这些问题你都知道吗?

关于1、可参考:【mysql 5.7】like ‘XX%‘一定会使用索引吗 & 离散性对like的影响(索引选择性)
什么是索引?

RDBMS:(Relational Database Management System 关系数据库管理系统)
InnoDB AHI?
自适应哈希索引 — The InnoDB Storage Engine
AHI:Adaptive Hash Index 自适应哈希索引
Hash 可以查找。但是量大的时候,进行范围查找就不太友好了。
MySQL为什么用B+Tree?
(1)、二叉搜索树
可能会发送单向链表的情况。
(2)、平衡二叉搜索树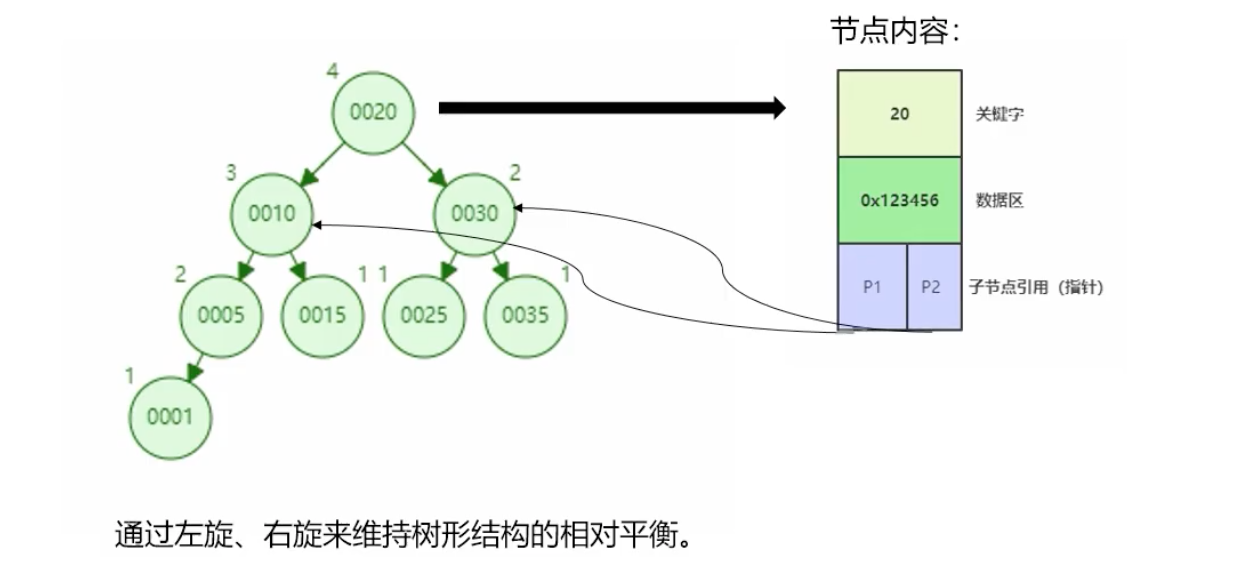
每次都要旋转,左旋,右旋,。。。来保持平衡。
每次查都需要从下往下进行查找(浪费IO),不方便范围搜索。
磁盘 -> 内存 -> 应用(IO开销,每次IO都是16KB)
(3)、B-Tree(B减树、多路搜索树、多叉平衡查找树)
不止可以纵向查找,还可以横向查找。
1 | 5, 20 的数据区划分 |
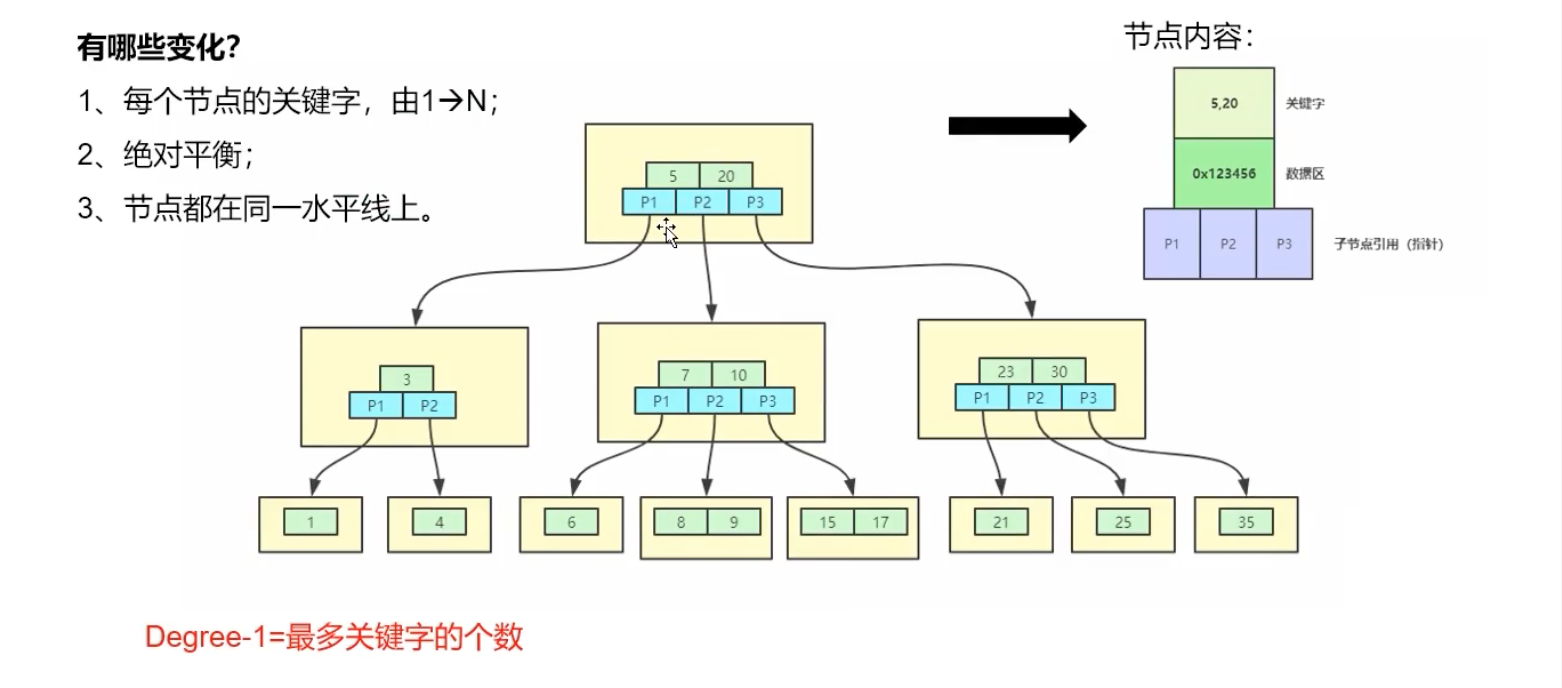
(4)、B+Tree(B加树)
1 | 1,28,66 的数据区划分 |
P1、P2、P3 都是一个 Page(页) => 16KB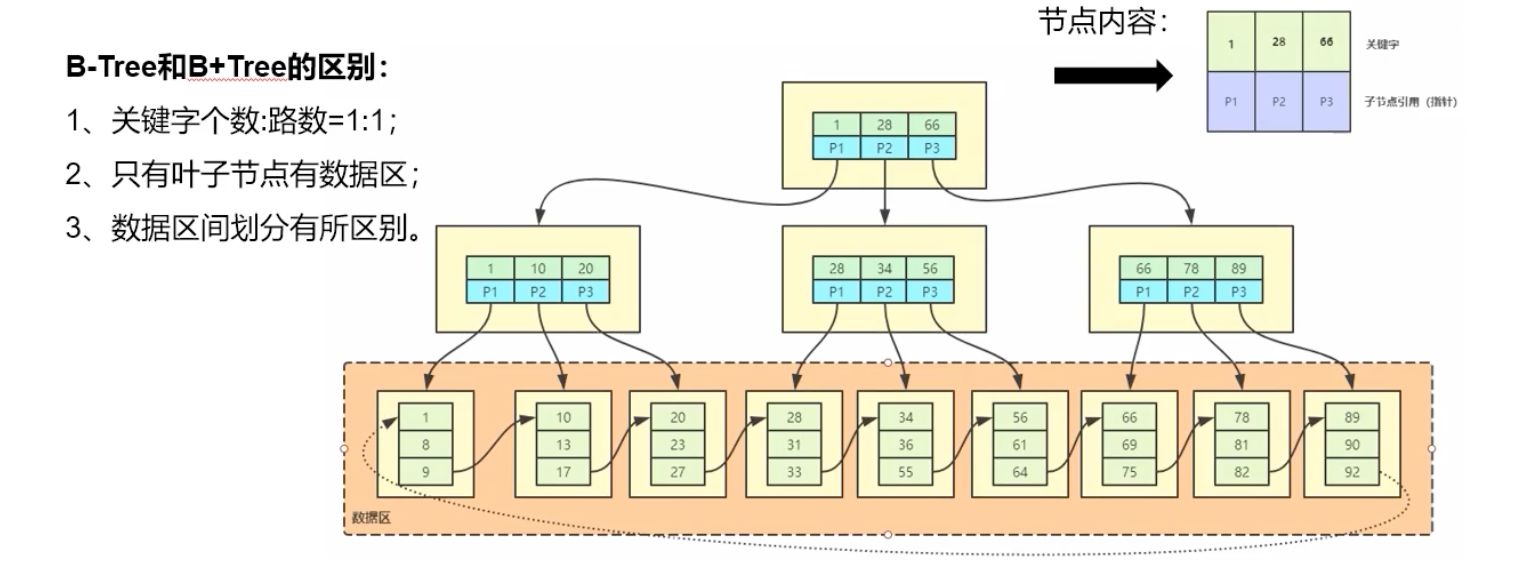
(5)、联合索引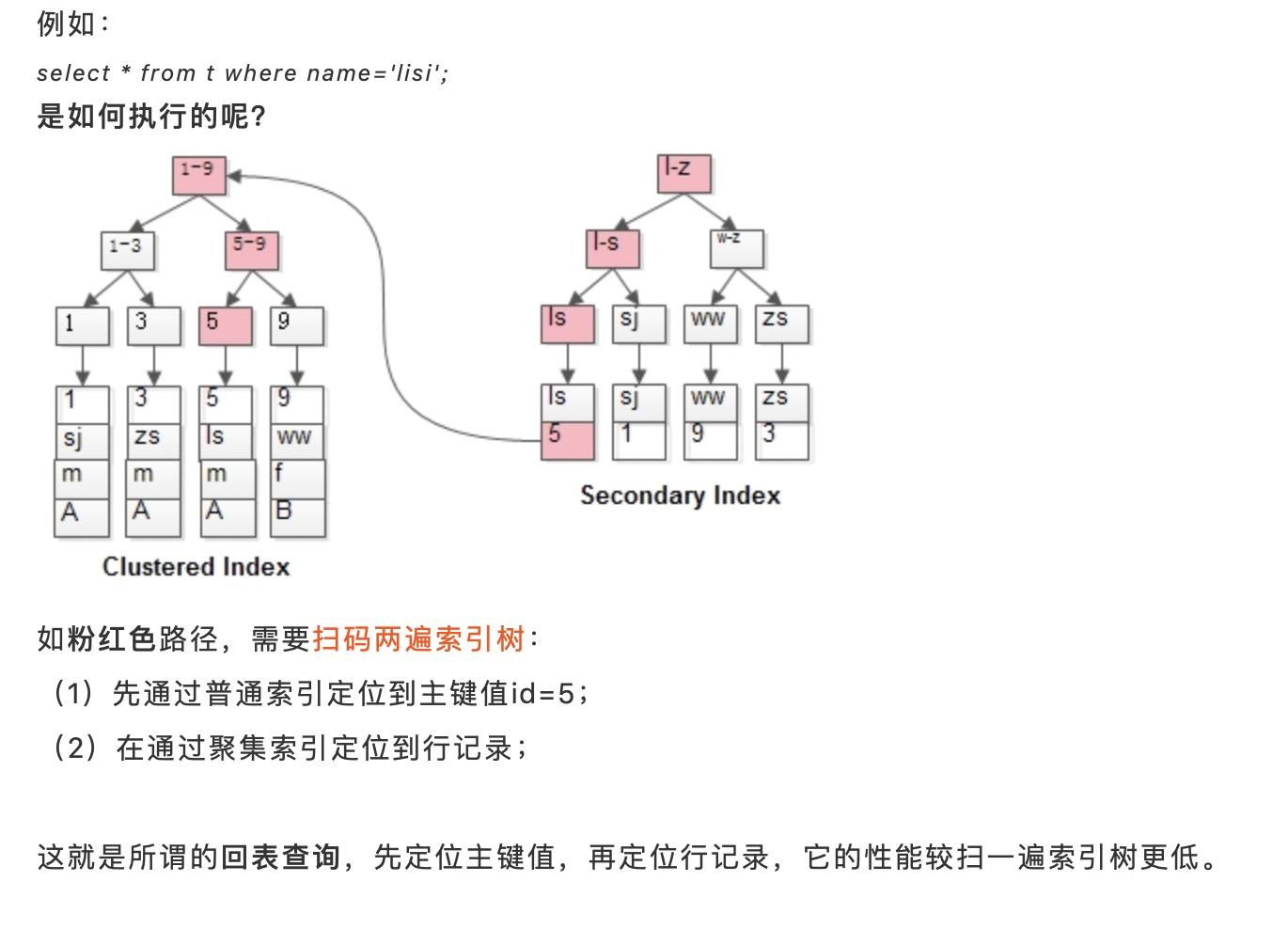
InnoDB 页大小默认 16KB
每次取数据都要取 16KB。
Myisam索引结构
在 .myi(my index) 找到地址,根据地址去 .myd(my data) 文件中找数据。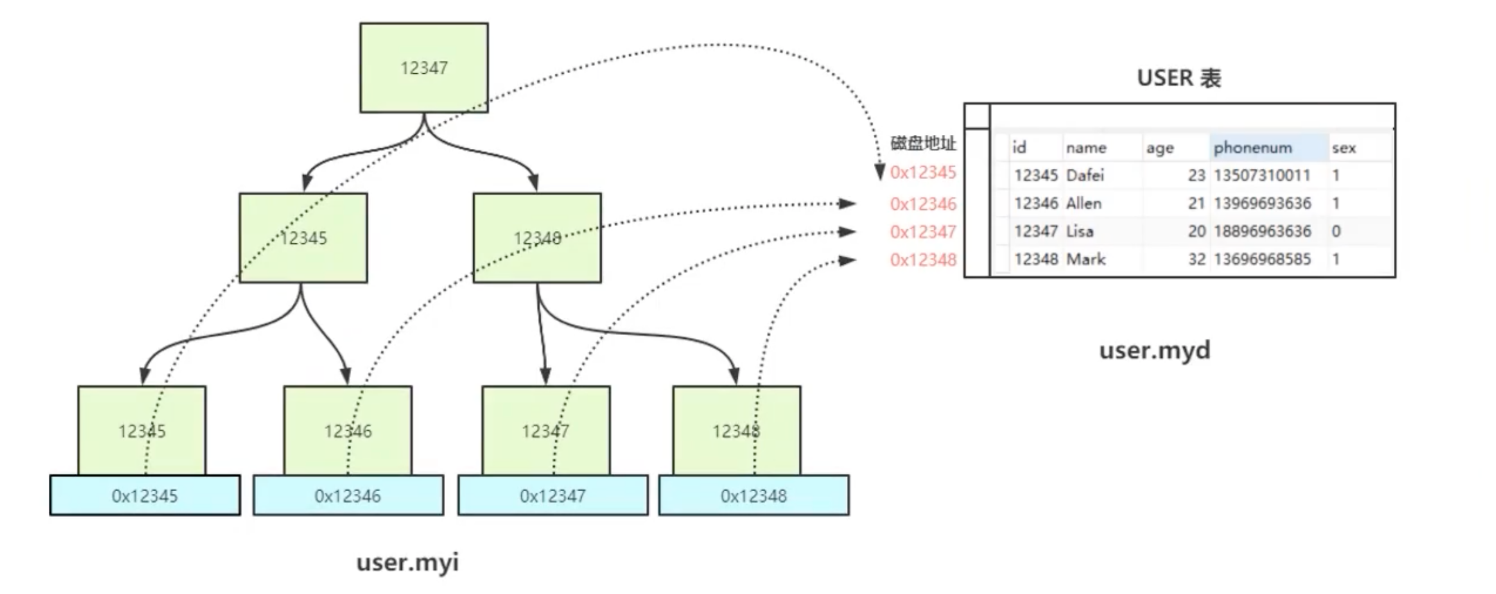
myisam 的主键索引(ID索引)与 非主键索引(NAME索引):功能与数据结构都是一致的。
都是从自己的 .myi 中找到地址,根据地址去 .myd 文件中查找数据。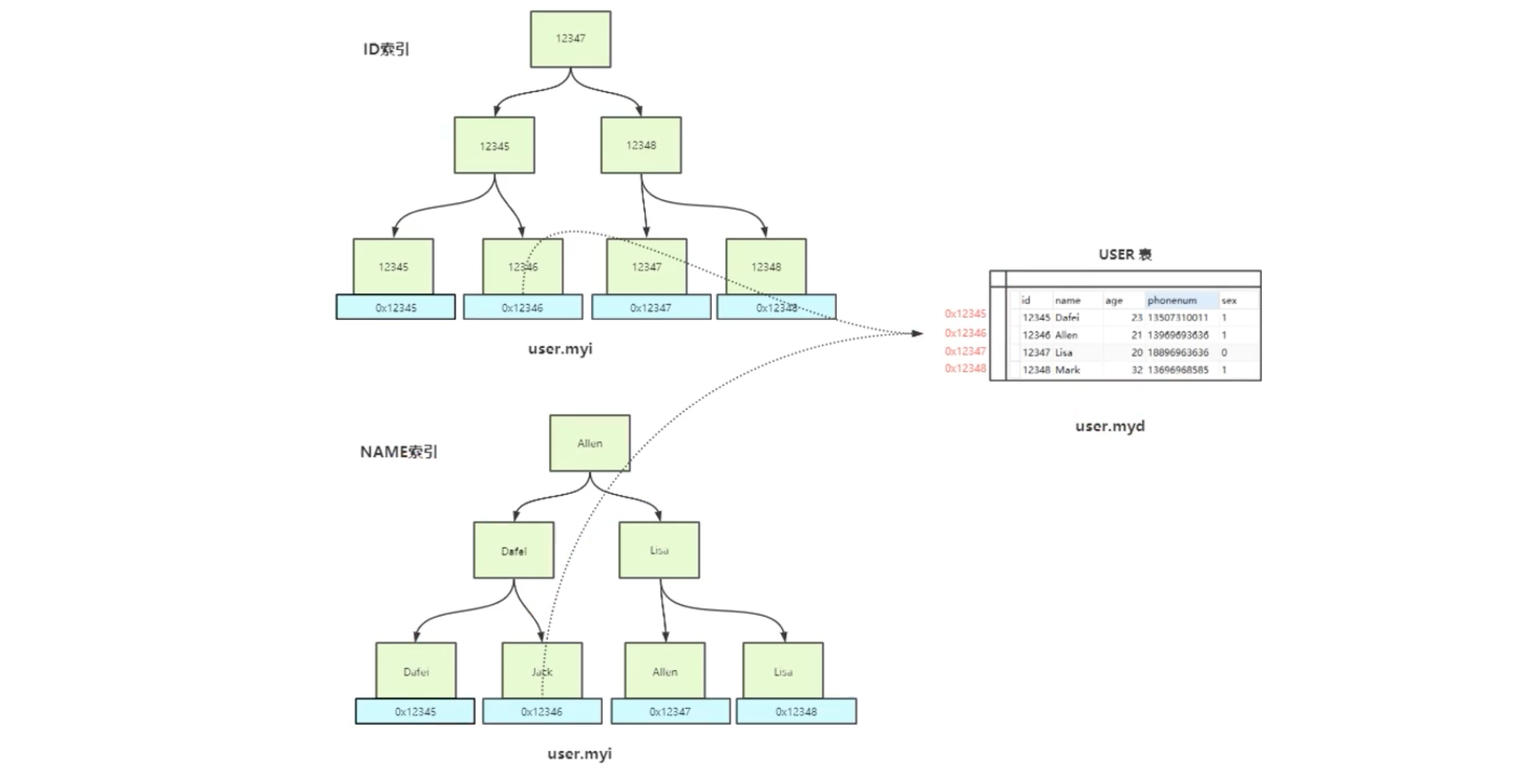
InnoDB索引结构
叶子节点存储的不再是地址值,而是真正的数据。
.ibd(InnoDB data),把主键索引和数据二合一了。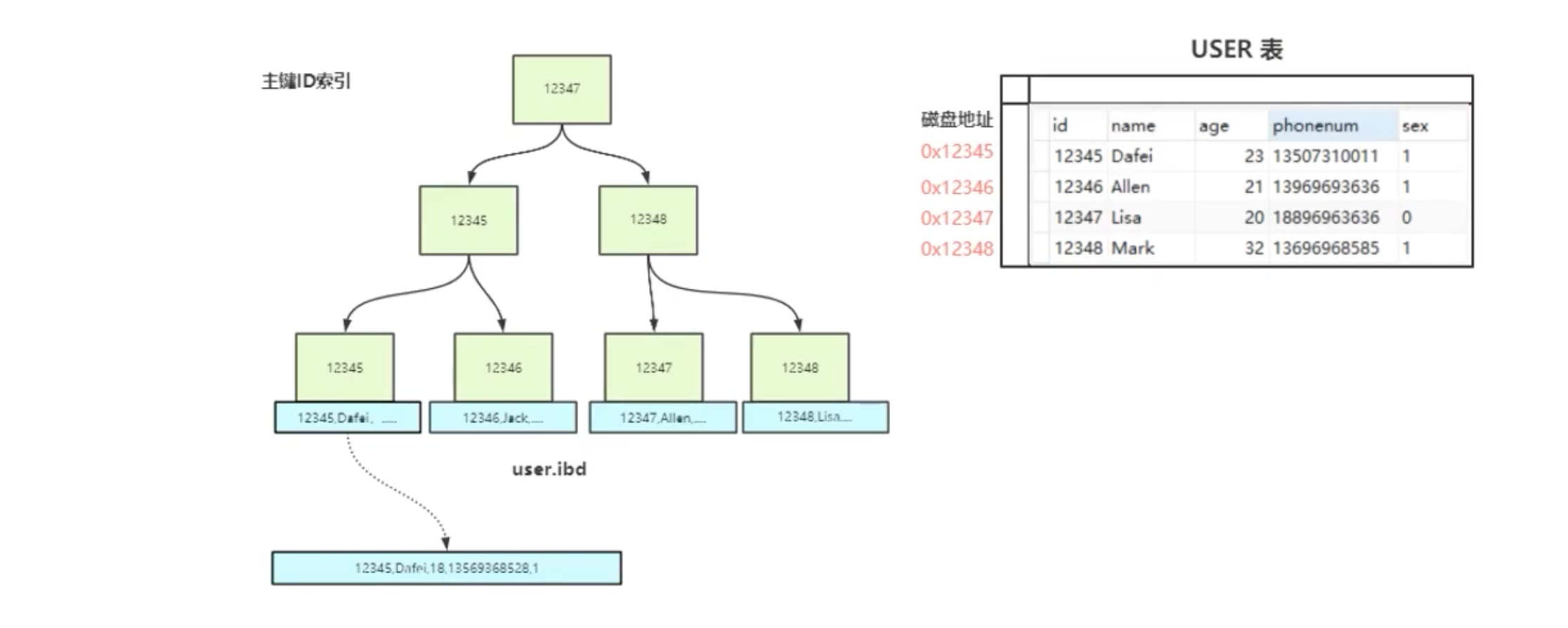
非主键索引与主键索引不同。非主键索引的叶子节点存放的并非数据,而是主键索引的值。要获取数据的时要,会再根据主键索引的值来遍历主键索引树,查找到数据。也就是一个”回表“的过程。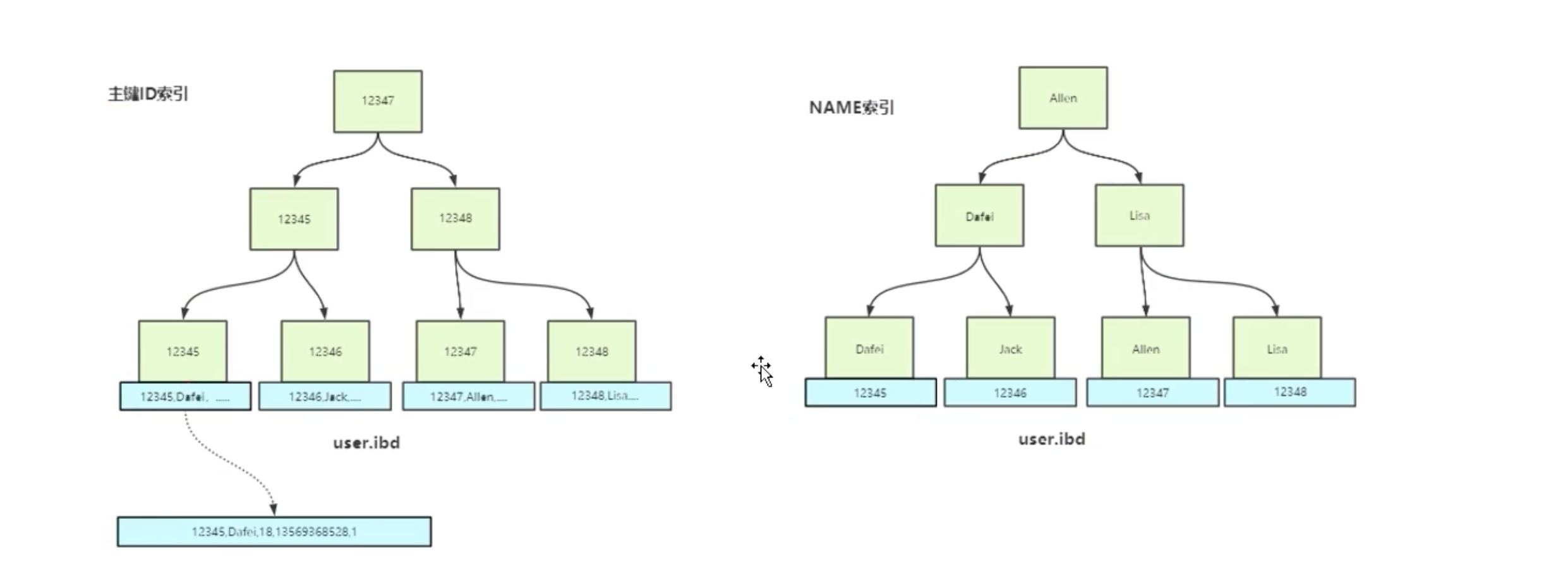
聚集索引
可以参考:15.6.2.1 Clustered and Secondary Indexes
索引字段的离散型

答:”姓名“。
为什么?
离散性越好的列作为索引。离散性:count distinct col : count col。这什么意思?例如年龄就是2:8。一个列,重复的越少,越好作为索引。
例如:下面以离散性最差的作为索引,看有什么影响。查找 1 的时候,会把所有为 1 的都查询出来。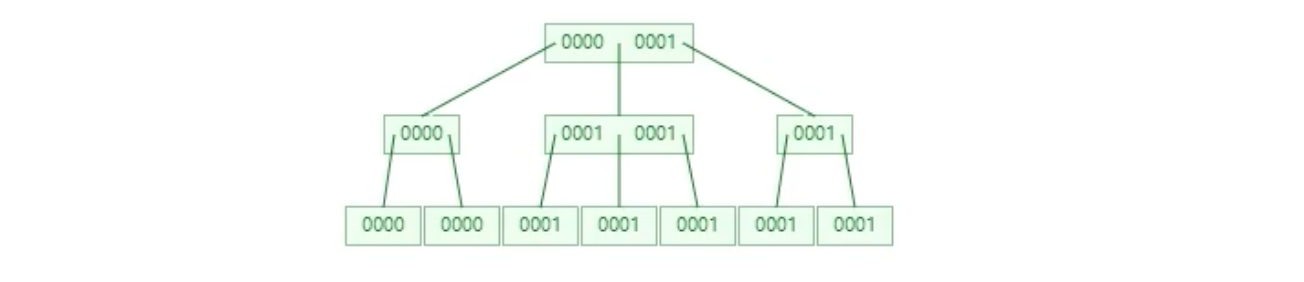
创建单索引、联合索引

联合索引,就是 name 相同,再按照 phoneNum 进行查找,phoneNum相同的话再按照 age 进行查找。
若查找条件没有 name 的话,就不会使用此索引。这被称为”最左前缀原则“
思考1:怎样创建索引
问:对于下面两个经常要查询的语句,建立索引。给出三种方案,哪个最优?
A、建立 (name)
B、建立 (name,phoneNum)
C、建立 (name) 和 (name,phoneNum)
答:”B、建立 (name,phoneNum)“。
因为第二个 SQL用到 phoneNum,所以 A 不太特别支持。因为建立了 B 就包含了 A,没必要再建立 A 了,会造成浪费。
思考2:索引一样吗
问:下面两个索引一样吗?
答:不一样。因为最左前缀原则,比较顺序是不一样的。所以,它们两个是完全不一样的索引树。
思考3:是否用到索引
下面四个 SQL 有没有用到联合索引,用到几列,未用到几列,为什么?
1 | # SQL1:用到两列,name,phoneNum。 |
MySQL逻辑架构图
存储引擎就是 myisam,InnoDB,memory。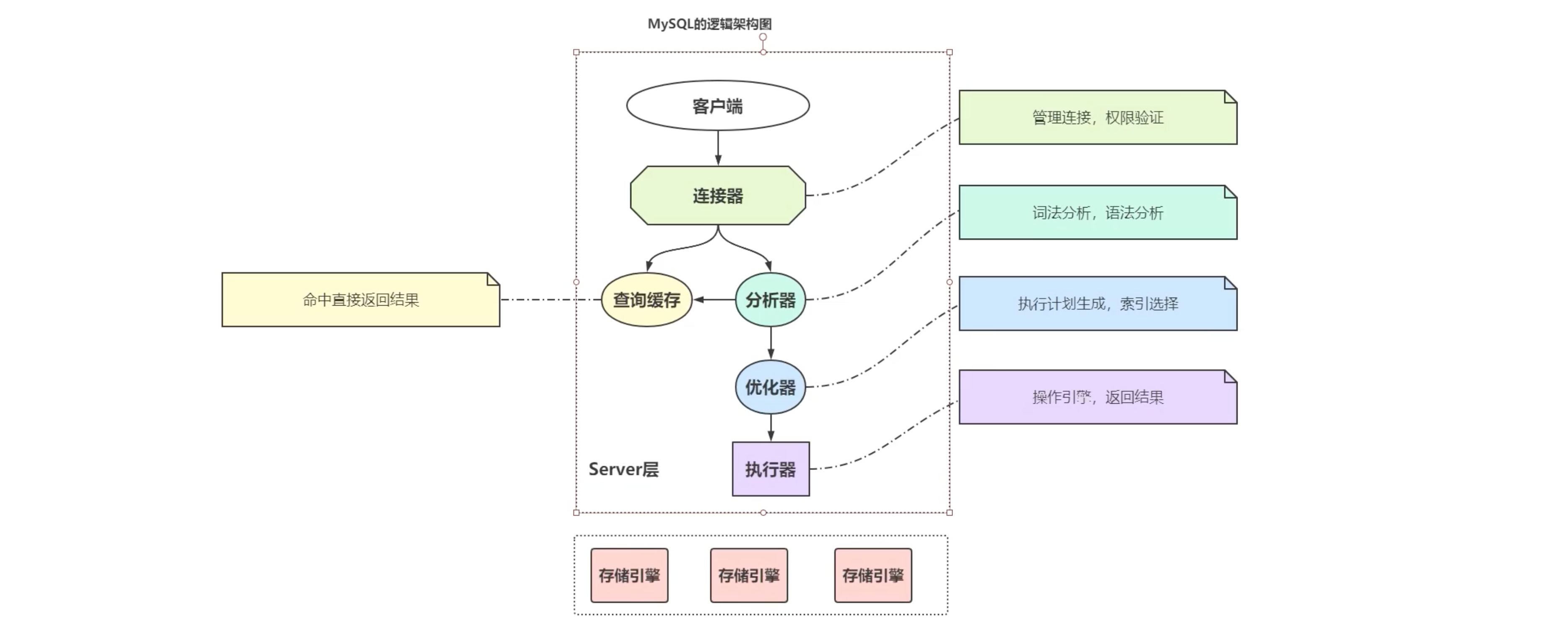
思考4:哪个执行效率高

答案:”4“
1 | # 1:遍历两个索引:唯一索引,主键索引 |
覆盖索引
覆盖索引无需回表。(可参考上面的 思考4 的 SQL 4 就是覆盖索引)
最左前缀原则
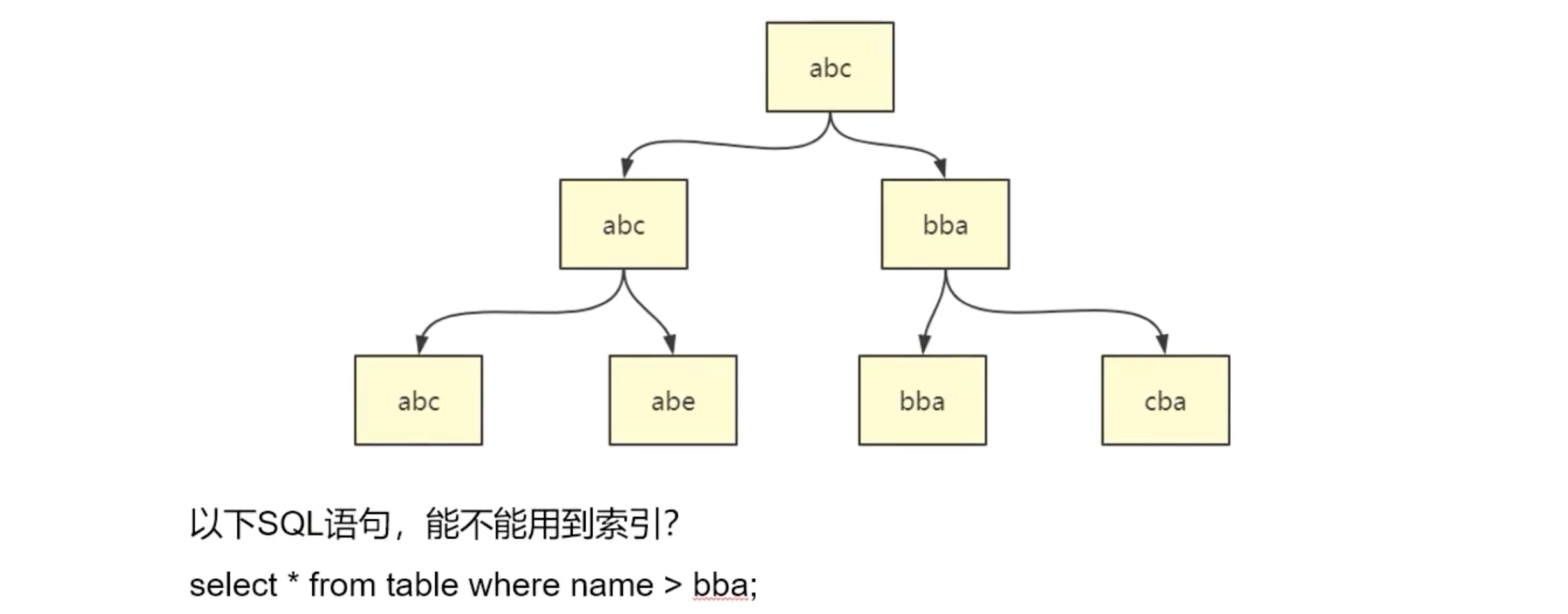
答:会用到索引。
为什么呢?
因为内部会把进行 ASCII 码转换。a=97,b=98,c=99。bba=989897,bbc=989899。
假设有索引 panfeng1,panfeng2,panfeng3,… ,panfeng999。
我使用 like ‘panfeng%’ 就不会加速我们的查询,因为此时的离散性,选择性是极差的。
所以,对应上面的问题1 是需要根据业务进行考量。如果离散性好的话会根据最左前缀原则用到索引。
三星索引

对于 1: 没什么好说的。
对于2:默认就是有序的,根据主键排序(order by id)。但如果你在 SQL 写了(order by name),则会进行二次排序,效率降低。
对于3:在上面提到了,避免回表。
and or union
1 | 主键索引:id |
索引下推
1 | icp:index condition pushdown |
隐藏主键
我们都会听说 MySQL 一定要自己创建主键。
如果没有创建主键索引的话,MySQL 默认会为我们创建一条主键索引 rownum。
1 | 1、int 4byte。默认主键索引 6byte。。。资源浪费 |
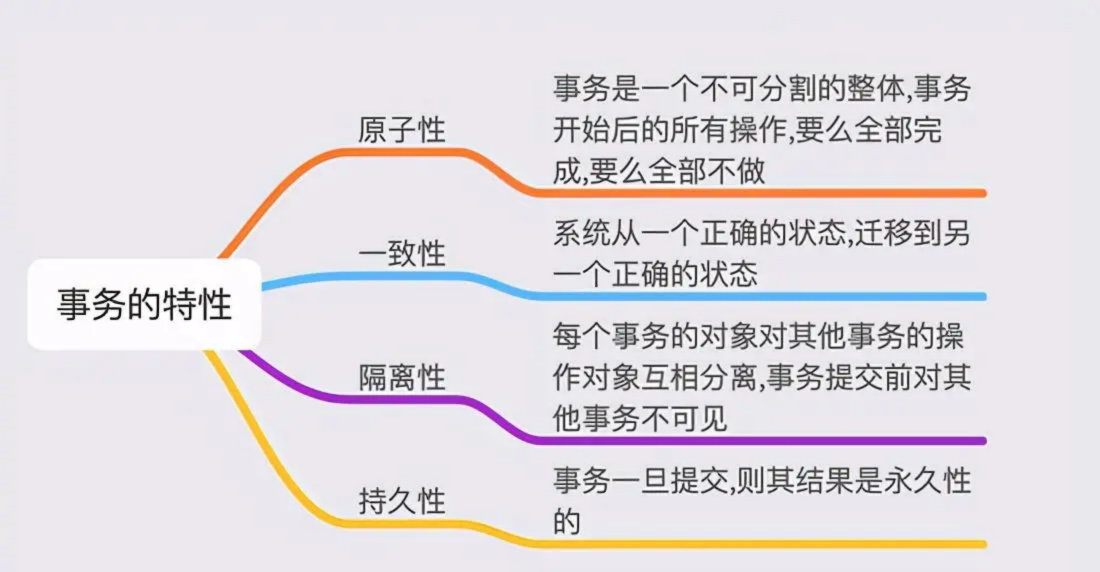
事务四大特性(ACID)
兄弟,你要想深入学习,可以参考:MySQL 事务的 ACID 原理
1 | 原子性 Atomicity |
脏、不可重复、幻
事务并发的问题
- 脏读:读取了其他并发事务未提交的数据。
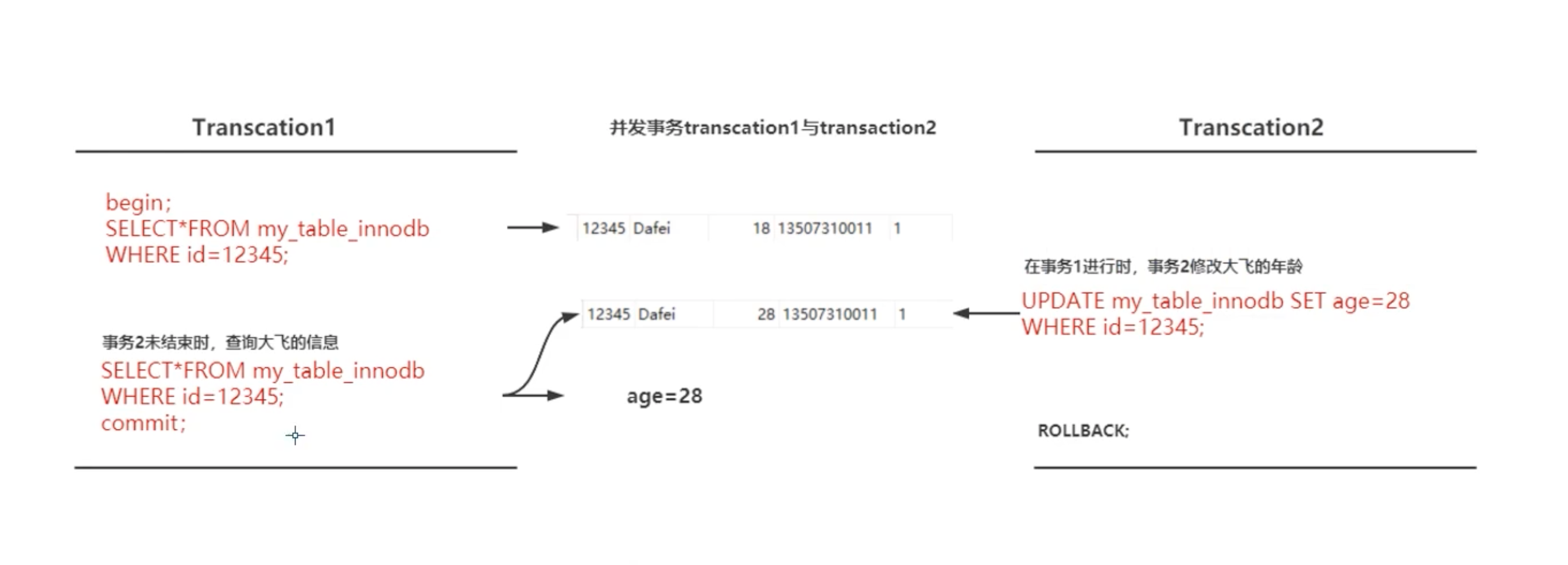
- 不可重复读:读取了其他并发事务提交的数据。针对 update 和 delete 。
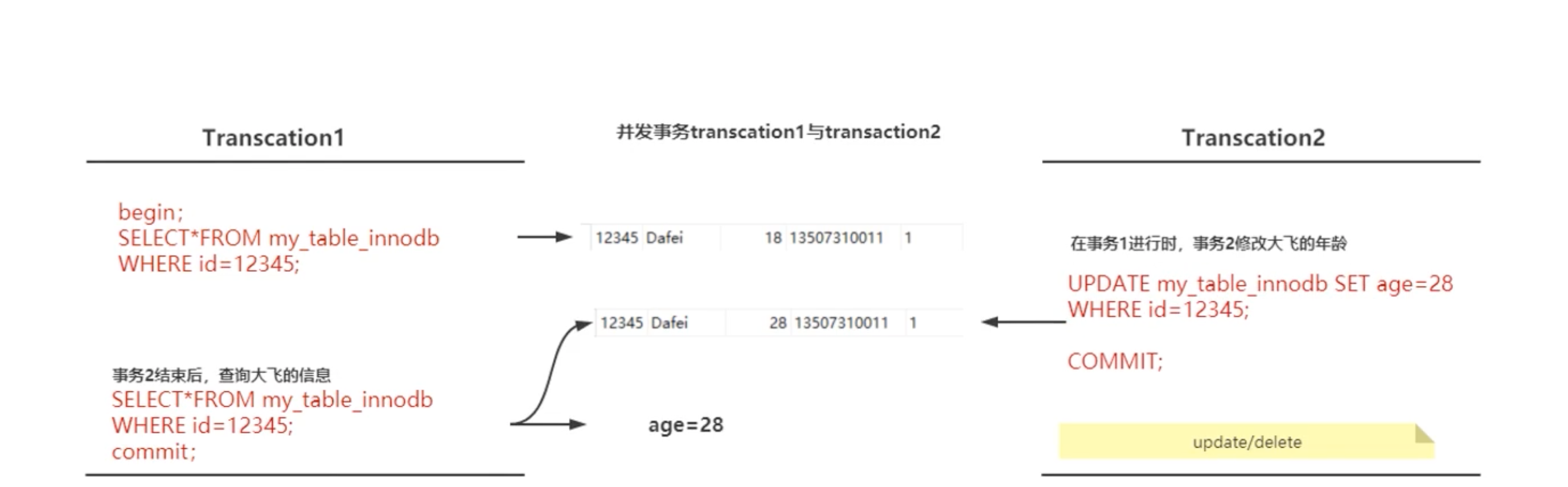
- 幻读:读取了其他并发事务提交的数据。针对 insert 。
15.7.4 Phantom Rows — 官方文档
幻读:MySQL 官方称为“虚拟的行”。声明一下,幻读在可重复读的模式下被 MySQL 5.5后解决了,使用 MVCC 快照读,不会出现两次读取不一样的情况。
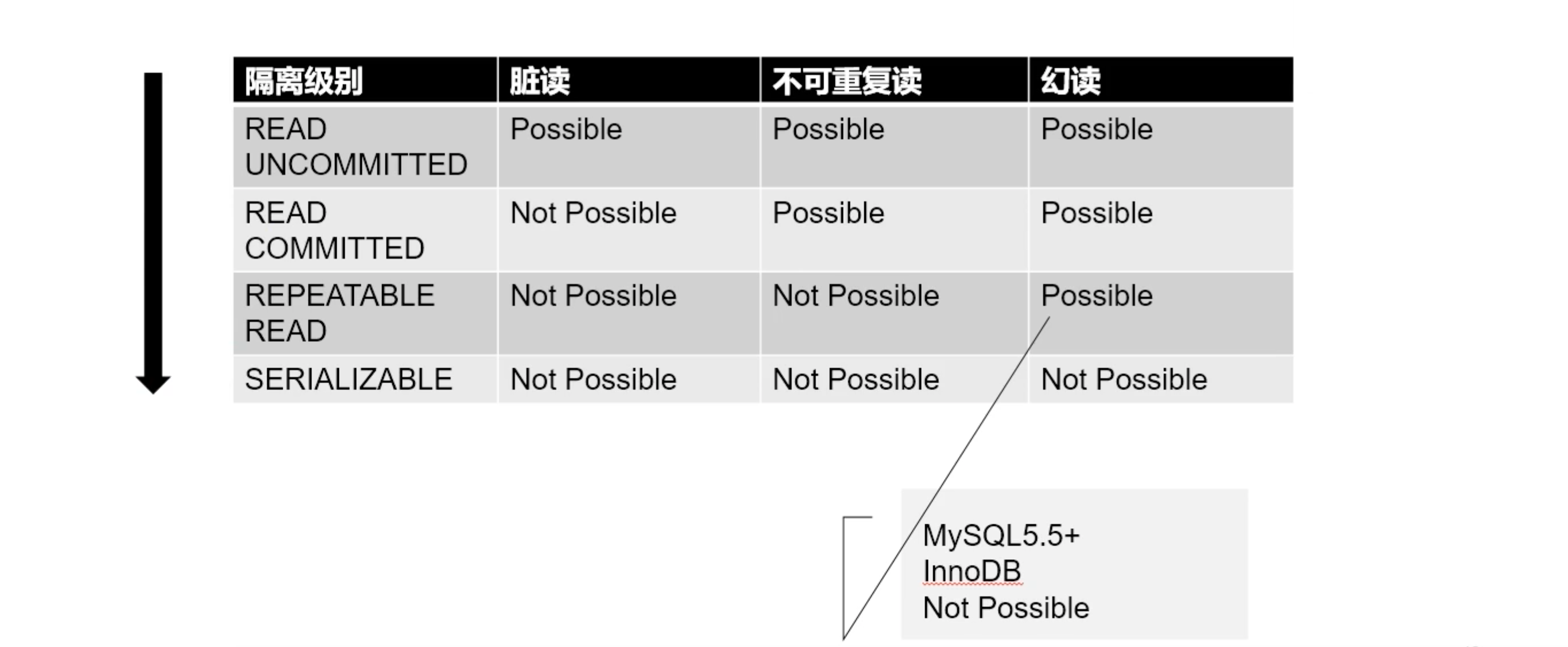
事务隔离级别

RC:READ COMMITTED 读已提交(Oracle 默认事务隔离级别)
RR:REPEATABLE READ 可重复读(MySQL 默认事务隔离级别)
READ UNCOMMITTED:读未提交 ===> 一般没人使用,因为它接不了脏读、不可重复读、幻读。
SERIALIZABLE:串行化 ===> 可以想象成,你发送给 MySQL 的 SQL 语句,它内部在 for 循环执行,而不是并行执行的。所以会拉低效率,一般都不采用这种方式。你也可以想象成:有很多个坑位,但是呢,你只允许来的人使用 1号坑位,人很多也要等前面人解决完事,你再进行解决,不能同时进行。(哇,这句话好大的味道。)
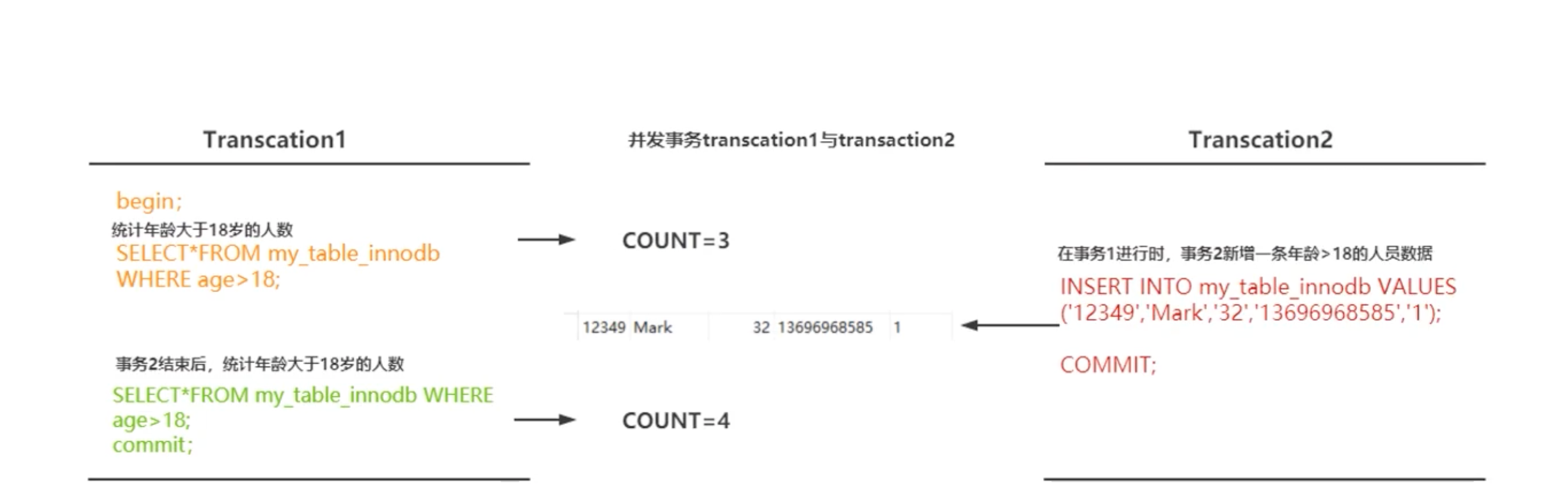
RR、RC结果
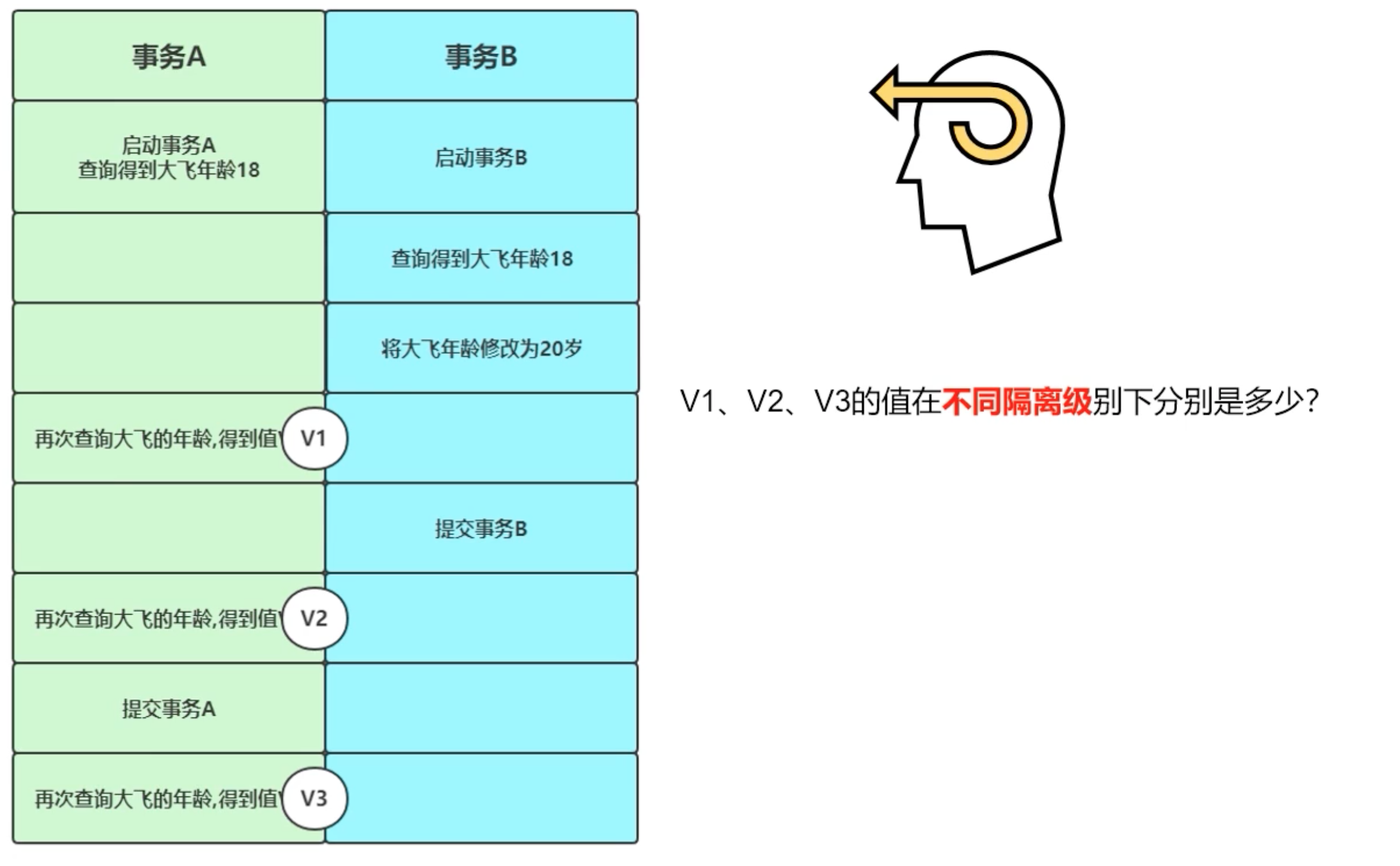
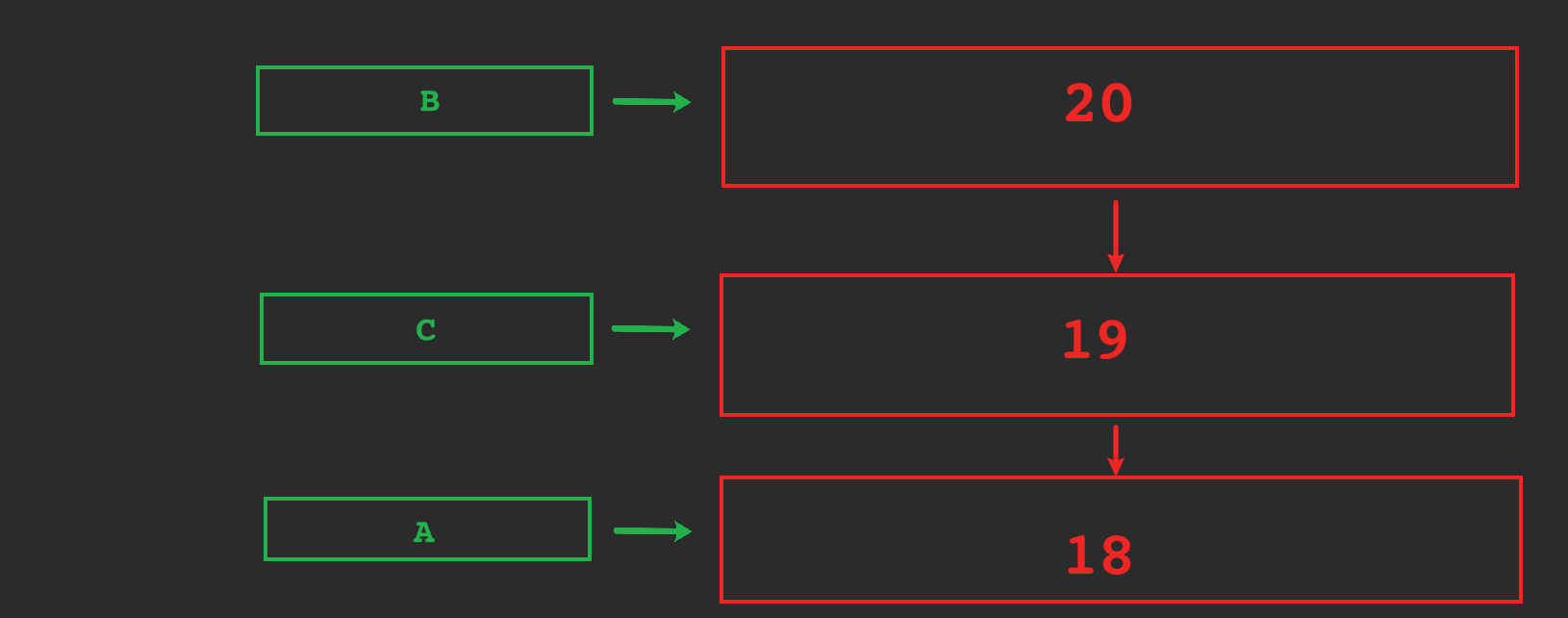
RC:V1=18,V2=20(别人已经提交,会触发我事务内的改变),V3=20
RR:V1=18,V2=18(即使别人已经提交,因为我是可重复读,所以不会触发我事务内的改变),V3=20
LBCC MVCC
1 | LBCC:Lock-Based Concurrent Control 基于锁并发控制 |
并发事务的隔离就是用这两个(LBCC + MVCC)来实现的,现在知道了吧,下面来具体阐述。
InnoDB Locking
15.7.1 InnoDB Locking 官方文档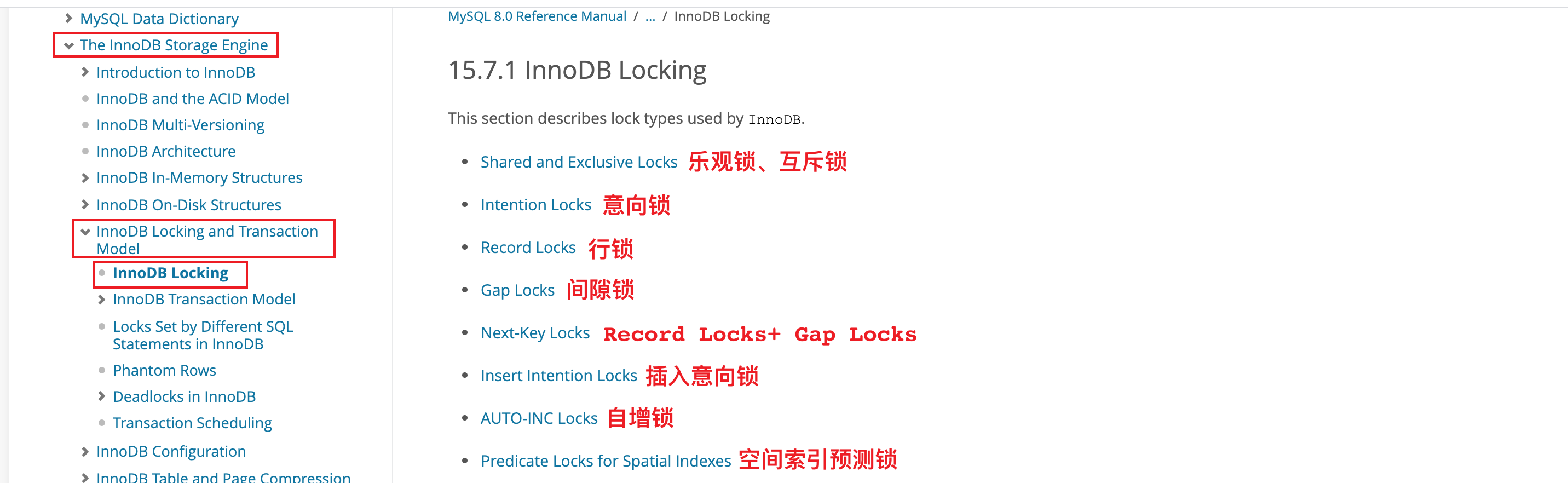
注意:这些锁是互相有交集的。什么意思?比如:我可以是男的,也可以是 Java开发。
锁:又分模式(思想),和算法(实现)。下面来分开进行讲解。
先上一张图,让你明白锁模式,和锁算法。

再上一张图,让你明白这些锁的分支、含义。先了解一下,下面来阐述为什么有这些东西。
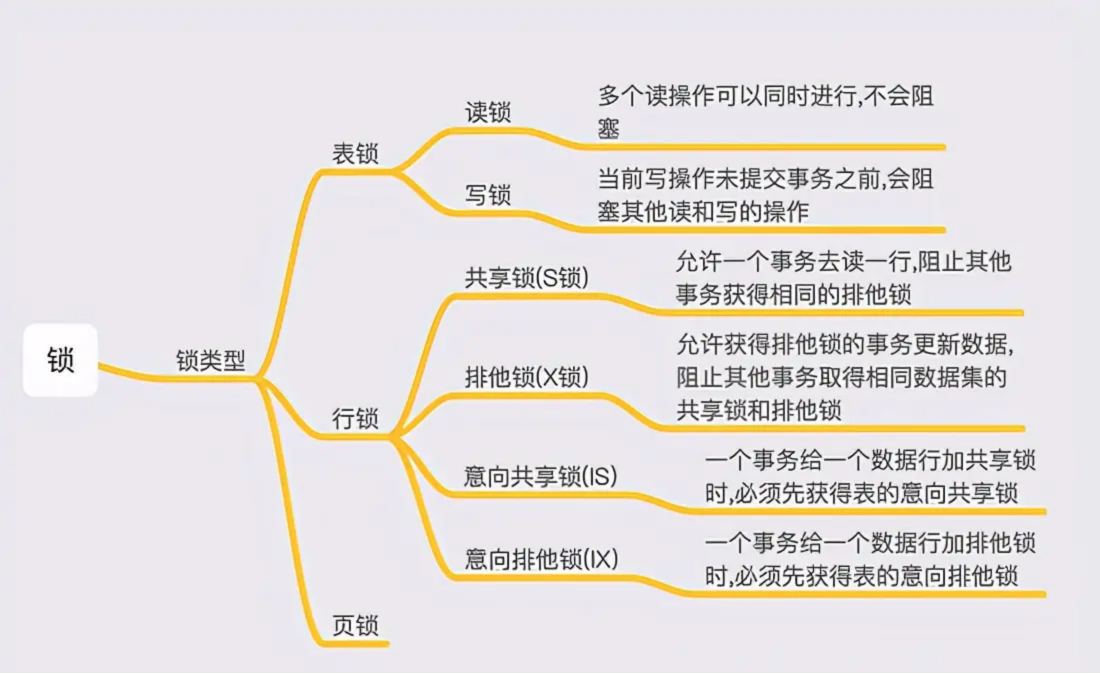
锁的模式
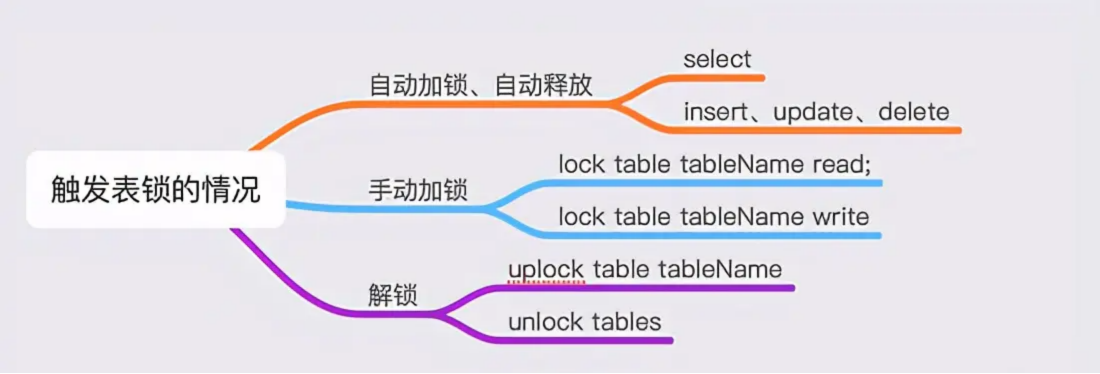
表锁、行锁
1 | 表锁与行锁的区别: |
这些不用说,简单也可以理解,那怎么触发呢?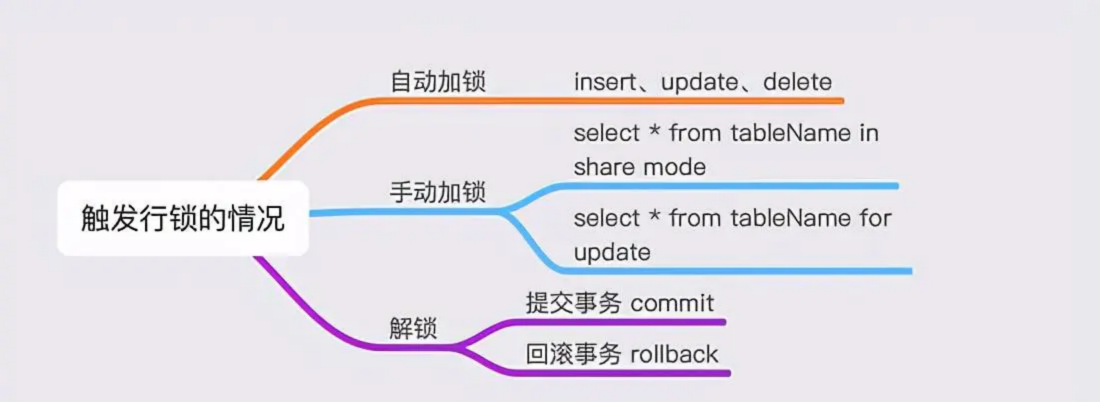
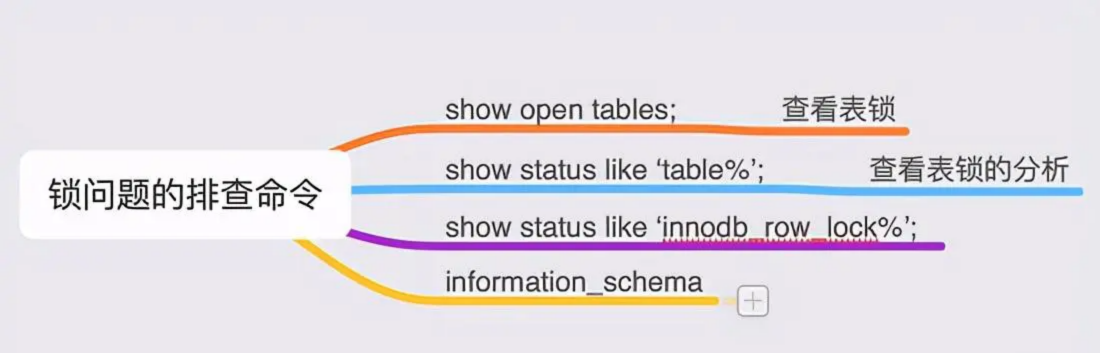
锁的排查指令
共享锁

你可以想象成进出动物园的过程:每个人都可以进动物园(开启共享锁),但是要把动物放出来(修改数据),就需要所有人都出动物园(关闭共享锁)。
排它锁

意向锁
了解即可。不是我们手动控制的,而是 MySQL 内部自己的处理逻辑。
你表中任何一行加了 共享锁 或 排它锁,意向锁这盏灯都会亮。
表中任何一行都没加 共享锁 或 排它锁,意向锁这盏灯才会灭。
为什么要加入意向锁?
要进行表锁的时候,判断意向锁这盏灯是否亮起即可,不用每一行都进行遍历。
锁的算法
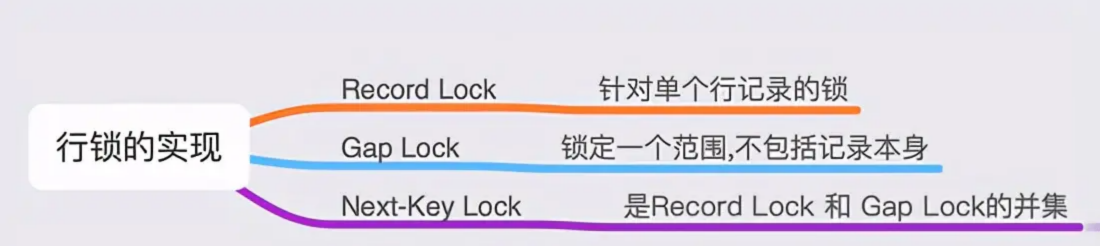
锁的区间
临键 = 记录 + 间隙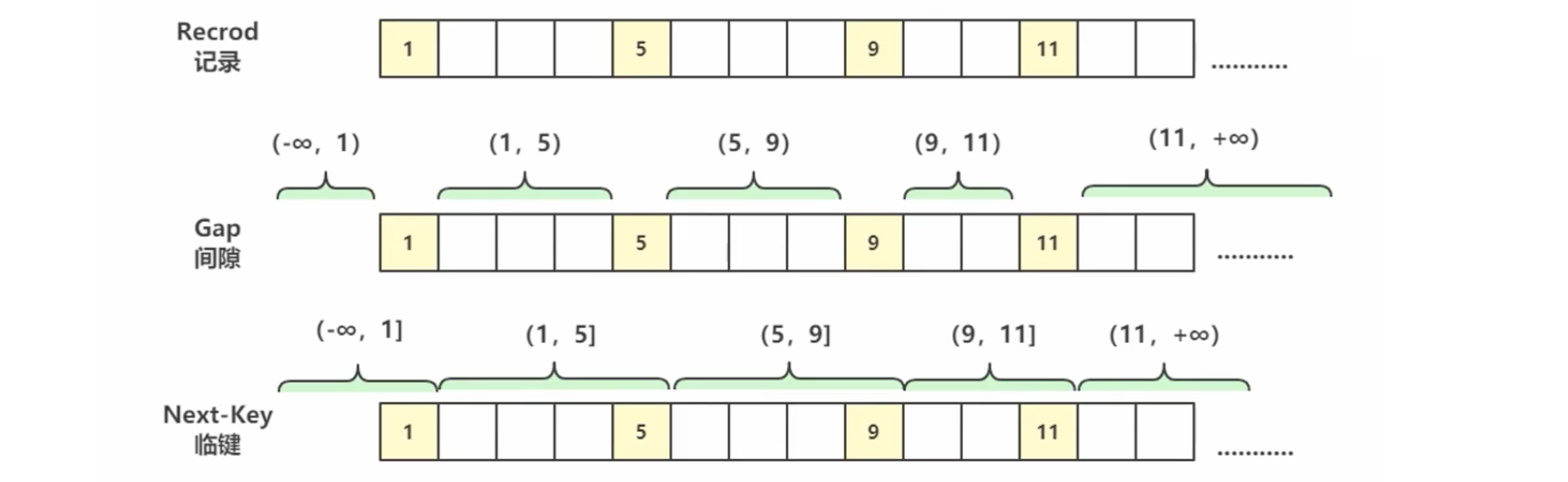
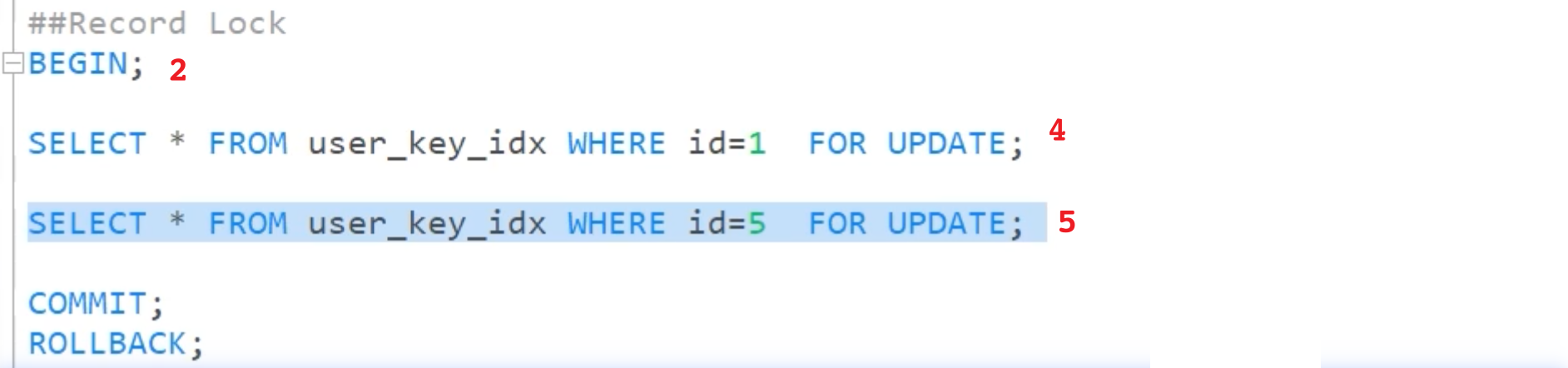
记录锁

例如:下面 4 会一直阻塞,等待事务1 进行提交或回滚。此时暂停,执行 5 则可以成功。
间隙锁
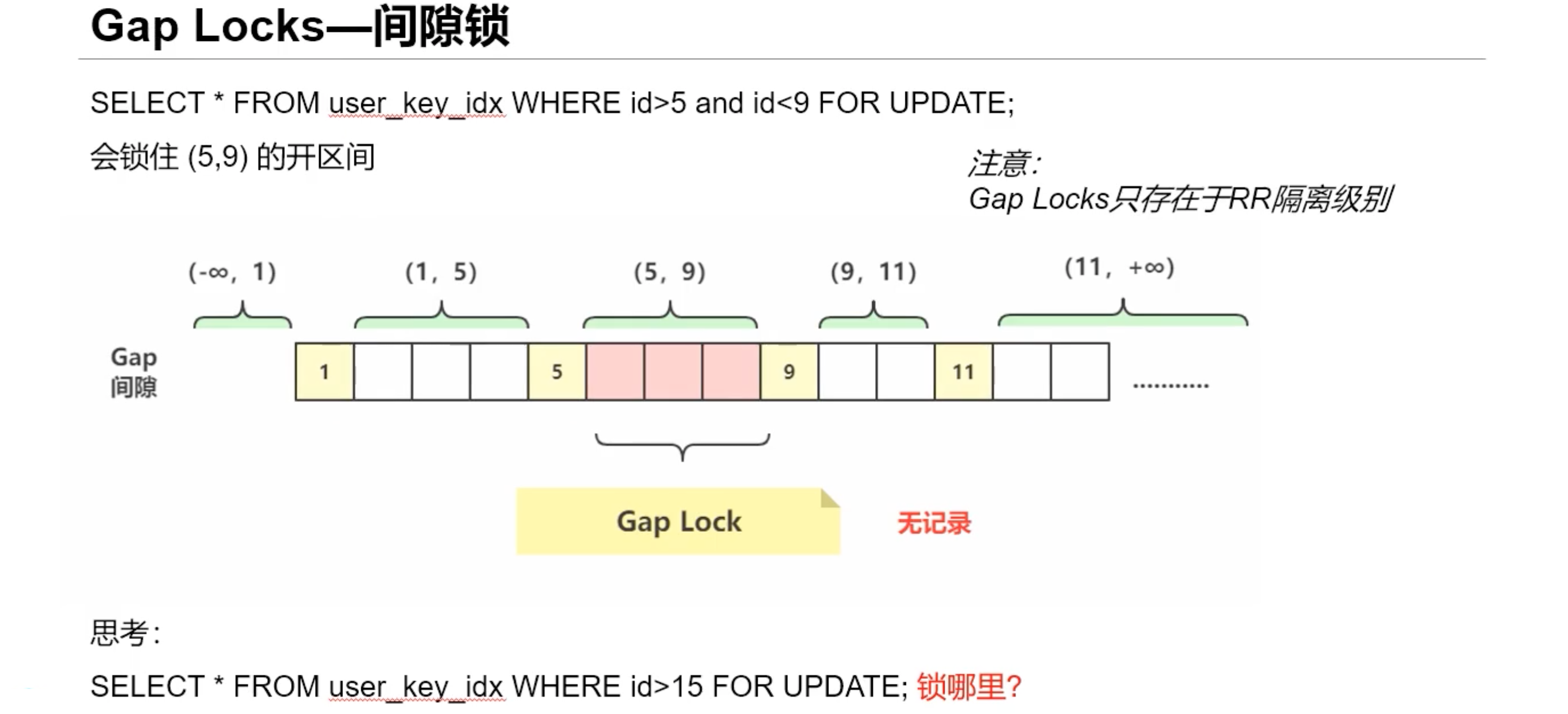
答:id>15 for update 会锁 (11,+∞) 这个范围。
数据库中只有 1,5,9,11 四条记录。
事务1、2都开启事务。
事务1 执行 id>15 for update 之后,但未提交,也没回滚。
此时,事务2执行 insert into 插入 12,13,14,15,16,17,18,19,20,。。。 都会阻塞。
对于下面,开启事务1、事务2:
(1)、执行了1、2、3,再执行4的时候会阻塞,暂停4,再执行5的时候不会阻塞。
(3)、执行了1、2、6,再执行 7 或 8 都会阻塞。因为间隙锁是以真实的数据记录进行划分区间的,这里 id>15 命中了(11,+∞) 这个范围,而13、20都属于 这个范围,所以效果是一样的,都会被阻塞。

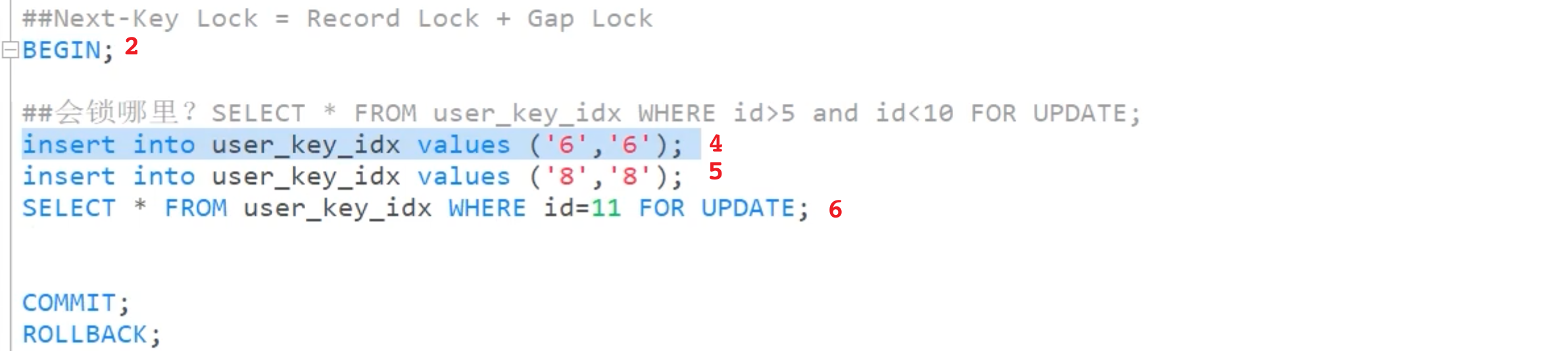
临键锁

如下:
(1)、执行1、2、3之后,再执行 4 或 5 都会失败。
(2)、执行1、2、3之后,再执行 6 也会失败。
为什么呢?
因为 id>5 and id<10 for update 命中的是 (5,9] (9,11] 的并集,也就是(5,11] 。所以,这个范围包含了 6,8,11。
插入意向锁
插入意向锁在上面已经演示过了,也可以参考官方文档:插入意向锁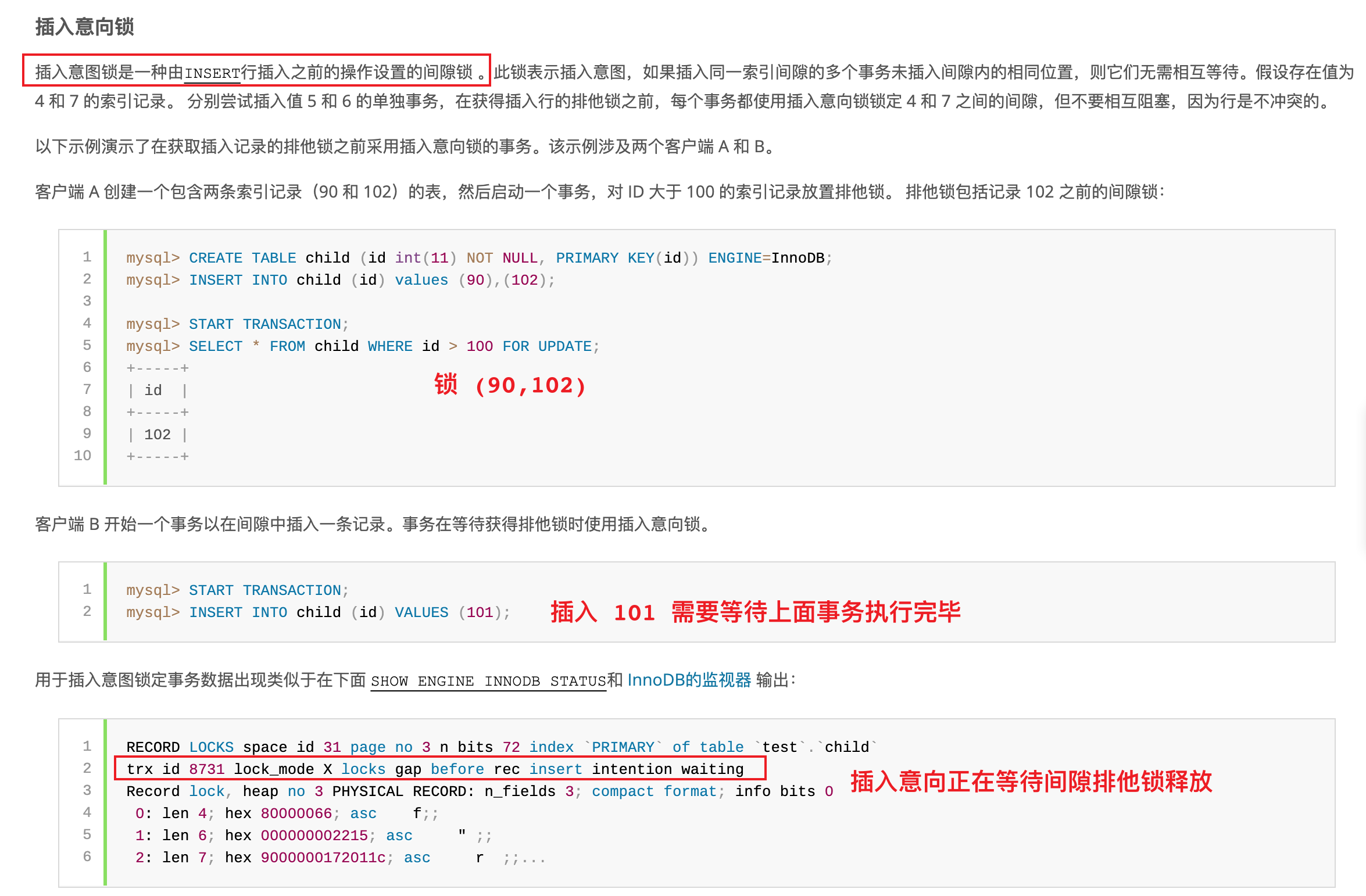
自增锁

开启两个事务:
对于一个空表,事务1插入两条数据,事务2插入两条数据。
理想是事务1插入主键(1、2),事务2插入主键(3、4)。
但可能存在跳票的问题:事务1插入主键(1、4),事务2插入主键(2、3)。
改为 0 的话,会出现锁表的情况,会拉低高并发的性能。
====================
参考官方文档:
AUTO-INC Locks
15.6.1.6 InnoDB 中的 AUTO_INCREMENT 处理innodb_autoinc_lock_mode 变量 有三种可能的设置 。设置为 0、1 或 2,分别表示 “传统”、“连续”或 “交错”锁定模式。
从 MySQL 8.0 开始,交错锁模式 ( innodb_autoinc_lock_mode=2) 是默认设置。
在 MySQL 8.0 之前,连续锁定模式是默认的 ( innodb_autoinc_lock_mode=1)。
当前读、快照读
在MySQL默认隔离级别下,假设原本 age=18 ,执行结果 Q1 = ? Q2 = ?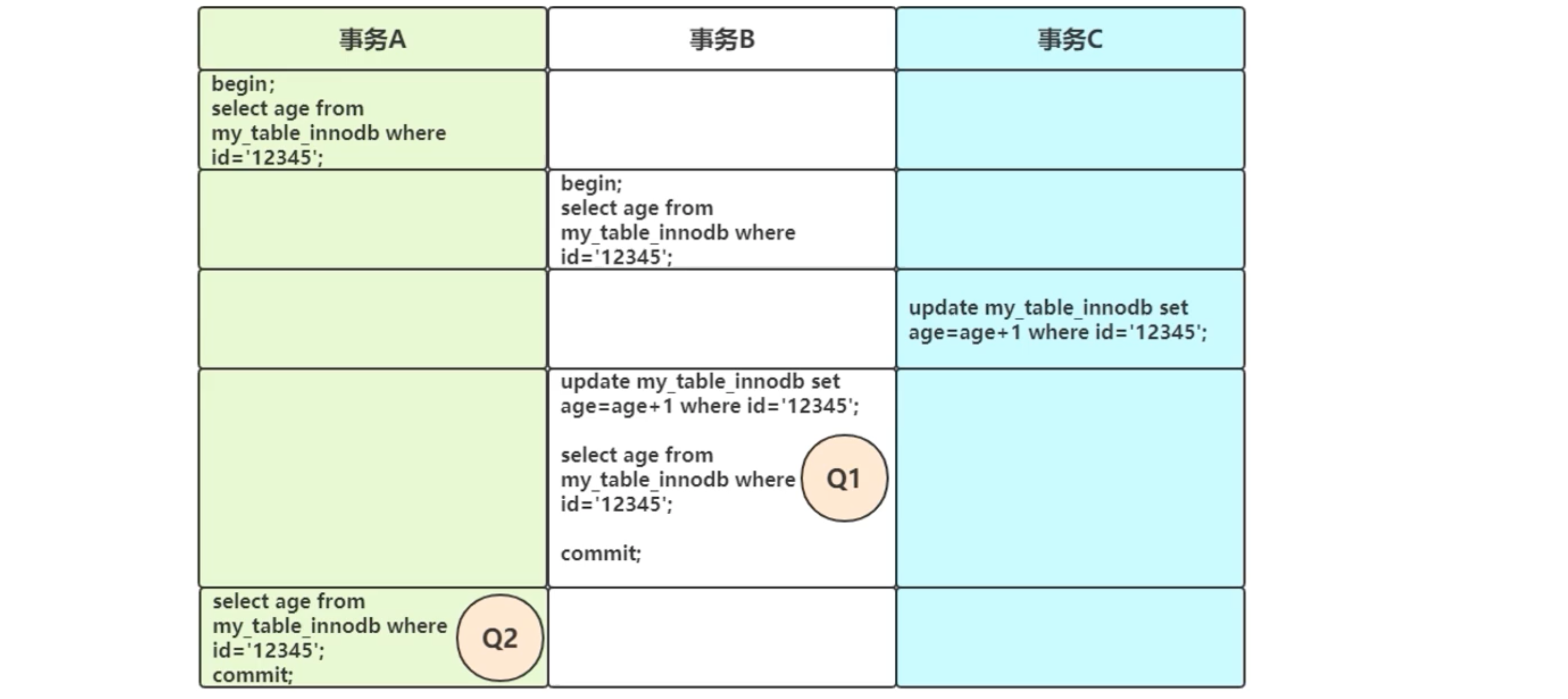
答:Q1=20,Q2=18。为什么?这是快照读,当前读的区别。
当前读
像select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁快照读
像不加锁的select操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本。
说白了MVCC就是为了实现读-写冲突不加锁,而这个读指的就是快照读, 而非当前读,当前读实际上是一种加锁的操作,是悲观锁的实现。
开启事务建立快照
start transaction 等同于 begin。
start transaction 和 start transaction with consistent snapshot
事务开始时间点,分为两种情况:
1)start transaction 时,是第一条语句的执行时间点,就是事务开始的时间点,第一条select语句建立一致性读的snapshot;
2)start transaction with consistent snapshot 时,则是立即建立本事务的一致性读snapshot,当然也开始事务了;
幻读解决方案
通过上面所说的快照读,当前读来解决的。