源码:点击查看
下面会分三部分进行讲解
1、
==> zookeeper简介
==> zookeeper数据模型
==> zookeeper单机安装
==> zookeeper常用shell命令
==> zookeeper的Acl权限控制
==> zookeeper的javaApi
2、
==> zookeeper 事件监听机制
==> zookeeper 集群搭建
==> 一致性协议:zab协议
==> zookeeper的leader选举
==> observer角色及其配置
==> zookeeperAPI连接集群
3、
==> zookeeper 开源客户端curator介绍
==> zookeeper四字监控命令
==> zookeeper图形化的客户端工具(ZooInspector)
==> taokeeper监控工具的使用
zookeeper简介
zookeeper是什么
zookeeper官网:https://zookeeper.apache.org/
zooKeeper由雅虎研究院开发,是Google Chubby的开源实现,后来托管到 Apache,于2010年11月正式成为Apache的顶级项目。
大数据生态系统里的很多组件的命名都是某种动物或者昆虫,比如hadoop就是 🐘大象,hive就是🐝蜜蜂。
zookeeper即动物园管理者,顾名思义就是管理大数据生态系统各组件 的管理员,如下图所示:
zookeeper应用场景
zooKeeper是一个经典的分布式数据一致性解决方案,致力于为分布式应用提供一 个高性能、高可用,且具有严格顺序访问控制能力的分布式协调存储服务。
- 维护配置信息
- 分布式锁服务
- 集群管理
- 生成分布式唯一ID
1、维护配置信息
java编程经常会遇到配置项,比如数据库的url、schema、user和password 等。通常这些配置项我们会放置在配置文件中,再将配置文件放置在服务器上当需要更 改配置项时,需要去服务器上修改对应的配置文件。但是随着分布式系统的兴起,由于 许多服务都需要使用到该配置文件,因此有必须保证该配置服务的高可用性(high availability)和各台服务器上配置数据的一致性。通常会将配置文件部署在一个集群上, 然而一个集群动辄上千台服务器,此时如果再一台台服务器逐个修改配置文件那将是非 常繁琐且危险的的操作,因此就需要一种服务,能够高效快速且可靠地完成配置项的更 改等操作,并能够保证各配置项在每台服务器上的数据一致性。
zookeeper就可以提供这样一种服务,其使用Zab这种一致性协议来保证一致
性。现在有很多开源项目使用zookeeper来维护配置,比如在hbase中,客户端就是连接 一个zookeeper,获得必要的hbase集群的配置信息,然后才可以进一步操作。还有在开 源的消息队列kafka中,也使用zookeeper来维护broker的信息。在alibaba开源的soa框 架dubbo中也广泛的使用zookeeper管理一些配置来实现服务治理。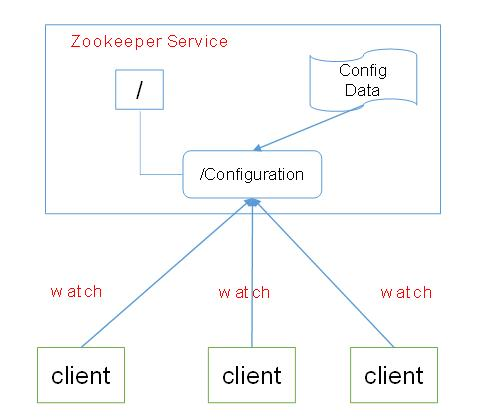
2、分布式锁服务
一个集群是一个分布式系统,由多台服务器组成。为了提高并发度和可靠性, 多台服务器上运行着同一种服务。当多个服务在运行时就需要协调各服务的进度,有时 候需要保证当某个服务在进行某个操作时,其他的服务都不能进行该操作,即对该操作 进行加锁,如果当前机器挂掉后,释放锁并fail over 到其他的机器继续执行该服务。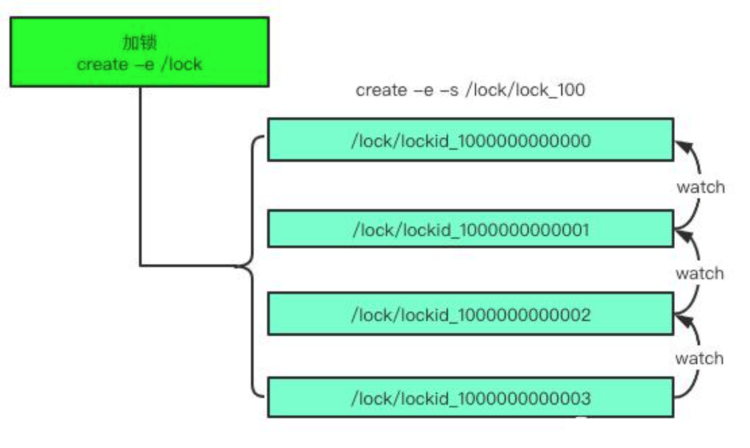
3、集群管理
一个集群有时会因为各种软硬件故障或者网络故障,出现某些服务器挂掉而被移除 集群,而某些服务器加入到集群中的情况,zookeeper会将这些服务器加入/移出的情况 通知给集群中的其他正常工作的服务器,以及时调整存储和计算等任务的分配和执行 等。此外zookeeper还会对故障的服务器做出诊断并尝试修复。
4、生成分布式唯一ID
在过去的单库单表型系统中,通常可以使用数据库字段自带的auto_increment 属性来自动为每条记录生成一个唯一的ID。但是分库分表后,就无法在依靠数据库的 auto_increment属性来唯一标识一条记录了。此时我们就可以用zookeeper在分布式环 境下生成全局唯一ID。做法如下:每次要生成一个新Id时,创建一个持久顺序节点,创建 操作返回的节点序号,即为新Id,然后把比自己节点小的删除即可
zookeeper的设计目标
zooKeeper致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访 问控制能力的分布式协调服务
- 高性能:zooKeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,尤其适用于以读为主的应用场景
- 高可用:zooKeeper一般以集群的方式对外提供服务,一般3 ~ 5台机器就可以组成一个可用 的Zookeeper集群了,每台机器都会在内存中维护当前的服务器状态,并且每台机器之间都相 互保持着通信。只要集群中超过一半的机器都能够正常工作,那么整个集群就能够正常对外服 务
- 严格顺序访问:对于来自客户端的每个更新请求,ZooKeeper都会分配一个全局唯一的递增编号, 这个编号反映了所有事务操作的先后顺序
zookeeper的数据模型
zookeeper的数据节点可以视为树状结构(或者目录),树中的各节点被称为 znode(即zookeeper node),一个znode可以有多个子节点。zookeeper节点在结构 上表现为树状;使用路径path来定位某个znode,比如/ns-1/taopanfeng/mysql/schema1/table1,此处ns-1、taopanfeng、mysql、schema1、table1分别是 根节点、2级节点、3级节点以及4级节点;其中ns-1是taopanfeng的父节点,taopanfeng是ns-1的子 节点,taopanfeng是mysql的父节点,mysql是taopanfeng的子节点,以此类推。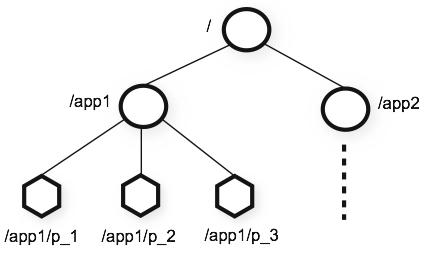
那么如何描述一个znode呢?一个znode大体上分为3各部分:
- 节点的数据:即znode data(节点path, 节点data)的关系就像是java map中(key, value)的关系
- 节点的子节点children
- 节点的状态stat:用来描述当前节点的创建、修改记录,包括cZxid、ctime等
节点状态stat的属性
在zookeeper shell中使用get命令查看指定路径节点的data、stat信息:
1 | [zk: localhost:2181(CONNECTED) 7] get /ns-1/tenant |
节点类型
zookeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即 被确定,并且不能改变。
- 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临 时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到 一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节 点不允许拥有子节点。
- 持久化节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作 的时候,他们才能被删除
zookeeper单机安装
当前测试系统环境centos7.3
jdk:jdk-8u131-linux-x64.tar.gz
zookeeper:zookeeper-3.4.10.tar.gz
1 | # 1. 在centos中使用root用户创建zookeeper用户,用户名:zookeeper 密 码:zookeeper |
zkClient 常用命令
新增节点
1 | # 语法 |
更新节点
1 | # 更新节点的命令是 set ,可以直接进行修改,如下: |
删除节点
1 | # 语法 |
查看节点
1 | # 语法 |
节点各个属性如下表。
其中一个重要的概念是 Zxid(ZooKeeper Transaction Id),ZooKeeper 节点的每一次更改都具有唯一的 Zxid。
如果 Zxid1 小于 Zxid2,则 Zxid1 的更改发生在 Zxid2 更改之前。
1 | 状态属性 说明 |
查看节点状态
1 | # 可以使用 stat 命令查看节点状态 |
查看节点列表
1 | # 查看节点列表有 ls path 和 ls2 path 两个命令 |
监听器get path [watch]
注意:watch 是一次性用品
1 | # 使用 get path [watch] 注册的监听器能够在节点内容发生改变的时候,向客 户端发出通知。 |
监听器stat path [watch]
1 | # 使用 stat path [watch] 注册的监听器能够在节点状态发生改变的时候,向客 户端发出通知 |
监听器ls\ls2 path [watch]
1 | # 使用 ls path [watch] |
ACL 权限控制
概述
ACL:全称 access control list 访问控制列表
zookeeper 类似文件系统,client 可以创建节点、更新节点、删除节点,那么如何做到节点的权限的控制呢?
zookeeper的access control list 访问控制列表可以做到 这一点。
acl 权限控制,使用scheme:id:permission 来标识,主要涵盖 3 个方面:
- 权限模式(scheme):授权的策略
- 授权对象(id):授权的对象
- 权限(permission):授予的权限
其特性如下:
- zooKeeper的权限控制是基于每个znode节点的,需要对每个节点设置权限
- 每个znode支持设置多种权限控制方案和多个权限
- 子节点不会继承父节点的权限,客户端无权访问某节点,但可能可以访问它的子节点
例如:
1 | # 将节点权限设置为Ip:192.168.60.130 的客户端可以对节点进行增、删、改、查、管理权限 |
权限模式
采用何种方式授权
1 | 方案 描述 |
授权的对象
给谁授予权限
授权对象ID是指,权限赋予的实体,例如:IP 地址或用户。
授予的权限
授予什么权限?
create、delete、read、writer、admin也就是 增、删、改、查、管理权限, 这5种权限简写为cdrwa。
注意:这5种权限中,delete是指对子节点的删除权限,其它4种 权限指对自身节点的操作权限
1 | 权限 ACL简写 描述 |
授权的相关命令
1 | 命令 使用方式 描述 |
案例
world授权模式
1 | # 命令 |
ip授权模式
1 | # 命令 |
auth授权模式
1 | # 命令 |
digest授权模式
1 | # 命令 |
多种模式授权
1 | # 同一个节点可以同时使用多种模式授权 |
ACL 超级管理员
zookeeper的权限管理模式有一种叫做super,该模式提供一个超管可以方便的访问 任何权限的节点
1 | # 假设这个超管是:super:admin,需要先为超管生成密码的密文 |
zookeeper java api
znode是zooKeeper集合的核心组件,zookeeper API提供了一小组方法使用 zookeeper集合来操纵znode的所有细节。
客户端应该遵循以步骤,与zookeeper服务器进行清晰和干净的交互。
- 连接到zookeeper服务器。zookeeper服务器为客户端分配会话ID。
- 定期向服务器发送心跳。否则,zookeeper服务器将过期会话ID,客户端需要重新连接。
- 只要会话ID处于活动状态,就可以获取/设置znode。
- 所有任务完成后,断开与zookeeper服务器的连接。如果客户端长时间不活动,则 zookeeper服务器将自动断开客户端。
连接到ZK
1 | ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher) |
新增节点
1 | // 同步方式 |
更新节点
1 | // 同步方式 |
删除节点
1 | // 同步方式 |
查看节点
1 | // 同步方式 |
查看子节点
1 | // 同步方式 |
检查节点是否存在
1 | // 同步方法 |
zookeeper 事件监听机制
2021-05-22 21:51:29
watcher概念
zookeeper提供了数据的发布/订阅功能,多个订阅者可同时监听某一特定主题对象,当该主题对象的自身状态发生变化时(例如节点内容改变、节点下的子节点列表改变等),会实时、主动通知所有订阅者
zookeeper采用了Watcher机制实现数据的发布/订阅功能。该机制在被订阅对 象发生变化时会异步通知客户端,因此客户端不必在Watcher注册后轮询阻塞,从而减轻 了客户端压力。
watcher机制实际上与观察者模式类似,也可看作是一种观察者模式在分布式场 景下的实现方式。
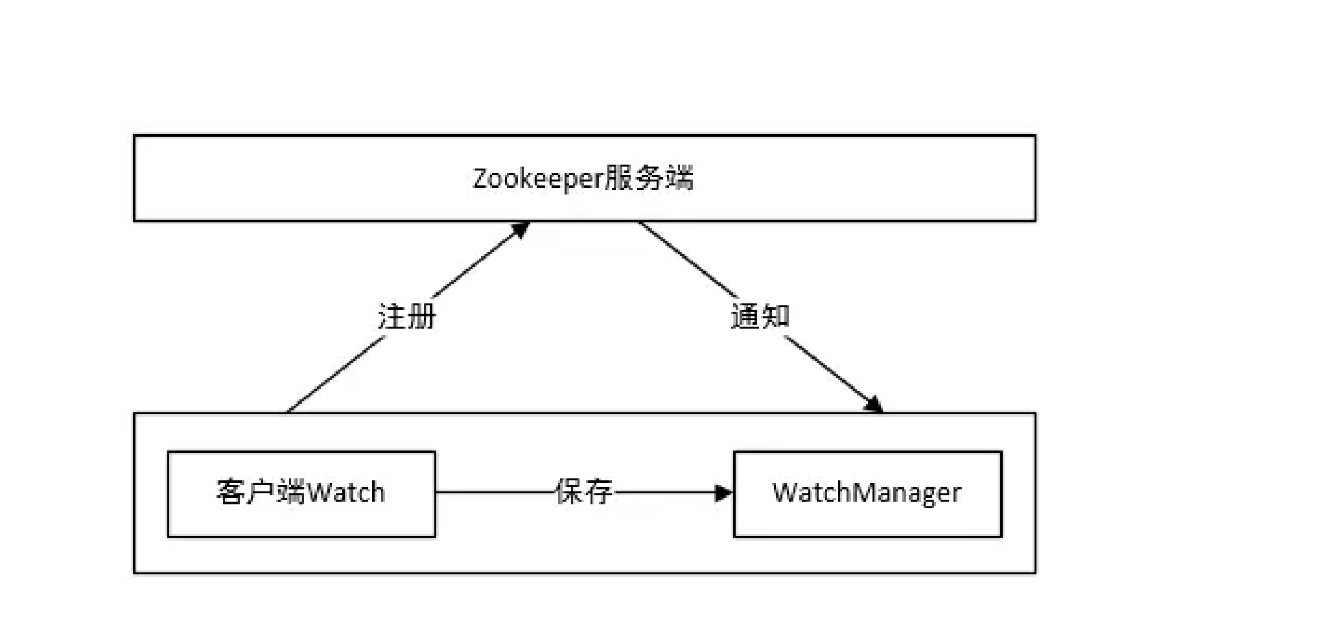
watcher架构
Watcher实现由三个部分组成:
- Zookeeper服务端
- Zookeeper客户端
- 客户端的ZKWatchManager对象
客户端首先将Watcher注册到服务端,同时将Watcher对象保存到客户端的Watch管 理器中。当ZooKeeper服务端监听的数据状态发生变化时,服务端会主动通知客户端, 接着客户端的Watch管理器会触发相关Watcher来回调相应处理逻辑,从而完成整体的数 据发布/订阅流程。
watcher特性
- 一次性:watcher是一次性的,一旦被触发就会移除,再次使用时需要重新注册
- 客户端顺序回调:watcher回调是顺序串行化执行的,只有回调后客户端才能看到最新的数据状态。一个watcher回调逻辑不应该太多,以免影响别的watcher执行
- 轻量级:WatchEvent是最小的通信单元,结构上只包含通知状态、事件类型和节点路径,并不会告诉数据节点变化前后的具体内容;
- 时效性:watcher只有在当前session彻底失效时才会无效,若在session有效期内 快速重连成功,则watcher依然存在,仍可接收到通知;
watcher接口设计
Watcher是一个接口,任何实现了Watcher接口的类就是一个新的Watcher。
Watcher内部包含了两个枚举类:KeeperState、EventType
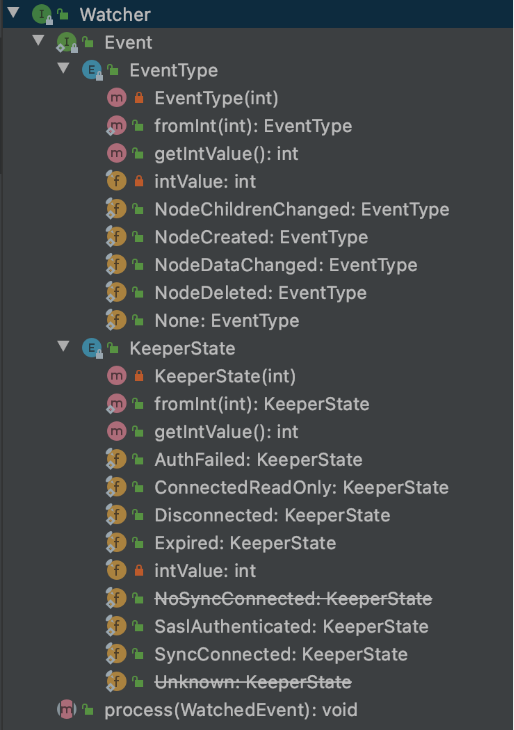
- Watcher通知状态(KeeperState)
KeeperState是客户端与服务端连接状态发生变化时对应的通知类型。
路径为 org.apache.zookeeper.Watcher.Event.KeeperState,是一个枚举类,其枚举属性 如下:1
2
3
4
5
6枚举属性 说明
---------------------------------------
SyncConnected 客户端与服务器正常连接时
Disconnected 客户端与服务器断开连接时
Expired 会话session失效时
AuthFailed 身份认证失败时 - Watcher事件类型(EventType)
EventType是数据节点(znode)发生变化时对应的通知类型。
EventType变化时 KeeperState永远处于SyncConnected通知状态下;
当KeeperState发生变化时, EventType永远为None。
其路径为org.apache.zookeeper.Watcher.Event.EventType, 是一个枚举类,枚举属性如下:注:客户端接收到的相关事件通知中只包含状态及类型等信息,不包括节点变化前后的具体内容,变化前的数据需业务自身存储,变化后的数据需调用get等方法重新获取;1
2
3
4
5
6
7枚举属性 说明
------------------------------------------------------
None 无
NodeCreated Watcher监听的数据节点被创建时
NodeDeleted Watcher监听的数据节点被删除时
NodeDataChanged Watcher监听的数据节点内容发生变更时(无论内容数据是否变化)
NodeChildrenChanged Watcher监听的数据节点的子节点列表发生变更时
捕获相应的事件
上面讲到zookeeper客户端连接的状态和zookeeper对znode节点监听的事件类 型,下面我们来讲解如何建立zookeeper的watcher监听。
在zookeeper中采用下面的方式为某个znode注册监听。
zk.getChildren(path, watch)zk.exists(path, watch)zk.getData(path, watcher, stat)
下表以node-x节点为例,说明调用的注册方法和可监听事件间的关系:
1 | 注册方式 Created ChildrenChanged Changed Deleted |
注册watcher的方法
连接状态
客服端与服务器的连接状态
1 | // KeeperState 通知状态 |
检查节点是否存在
1 | // 使用连接对象的监视器 |
查看节点
1 | // 使用连接对象的监视器 |
查看子节点
1 | // 使用连接对象的监视器 |
案例:配置中心
工作中有这样的一个场景: 数据库用户名和密码信息放在一个配置文件中,应用读取该配置文件,配置文件信息放入缓存。
若数据库的用户名和密码改变时候,还需要重新加载缓存,比较麻烦,通过 ZooKeeper可以轻松完成,当数据库发生变化时自动完成缓存同步。
1 | // 设计思路: |
案例:生成分布式唯一ID
在过去的单库单表型系统中,通常可以使用数据库字段自带的auto_increment 属性来自动为每条记录生成一个唯一的ID。
但是分库分表后,就无法在依靠数据库的 auto_increment属性来唯一标识一条记录了。
此时我们就可以用zookeeper在分布式环 境下生成全局唯一ID。
1 | // 设计思路: |
案例:分布式锁
分布式锁有多种实现方式,比如通过数据库、redis都可实现。作为分布式协同 工具ZooKeeper,当然也有着标准的实现方式。
下面介绍在zookeeper中如何实现排他锁。
1 | // 设计思路: |
zookeeper 集群搭建
单机环境下,jdk、zookeeper 安装完毕,基于一台虚拟机,进行zookeeper伪集群搭建,zookeeper集群中包含3个节点,节点对外提供服务端口号分别为2181、2182、2183
1 | # 1. 基于zookeeper-3.4.10复制三份zookeeper安装好的服务器文件, |
一致性协议:zab协议
zab协议 的全称是 Zookeeper Atomic Broadcast (zookeeper原子广播)。
zookeeper 是通过 zab协议来保证分布式事务的最终一致性
基于zab协议,zookeeper集群中的角色主要有以下三类,如下表所示:
zab广播模式工作原理,通过类似两阶段提交协议的方式解决数据一致性:
1 | 1. leader从客户端收到一个写请求 |
zookeeper的leader选举
服务器状态
- looking:寻找leader状态。当服务器处于该状态时,它会认为当前集群中没有 leader,因此需要进入leader选举状态。
- leading: 领导者状态。表明当前服务器角色是leader。
- following: 跟随者状态。表明当前服务器角色是follower。
- observing:观察者状态。表明当前服务器角色是observer。
启动时Leader选举
服务器启动时期的leader选举
在集群初始化阶段,当有一台服务器server1启动时,其单独无法进行和完成 leader选举,当第二台服务器server2启动时,此时两台机器可以相互通信,每台机器都 试图找到leader,于是进入leader选举过程。
选举过程如下:
- 每个server发出一个投票。由于是初始情况,server1和server2都会将自己作为 leader服务器来进行投票,每次投票会包含所推举的服务器的myid和zxid,使用 (myid, zxid)来表示,此时server1的投票为(1, 0),server2的投票为(2, 0),然后各自 将这个投票发给集群中其他机器。
- 集群中的每台服务器接收来自集群中各个服务器的投票。
- 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行pk,pk。规则如下:
、优先检查zxid。zxid比较大的服务器优先作为leader。
、如果zxid相同,那么就比较myid。myid较大的服务器作为leader服务器。 对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的zxid,均为0,再比较myid,此时server2的myid最大,于是更新自己的投票 为(2, 0),然后重新投票,对于server2而言,其无须更新自己的投票,只是再次向集 群中所有机器发出上一次投票信息即可。 - 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到 相同的投票信息,对于server1、server2而言,都统计出集群中已经有两台机器接受 了(2, 0)的投票信息,此时便认为已经选出了leader
- 改变服务器状态。一旦确定了leader,每个服务器就会更新自己的状态,如果是 follower,那么就变更为following,如果是leader,就变更为leading。
运行时Leader选举
服务器运行时期的Leader选举
在zookeeper运行期间,leader与非leader服务器各司其职,即便当有非leader 服务器宕机或新加入,此时也不会影响leader。
但是一旦leader服务器挂了,那么整个集群将暂停对外服务,进入新一轮leader选举,其过程和启动时期的Leader选举过程基本 一致。
假设正在运行的有server1、server2、server3三台服务器,当前leader是 server2,若某一时刻leader挂了,此时便开始Leader选举。
选举过程如下:
- 变更状态。leader挂后,余下的服务器都会将自己的服务器状态变更为looking,然后开始进入leader选举过程。
- 每个server会发出一个投票。在运行期间,每个服务器上的zxid可能不同,此时假定 server1的zxid为122,server3的zxid为122,在第一轮投票中,server1和server3 都会投自己,产生投票(1, 122),(3, 122),然后各自将投票发送给集群中所有机器。
- 接收来自各个服务器的投票。与启动时过程相同
- 处理投票。与启动时过程相同,此时,server3将会成为leader。
- 统计投票。与启动时过程相同。
- 改变服务器的状态。与启动时过程相同。
observer角色及其配置
observer角色特点:
- 不参与集群的leader选举
- 不参与集群中写数据时的ack反馈
1 | # 为了使用observer角色,在任何想变成observer角色的配置文件中加入如下配 置: |
zookeeperAPI连接集群
1 | ZooKeeper(String connectionString, int sessionTimeout, Watcher watcher) |
curator java api
2021-05-22 22:46:36
zookeeper 开源客户端curator介绍
curator简介
curator是Netflix公司开源的一个zookeeper客户端,后捐献给apache, curator框架在zookeeper原生API接口上进行了包装,解决了很多zooKeeper客户端非常底层的细节开发。
提供zooKeeper各种应用场景(比如:分布式锁服务、集群领导选举、 共享计数器、缓存机制、分布式队列等)的抽象封装,实现了Fluent风格的API接口,是最 好用,最流行的zookeeper的客户端。
1 | # 原生zookeeperAPI的不足: |
maven依赖:
1 | <dependency> |
连接到ZK
1 | package com.taopanfeng.curator; |
新增节点
1 | package com.taopanfeng.curator; |
更新节点
1 | package com.taopanfeng.curator; |
删除节点
1 | package com.taopanfeng.curator; |
查看节点
1 | package com.taopanfeng.curator; |
查看子节点
1 | package com.taopanfeng.curator; |
检查节点是否存在
1 | package com.taopanfeng.curator; |
watcherAPI
curator提供了两种Watcher(Cache)来监听结点的变化
- Node Cache : 只是监听某一个特定的节点,监听节点的新增和修改
- PathChildren Cache : 监控一个ZNode的子节点。当一个子节点增加, 更新、删除时, Path Cache会改变它的状态, 会包含最新的子节点, 子节点的数据和状态
1 | package com.taopanfeng.curator; |
事务
1 | package com.taopanfeng.curator; |
分布式锁
- InterProcessMutex:分布式可重入排它锁
- InterProcessReadWriteLock:分布式读写锁
1 | package com.taopanfeng.curator; |
四字监控命令
zookeeper四字监控命令
zooKeeper支持某些特定的四字命令与其的交互。它们大多是查询命令,用来 获取 zooKeeper服务的当前状态及相关信息。
用户在客户端可以通过 telnet 或 nc 向 zooKeeper提交相应的命令。
zooKeeper常用四字命令见下表 所示:
- conf 输出相关服务配置的详细信息。比如端口、zk数据及日志配置路径、最大 连接数,session超时时间、serverId等
- cons 列出所有连接到这台服务器的客户端连接/会话的详细信息。包括“接受/发 送”的包数量、session id 、操作延迟、最后的操作执行等信息
- crst 重置当前这台服务器所有连接/会话的统计信息
- dump 列出未经处理的会话和临时节点
- envi 输出关于服务器的环境详细信息
- ruok 测试服务是否处于正确运行状态。如果正常返回”imok”,否则返回空
- stat 输出服务器的详细信息:接收/发送包数量、连接数、模式 (leader/follower)、节点总数、延迟。 所有客户端的列表
- srst 重置server状态
- wchs 列出服务器watches的简洁信息:连接总数、watching节点总数和 watches总数
- wchc 通过session分组,列出watch的所有节点,它的输出是一个与 watch 相关 的会话的节点列表
- mntr 列出集群的健康状态。包括“接受/发送”的包数量、操作延迟、当前服务模 式(leader/follower)、节点总数、watch总数、临时节点总数
1 | # nc命令工具安装 |
conf
conf:输出相关服务配置的详细信息
shell终端输入:echo conf | nc localhost 2181
属性 含义
- clientPort 客户端端口号
- dataDir 数据快照文件目录 默认情况下10W次事务操作生成一次 快照
- dataLogDir 事物日志文件目录,生产环境中放在独立的磁盘上
- tickTime 服务器之间或客户端与服务器之间维持心跳的时间间隔(以 毫秒为单位)
- maxClientCnxns 最大连接数
- minSessionTimeout 最小session超时
minSessionTimeout=tickTime*2 - maxSessionTimeout 最大session超时
maxSessionTimeout=tickTime*20 - serverId 服务器编号
- initLimit 集群中的follower服务器(F)与leader服务器(L)之间初始连接 时能容忍的最多心跳数
- syncLimit 集群中的follower服务器(F)与leader服务器(L)之间 请求和 应答之间能容忍的最多心跳数
- electionAlg
0:基于UDP的LeaderElection1:基于UDP的 FastLeaderElection2:基于UDP和认证的 FastLeaderElection3:基于TCP的FastLeaderElection 在 1. 3.4.10版本中,默认值为3另外三种算法已经被弃用,并且 有计划在之后的版本中将它们彻底删除而不再支持 - electionPort 选举端口
- quorumPort 数据通信端口
- peerType 是否为观察者 1为观察者
cons
cons:列出所有连接到这台服务器的客户端连接/会话的详细信息
shell终端输入:echo cons | nc localhost 2181
- ip ip地址
- port 端口号
- queued 等待被处理的请求数,请求缓存在队列中
- received 收到的包数
- sent 发送的包数
- sid 会话id
- lop 最后的操作 GETD-读取数据 DELE-删除数据 CREA-创建数据
- est 连接时间戳
- to 超时时间
- lcxid 当前会话的操作id
- lzxid 最大事务id
- lresp 最后响应时间戳
- llat 最后/最新 延时
- minlat 最小延时
- maxlat 最大延时
- avglat 平均延时
crst
crst:重置当前这台服务器所有连接/会话的统计信息
shell终端输入:echo crst| nc localhost 2181
dump
dump:列出未经处理的会话和临时节点
shell终端输入:echo dump| nc localhost 2181
session id:znode path(1对多 , 处于队列中排队的session和临时节点)
envi
envi:输出关于服务器的环境配置信息
shell终端输入:echo envi | nc localhost 2181
- zookeeper.version 版本
- host.name host信息
- java.version java版本
- java.vendor 供应商
- java.home 运行环境所在目录
- java.class.path classpath
- java.library.path 第三方库指定非java类包的位置(如:dll,so)
- java.io.tmpdir 默认的临时文件路径 java.compiler JIT 编译器的名称
- os.name Linux os.arch amd64
- os.version 3.10.0-514.el7.x86_64
- user.name zookeeper
- user.home /home/zookeeper
- user.dir /home/zookeeper/zookeeper2181/bin
ruok
ruok:测试服务是否处于正确运行状态
shell终端输入:echo ruok | nc localhost 2181
stat
stat:输出服务器的详细信息与srvr相似,但是多了每个连接的会话信息
shell终端输入:echo stat | nc localhost 2181
- Zookeeper version 版本
- Latency min/avg/max 延时
- Received 收包
- Sent 发包
- Connections 连接数
- Outstanding 堆积数
- Zxid 最大事物id
- Mode 服务器角色
- Node count 节点数
srst
srst:重置server状态
shell终端输入:echo srst | nc localhost 2181
wchs
wchs:列出服务器watches的简洁信息
shell终端输入:echo wchs | nc localhost 2181
- connectsions 连接数
- watch-paths watch节点数
- watchers watcher数量
wchc
wchc:通过session分组,列出watch的所有节点,它的输出的是一个与 watch 相关 的会话的节点列表
shell终端输入:echo wchc | nc localhost 2181
问题:
wchc is not executed because it is not in the whitelist.
没有执行WCHC,因为它不在白名单中。解决方法:
1
2
3
4
5
6
7
8
9
10
11# 修改启动指令 zkServer.sh
# 注意找到这个信息
else
echo "JMX disabled by user request" >&2
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
# 下面添加如下信息
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
wchp
wchp:通过路径分组,列出所有的 watch 的session id信息
shell终端输入:echo wchp | nc localhost 2181
问题:
wchp is not executed because it is not in the whitelist.
没有执行WCHP,因为它不在白名单中。解决方法:
1
2
3
4
5
6
7
8
9
10# 修改启动指令 zkServer.sh
# 注意找到这个信息
else
echo "JMX disabled by user request" >&2
ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
fi
# 下面添加如下信息
ZOOMAIN="-Dzookeeper.4lw.commands.whitelist=* ${ZOOMAIN}"
mntr
mntr:列出服务器的健康状态
shell终端输入:echo mntr | nc localhost 2181
- zk_version 版本
- zk_avg_latency 平均延时
- zk_max_latency 最大延时
- zk_min_latency 最小延时
- zk_packets_received 收包数
- zk_packets_sent 发包数
- zk_num_alive_connections 连接数
- zk_outstanding_requests 堆积请求数
- zk_server_state leader/follower 状态
- zk_znode_count znode数量
- zk_watch_count watch数量
- zk_ephemerals_count 临时节点(znode)
- zk_approximate_data_size 数据大小
- zk_open_file_descriptor_count 打开的文件描述符数量
- zk_max_file_descriptor_count 最大文件描述符数量
ZooInspector图形化客户端
ZooInspector下载地址:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
解压后进入目录 ZooInspector\build,运行:java -jar zookeeper-dev-ZooInspector.jar # 执行命令如下
点击左上角连接按钮,输入zk服务地址:ip或者主机名:2181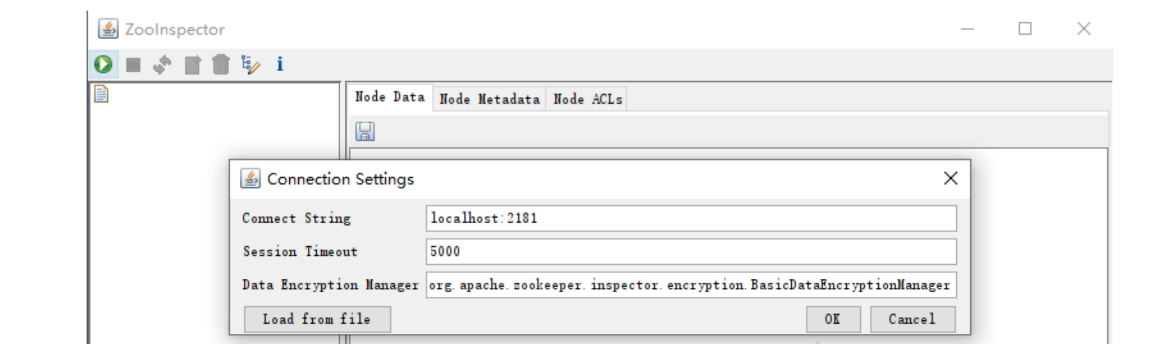
点击OK,即可查看ZK节点信息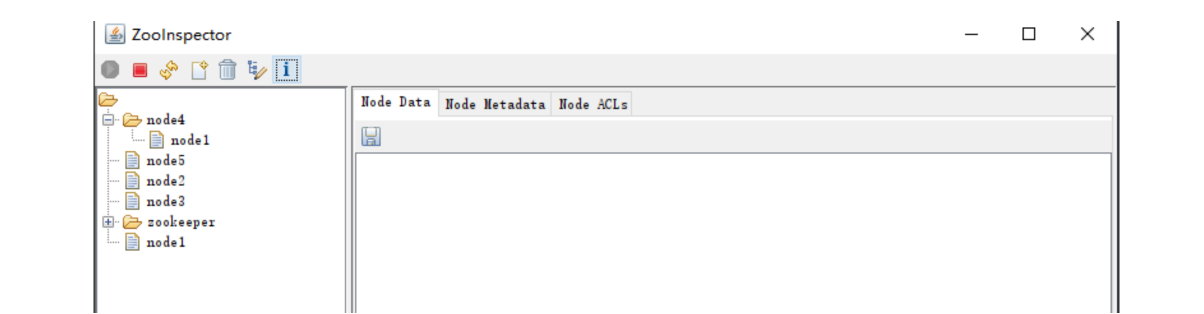
taokeeper监控工具
基于zookeeper的监控管理工具taokeeper,由淘宝团队开源的zk管理中间件, 安装前要求服务前先配置nc 和 sshd
1 | # 1.下载数据库脚本 |
