B+树的定义
在这之前,我知道B树和红黑树,但我一直搞不明白B+树是什么意思。即使别人给出了B+树的结构图,但也不能够理解。
MySQL官方对InnoDB的B+树的解释有这样的解释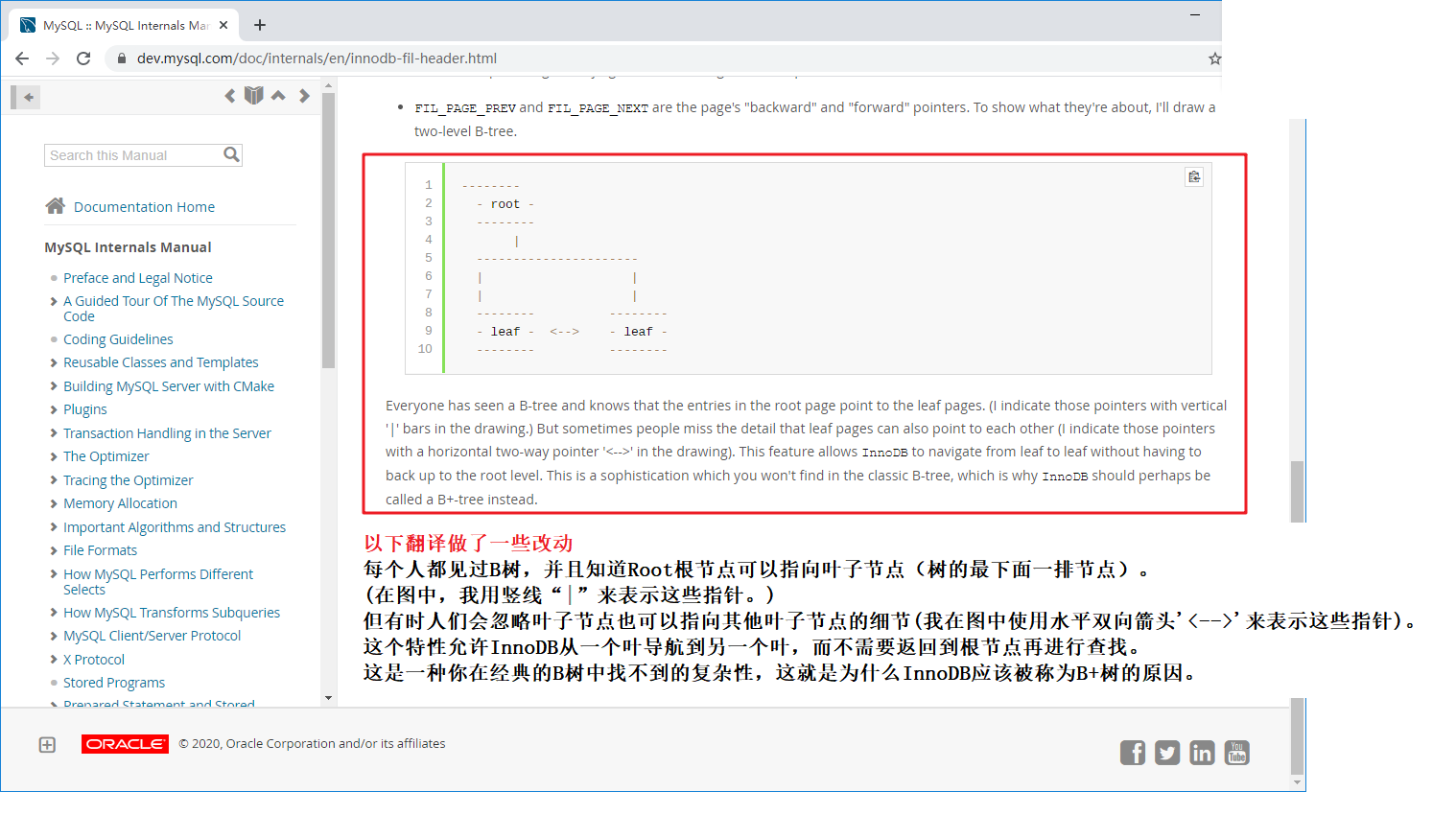
InnoDB中的“页”
操作系统有“页”,InnoDB也有“页”。
那么“页”是干什么的呢?
我们操作系统“页” 是一个逻辑单位,逻辑单位遵循是计算机著名的“局部性原理”,
操作系统认为,如果你要指向连续的指令,例如指令1:0x01,指令2:0x02,
指令1要从操作系统中取出1KB的数据,指令2也要从操作系统中取出1KB的数据,这里要进行两次操作系统的IO。
如果要有“页”的逻辑概念的话,就会一次性取一“页”的数据。操作系统的“页”的大小是:4KB
所以,执行指令1的时候,就会取出一页的数据都取出来,要想执行两条指令,就只取一次IO。
在InnoDB里面,查询SELECT * FROM t1;就会从磁盘一条一条取,就会进行多次磁盘IO。这样效率就会很低。
但InnoDB里面要有“页”的概念的话,同理就会一次取出一“页”的数据,只进行一次磁盘IO,那么InnoDB的“页”的大小是:16KB
InnoDB中主键索引生产过程
1 | --查看版本号:8.0.20 |
插入排序
当我们插入第一条数据的时候INSERT INTO t1 VALUES(4,3,1,1,'d');,会直接插入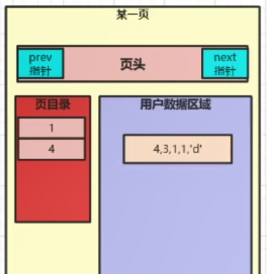
当我们插入第二条数据的时候INSERT INTO t1 VALUES(1,1,1,1,'a');,会根据主键索引进行asc排序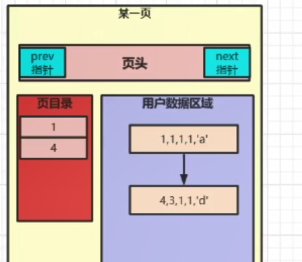
当我们插入第三条INSERT INTO t1 VALUES(8,8,8,8,'h');,同上,会根据主键索引进行asc排序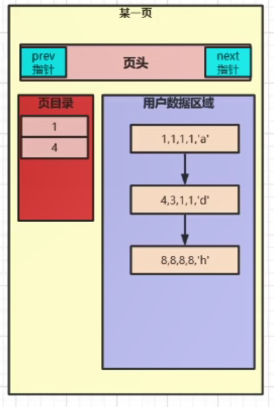
问:这样排序有什么好处呢?
答:当我们来查询的时候,例如:就拿上面插入三条记录来说,当我们查询SELECT * FROM t1 WHERE a=3;
就会拿3与主键索引a进行比较,先比较第一个1,3大于1,说明要找的数据还在后面,要继续往下比较查找,
比较第二个4,4 > 3也不符合,但此时4大于3,说明我们查找的数据不在后面。得到结果:没有我们要查询的数据。
试想:如果不就行排序,就会怎么样? 进行全量数据的比较,从而再得出结果。
页目录
首先要理解目录的概念
拿书本目录来举例:
| 第几章 | 第几页 |
|---|---|
| 第一章 | 1 |
| 第二章 | 10 |
| 第三章 | 20 |
从而可以知道,每一章都是对应着最小的页码。
我们InnoDB也是这样定义页目录的。
下面我们来对前四条数据进行分析
1 | INSERT INTO t1 VALUES(4,3,1,1,'d'); |
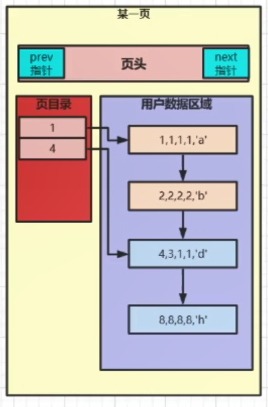
当我们插入第五条数据INSERT INTO t1 VALUES(5,2,3,5,'e');,
就会插入到拿主键索引a的值,也就是5与前面页目录的值进行比较,从而再进行数据的比较,插入到4和8之间。
多页
试想一下,我们的InnoDB的“页”是有大小限制的,我们来假设第一页,插入上面4条数据之后,已经快达到16KB了,
在进行第五条数据插入的时候,就会出现大于16KB的情况,这时候就会新增一“页”(第二页)。
但这两个页是连续的,第一页的页头会有next指针指向下一页,也就是第二页。
当我们插入8条记录的之后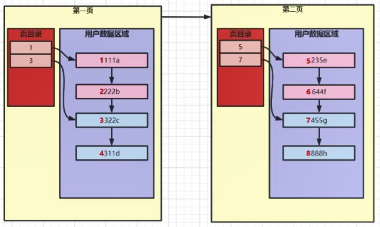
对于上述数据,我们查询SELECT * FROM t1 WHERE a=6;会发生什么呢?
1)、取出第一页的数据
2)、与第一页中的页目录进行比较,发现6是大于(1,3)的
3)、此时由第一页的next指针,取出第二页的数据
4)、与第二页的页目录进行比较,比较5,再比较7,说明6在页目录5中。
5)、在页目录5中进行查找,找到第一条a=5,不符合
6)、继续往下找,找到a=6符合,再往下找,a=7,不符合,结束查找,返回一条记录。
B+树
当我们查找a=6,还可以,可以很快的定位到页目录。
实现我们如果查找的是a=999999呢?(假设有很多页的数据的情况下)
1)、取出第一页的数据,拿999999与第一页的所有页目录进行比较,全部不符合
2)、用第一页的next指针,拿出第二页的数据,再取出第二页的所有页目录,再拿999999进行比较,全部不符合
3)、依次类推
我们可以想象出,这就是我们因为插入排序的长链表问题,我们用页目录进行解决。
所以,我们也可以使用页组的概念,来保存每一页中最小的页目录值,
这就是我们的B+树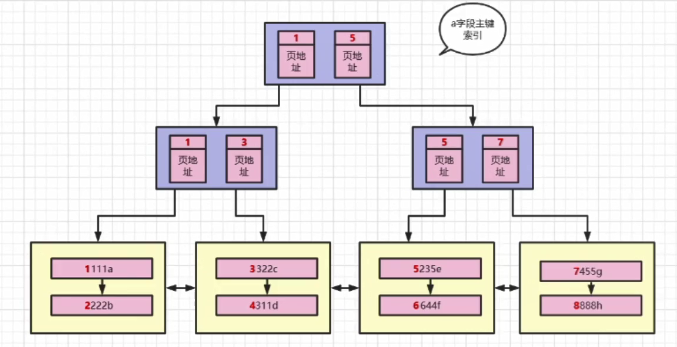
主键索引&唯一索引
我们上面讲的B+树案例,都是根据主键索引进行排序的。
那么索引是什么呢???可以理解是方便查找数据的数据结构,也可以理解为Java数组的下标。
数据结构是什么呢???组织数据的一种方式。
如果没有主键索引怎么办呢?
对于InnoDB来说,没有主键索引,就看有没有唯一索引,
因为主键索引和唯一索引的本质是很像的,可以说:主键索引是特殊的唯一索引。
如果有唯一索引就拿唯一索引作为主键索引,如果没有唯一索引,InnoDB就会在每一行生成ROWNUM行号。
主键索引是干什么呢?
为了让插入的时候进行排序,从而慢慢生成B+树,方便我们去查询。
聚集索引&非聚集索引
主键索引还有另外一个说法叫聚集索引:
聚集索引(聚簇索引):索引顺序和数据物理行的顺序是一样的。
非聚集索引(一个表可以有多个):索引的逻辑顺序和磁盘上行的物理存储顺序的不同的。
举个字典的例子:
汉语字典
- ABCD 拼音查询:和字典中汉字的存储顺序是一致的。
- 亻氵犭 偏旁查询:和字典中汉字的存储顺序是不一致,两个偏旁查询的字可以相隔十万八千里。
双向指针
为什么有双向指针?
我们还拿上面的一张B+数的结构图来举例
next
我们查询SELECT * FROM t1 WHERE a>1;
就会由第一个叶子(1,2)的next指针找到叶子(3,4),依次类推往后找。
prev
我们查询SELECT * FROM t1 WHERE a<8;
就会由最后一个叶子(7,8)的prev指针找到叶子(5,6),依次类推往前找。
这样就避免了我们查找到叶子之后,还要从根部再进行定位查找
InnoDB中联合索引生成过程
建立bcd索引之后的区别
1)、如果不建立bcd索引,我们查找SELECT * FROM t1 WHERE b=1 AND c=1 AND d=1;
1 | --1. 查看表 t1 中的所有索引 |
2)、建立bcd索引,我们再进行查找SELECT * FROM t1 WHERE b=1 AND c=1 AND d=1;
1 | --1. 创建联合索引 idx_t1_bcd |
联合索引的真实图例
我们创建一条联合索引CREATE INDEX idx_t1_bcd ON t1(b,c,d);
我们主键索引使用主键a来排序,我们bcd索引就使用字段bcd来排序。
默认升序,下面两者相等。
1 | CREATE INDEX idx_t1_bcd ON t1(b,c,d); |
1 | INSERT INTO t1 VALUES(4,3,1,1,'d'); |
按照插入,应该是这样的。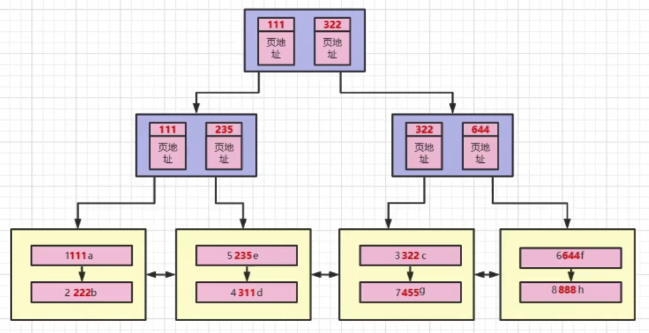
真正的联合索引是长这样的。
叶子节点存储的不是真正的数据,而是主键的值。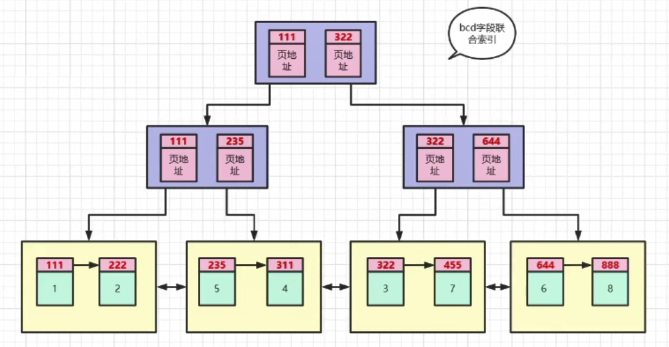
回表
我们执行SELECT * FROM t1 WHERE b=1 AND c=1 AND d=1;查找的是联合索引里面的数据。
而联合索引里面保存的是主键的值,再由主键的值,找到主键索引对应的数据。
主键索引叶子节点里面保存的是数据。
而联合索引叶子节点里面保存的是主键的值,找到主键的值之后,需要进行回表,由主键值找到对应数据。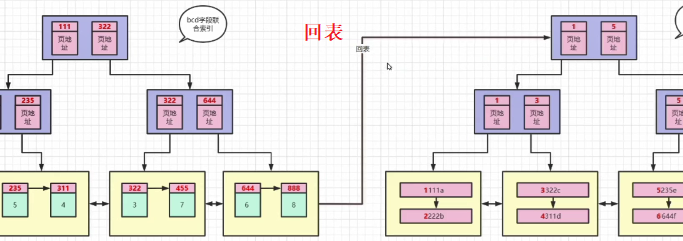
最左前缀原则
1)、示例1,不使用bcd索引
1 | EXPLAIN SELECT * FROM t1 WHERE c=1 AND d=1; |
只查找c和d,也就是找*11,没有告诉头节点,不知道走哪个。
需要提供最左边的字段,这就是我们常说的最左前缀原则
2)、示例2,使用bcd索引
1 | EXPLAIN SELECT * FROM t1 WHERE b=1; |
提供了1**,我们可以根据1来找到对应的叶子
3)、示例3,不使用bcd索引
1 | EXPLAIN SELECT * FROM t1 WHERE b like '%123'; |
4)、示例4,使用bcd索引
1 | EXPLAIN SELECT * FROM t1 WHERE b=1 AND d=1; |
注意这里的key_len:5,说明只使用了一个索引。
int默认4个字节,可以为null,所以+1 等于5
因为这里查找是1*1的情况,所以这里只使用了字段b
5)、示例5,使用bcd索引
注意下面两个的不同点。d也是属于bcd索引的,但e不属于。
WHERE b=1 AND d=1;:结果,Extra=Using index condition,表示在联合索引中查找b=1,再在联合索引中查找d=1,过滤的主键,根据主键回表的结果就是返回的内容
WHERE b=1 AND e=1;:结果,Extra=Using index condition,表示在联合索引中查找b=1,根据b=1找到主键,根据主键回表找到主键索引中的数据,根据主键索引中的数据进行where e=1过滤
WHERE b=1 AND d=1 AND e=1;结果,Extra=Using index condition; Using where,同上,在WHERE b=1 AND d=1的基础上,进行回表,再进行where e=1过滤
1 | EXPLAIN SELECT * FROM t1 WHERE b=1 AND d=1; |
整数&字符串索引
我们再把创表的SQL拿出来一下,方便下面对比查看。
1 | --创建 t1 表结构 |
1)、整数型索引
1 | --使用索引 |
2)、字符串型索引
此时我们再创建一个索引CREATE INDEX idx_t1_e ON t1(e);
1 | --使用索引 |
3)、总结:
整数型索引:查找a=1 或 a=’1’ 都会使用索引
字符串型索引:查找e=1 不会使用索引,e=’1’会使用索引
4)、为什么整数型转字符串型可以,字符串型转整数型不可以???
整数型转字符串简单,相当于直接在数字左右两边加了引号
但字符串转整数型,会排除字符串,只看字符串中是数字。
1 | 字符串 整数 |
5)、每种字符串对应不同的排序规则。
现在我们可以指定,这个排序规则,就是为了生成索引B+树,而方便我们查询数据的。