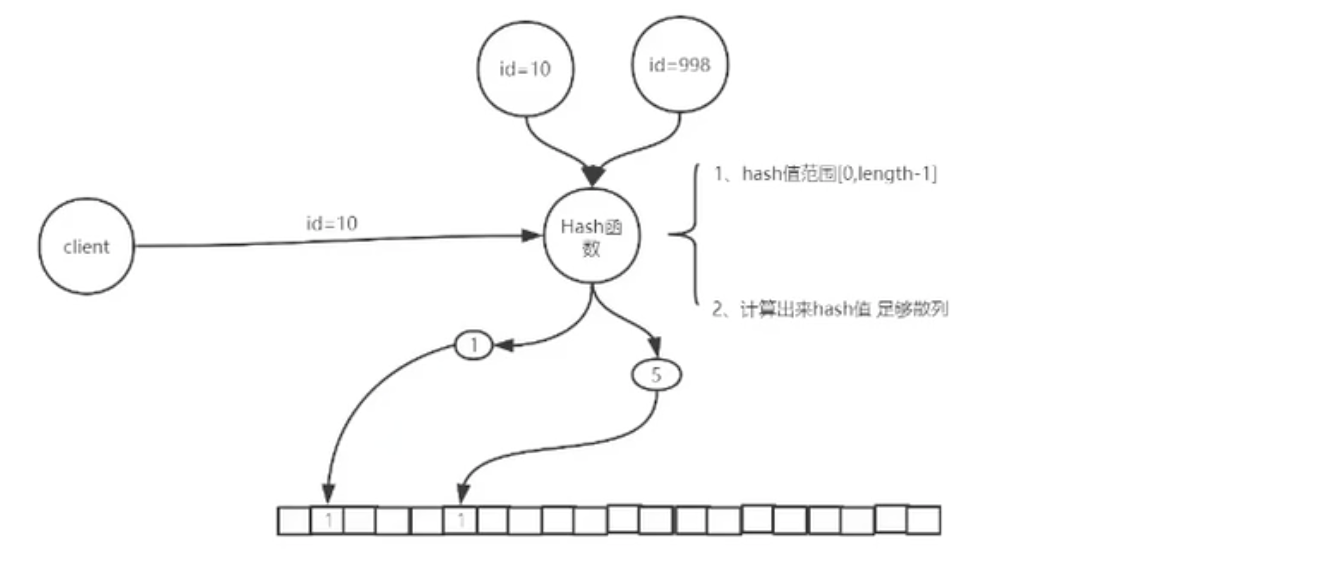
假设,此时我们客户端 id = 10 来请求,查询过滤器,定位到 1 号下标,查看标志为 1。(1表示我们储存过),可以访问。
但是,当哈希碰撞时就会有问题:假设我们查询是 id = 100,查询过滤器,定位也是 1 号下标,也可以通过访问。(我们没有存 id = 100,但是 id = 100 却可以访问)
为什么说错误率换空间
上面说通过一定的错误率来换取空间,错误率我们知道了,但是为什么说换取空间呢???
因为 bit 数组占内存实在是太少了,bit换算 — 百度一下,我们可以看到 10亿个 bit 才占用 120mb。

Hash碰撞解决方法
布隆算法由于存在hash碰撞,所以导致错误率。
怎么减少hash碰撞呢(怎么减少错误率)???
1、增加数组长度(不用讲)
2、增加hash函数的个数(假设 3 个 hash 函数,一个 id 计算出来三个坑位,把下标置为 1)
假设一种情况,数组长度为 10(共 10 个坑位),我用 10个 hash 函数,把收到一个 id 时,计算出来 10 次,这 10 个坑位都占满了。那么后面再收到的请求,都会通过。因为所有坑位都是 1。
===> 所以,hash函数并不是越多越好,需要参考数组的长度。
hash函数错误率:布隆算法说数据存在,那么实际有可能不存在。说数据不存在,那么一定不存在。
缓存雪崩
缓存层中缓存的数据,在某一个时刻突然失效(无法访问),导致大量的请求打向 MySQL 数据库。
1、Redis 缓存的数据有效期一致导致的(例如:Redis中放 100个 key,过期时间都是 1天,那么 1天后所有的请求都会打向 MySQL)
解决:给每条加一个随机有效期(0.1,0.3,0.5,…)。不要用时失效
2、Redis挂了。
解决:分片集群、副本集群。即使 1号 Redis 挂了,还有 2号、3号 Redis。
缓存雪崩、缓存击穿的本质都是缓存穿透,是缓存穿透的一种特殊表现。
缓存击穿:某一点,极端热点数据失效,所有请求打向数据库。
解决:分布式锁。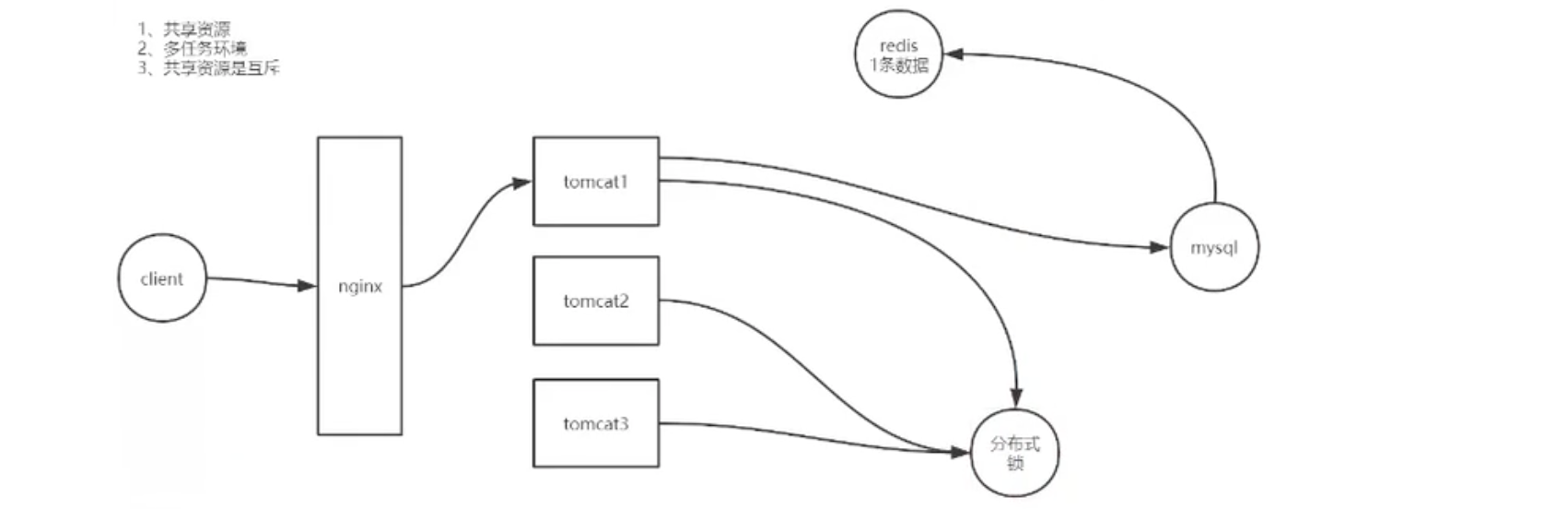
ms
出去面试需要一些面试技巧。
1、精美简历
2、挖坑(在精美简历里面挖坑,这叫不完美的美)
3、比如,面试官问:你在项目中遇到过什么 bug 啊,黄金 bug 啊,解决方案。性能问题,解决方案。
4、注意:在上面说的 bug啊,性能问题啊,要描述的清清楚楚,关于解决方案要一两句话带过
比如说:接盘项目,10 QPS,性能提升之后 200 QPS。描述清清楚楚,怎么解决,就说引用了 Redis 做分布式缓存。
面试官所问你的第一个问题,一定是比较吸引他的问题。像上面这个问题就比较吸引他,如果他不是特别 low 的话,他会沿着问的,他可能会问你,具体是怎么优化的。对吧。那就继续聊啊,我是加了一个缓存层,我把一些热门数据放到 Redis 里面去了。但是这时候你要跟他聊细节,你当初是怎么判定热门数据的,判定标准是什么样的,你 MySQL 中的数据是怎么迁移到 Redis 中的,这些细节一定要聊清楚。
你不要等着面试题去问你细节,面试官问你细节的时候,恐怕你很多细节真的是很难答上来,不管你有没有做过,哪怕是做过一些细节你也答不上来,对吧!所以你就主动出击,把这些细节给他聊明白了,让他不要怀疑你,听懂了吧!
你回答了这个问题之后啊,你说你加了一个缓存层,具体怎么怎么做的,再回答完之后,你不要忘了,你要抛出来一个新的问题,你说你加了一个缓存层之后啊,它又引出了一系列的问题,比如,它给我引出来了一个缓存雪崩问题,如果他不是太 low 的话,他可能会继续问你,什么是缓存雪崩呀,你们当初是怎么解决的,那就把上面讲的给聊出来啊。
这个缓存雪崩之后啊,可以说我们最终是通过分布式缓存来解决的,我们说 redis集群它所引用的 hash 一致性算法简直是太屌了!ok,他听到这个关键词之后啊,这个关键词可能又吸引到它了。
如果他不是特别 low 的话,可能又会问你,hash 一致性算法的原理,让你给他去解释,解释完之后,再给他抛一个新问题。
你说,hash 一致性算法它也有弊端,数据倾斜问题,他可能会问你怎么去解决,我说的这个思路呢,就是你每回答完一个问题,你要抛出来一个新的问题去吸引他,让他沿着新的问题继续问你。
哪怕你抛出的这个问题没有吸引住他,他也会继续通过你的简历,是不是再继续通过找问题去问你啊,
所以,简历里面的坑,和你回答之后抛出来的新问题就可以延导整场面试。
这个很重要啊,所以有些同学会去刷题,会去背这些面经,你从来没想过怎么把这些题串起来,怎么去延导这个面试,你从来没有想过。你背那么多题有什么用啊,你只能说你去面试的时候面试官恰巧问到了这道题了,你非常的开心,能回答上来,但是接下来下一个问题你可能又是懵逼的,对吗???
这里面还有一个技巧,就是我们除了去设计这个面试,这个面试环节,怎么去引导面试官,还有一个很重要的细节,很重要的技巧,就是我们要学会去表演。其实我们回答的每个问题啊,这些答案,这都是提前准备好的,对吧,这些剧本都准备好的,那你怎么按照这个剧本去演啊。
面试官第一个问题正好,就是你设计的问题,他正好问了,问了之后呢,你这个答案也准备好了,就非常的开心啊,心里倍美,他就滔滔不绝如同黄河泛滥之势一发不可收拾,恨不得五秒钟把这个答案给你背出来,你觉得这个效果好吗???你觉得好吗???
就是说,如果你面试了一个人,你问他一个问题,就是连思考都不思考,直接给你怼答案,怼方案,不好吧!
所以,我们希望在回答这些问题的时候啊,在回答这些问题的时候,就是你要把这些问题”磕巴、卡顿啊、卡壳啊、“,你要表现出来,你要给面试官一个感觉:你是一边在回忆当初,一边在回答问题,而不是说这个答案是你提前准备好的,一旦让面试官认为你这个答案是你提前准备好的,那么他就会认为这一次面试不能很好的挖掘你的潜能,不能很好的考察你的能力,对吧!
一定要给他一个感觉,你是在一边思考当初一边在回答问题。
所以,面试成与败呀,有很多因素决定的,每一个细节我们都要把控到位,除了你要去设计你的面试环节,在面试的过程中啊,也要去设计,来,最重要的一个思路,我们要引导面试,设计我们的面试环节去引导面试,千万不要让面试官来引导你,一旦你让面试官去引导了你,你基本上没啥戏,你跟面试官是两个独立的个体,他擅长的不代表你擅长,对吧。
第二,我们细节要到位,ok,这就是我要跟你说的。
(2021-11-05 12:34:40 说是上面这样说的,但是我一点也没有用到,我也做不到这样。我还是做我自己,面试成的。)