所用到的项目,请参考这里
Config
spring-cloud-config分布式配置中心
2020-05-22 09:59:28
简介
1)、分布式系统面临的—配置问题
微服务意味着要将单体应用中的业务拆分成一个个子服务, 每个服务的粒度相对较小,因此系统中会出现大量的服务。
由于每个服务都需要必要的配置信息豺能运行,所以一集中式的、动态的配置管理设施是必不可少的。
SpringCloud提供了ConfigServer来解决这个问题,我们每一个微服务自 己带着一个application.yml,. 上百个配置文件的管理…..o(╥﹏╥)o
2)、是什么?
SpringCloud Config为微服务架构中的微服务提供集中化的外部配置支持,配置服务器为各个不同微服务应用的所有环境提供了一个中心化的外部配置。
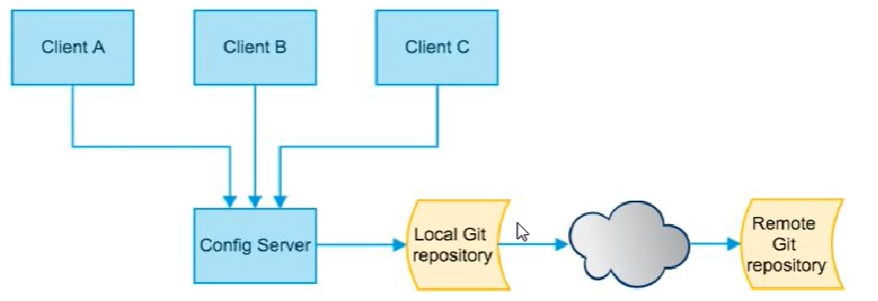
SpringCloud Config分为服务端和客户端两部分。服务端也称为分布式配置中心,它是一个独立的微服务应用,睐连接配置服务器并为客户端提供获取配置信息,加密/解密信息等访问接口客户端则是通过指定的配置中心来管理应用资源,以吸与业务相关的配置内容,并在启动的时候从配置中心获取和加载配置信息配置服务器默认采用git来存储配置信息,这样就有助于对环境配置进行版本管理,并且可以通过git客户端工具方便的管理和访问配置内容
3)、能干嘛?
- 集中管理配置文件
- 不同环境不同配置,动态化的配置更新,分环境比如dev/test/prod/beta/release
- 运行期间动态调整配置,不再需要在每个服务部署的机器上编写配置文件,服务会向配置中心同意拉去配置自己的信息
- 当配置发生改变时,服务不需要重启即可感知到配置的变化并应用新的配置
- 将配置信息以REST接口的形式暴露
4)、与GitHub整合配置
由于SpringCloud Config默认使用Git来存储配置文件(也有其他方式,比如支持SVN和本地文件),但最推荐还是Git,而且使用的是http/https访问的形式
Server端配置与测试
1)、创建好仓库
2)、初始化本地仓库
git init
git clone URL
git remote add taopanfeng URL
3)、创建好文件,再进行添加,提交,推送
git add .
git commit -m ‘.’
git push taopanfeng master
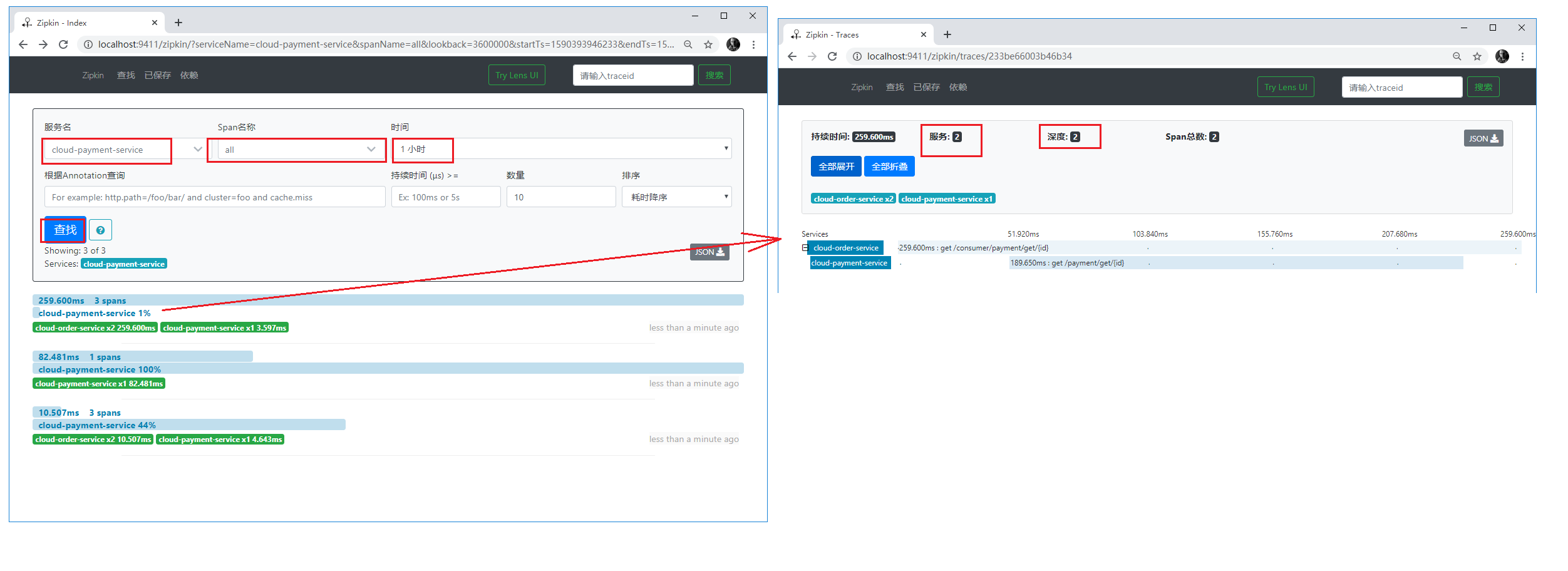
4)、搭建3344服务端,进行访问测试
注意依赖:服务端是config-server,客户端是config
5)、读取URL的规则
官网五种规则
1 | /{application}/{profile}[/{label}] |
label:分支(branch)【省略的话会去配置文件读取默认的】
application:服务名【自定义】
profile:环境(dev/test/prod)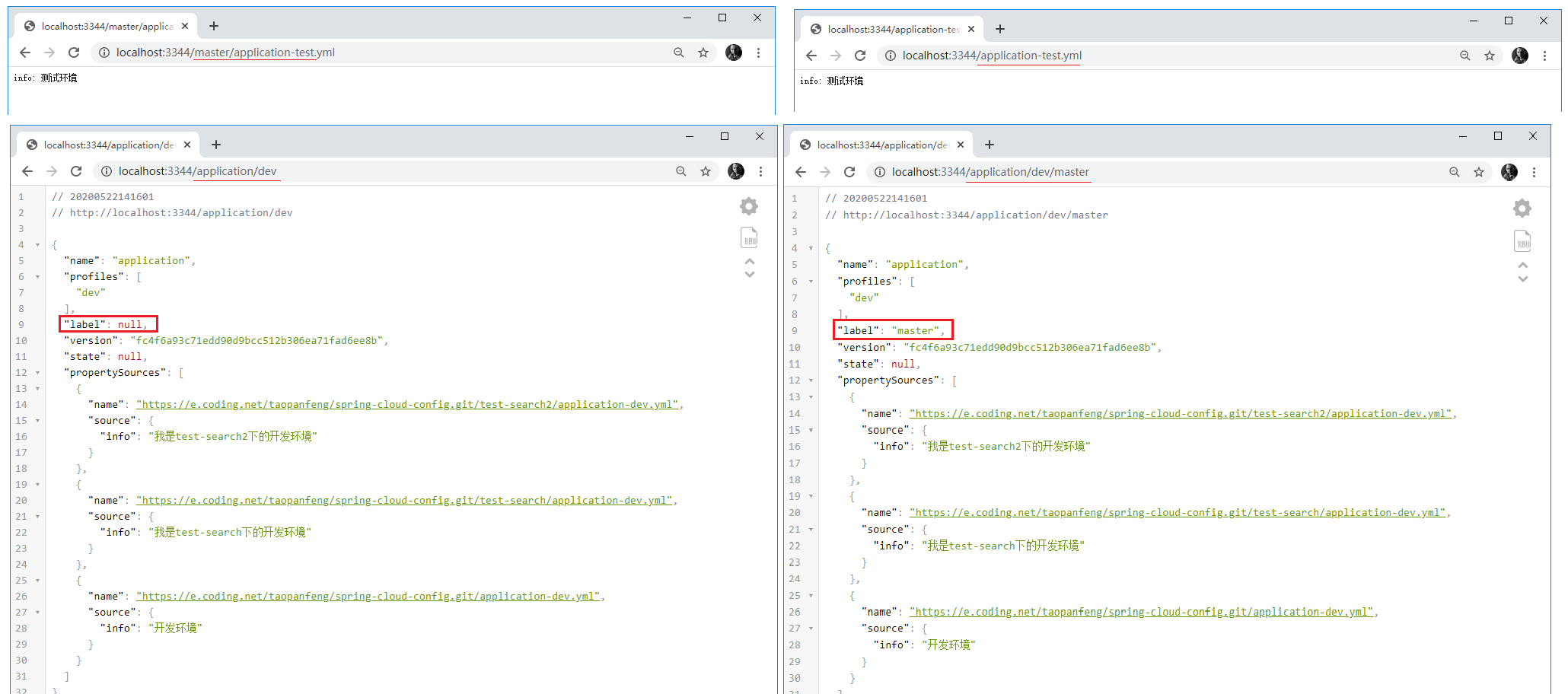
Client端配置与测试
1)、关于bootstrap.yml文件说明
2)、搭建3355客户端,依次启动7001,7002,3344,3355进行访问测试
注意依赖:服务端是config-server,客户端是config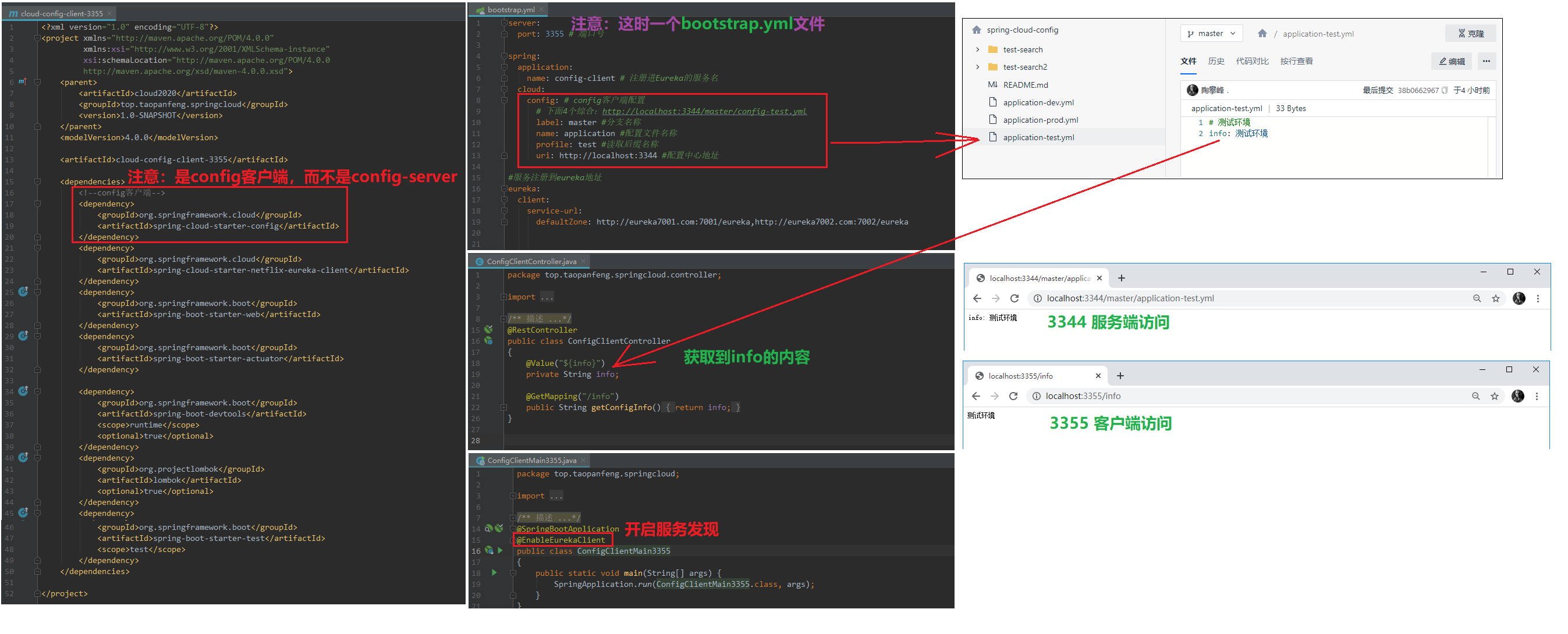
3)、出现问题
现在直接在浏览器上修改仓库中的配置文件。
服务端3344此时不重启服务就可以自动刷新读取的内容,但是3355还要重启服务才可以读取到修改的内容。
Client端之手动刷新单线
1)、解决客户端3355不刷新问题,配置actuator,手动刷新。
三步配置,
》引入actuator场景启动器
》配置actuator
》加入@RefreshScope注解
如果修改了配置文件后,想让客户端读取生效,需要发送一条POST请求http://localhost:3355/actuator/refresh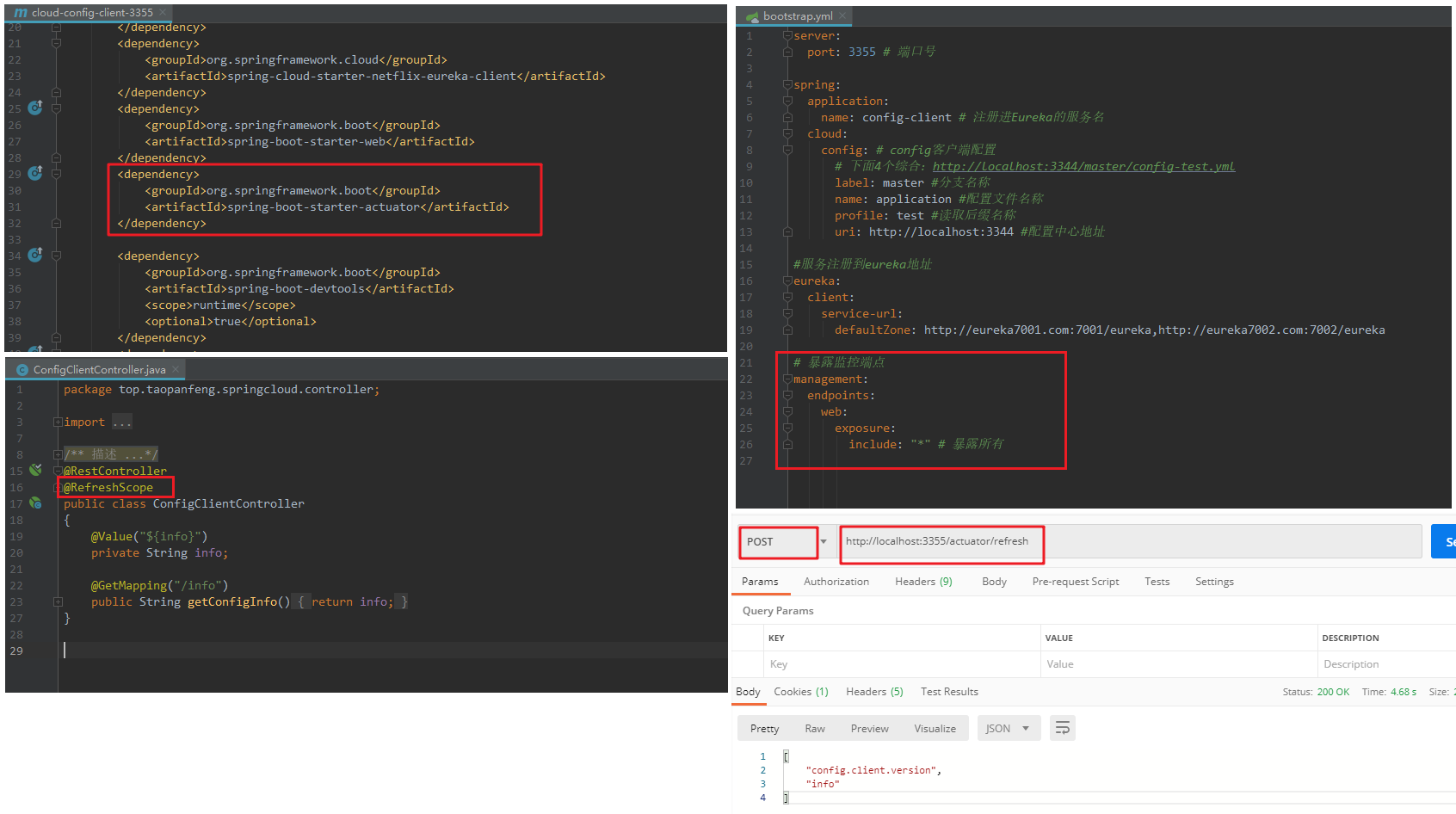
2)、只能手动版动态刷新,可以根据spring-cloud-bus进行广播自动刷新
Bus
spring-cloud-bus消息总线
2020-05-22 15:28:04
简介
1)、是什么?
一句话:配合spring-cloud-config进行配置文件的自动刷新,而非post手动刷新。只支持两种消息代理:RabbitMQ,Kafka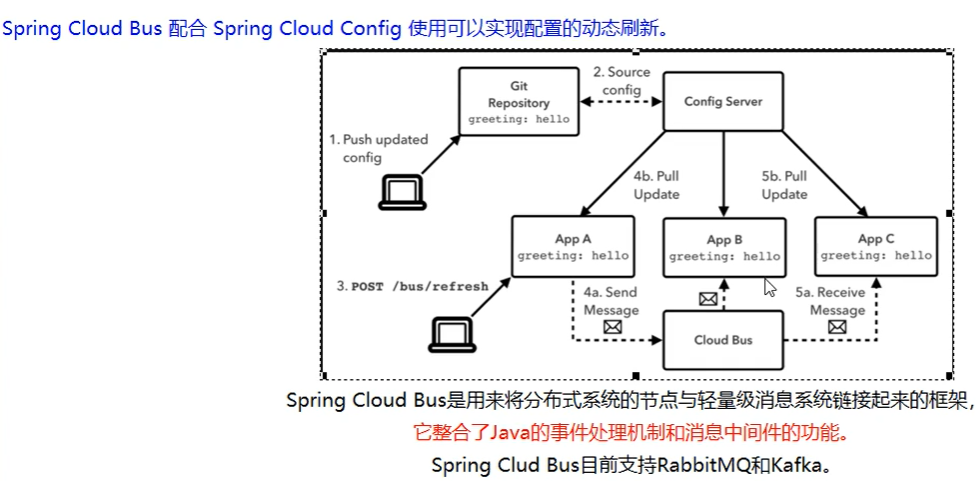
2)、能干嘛?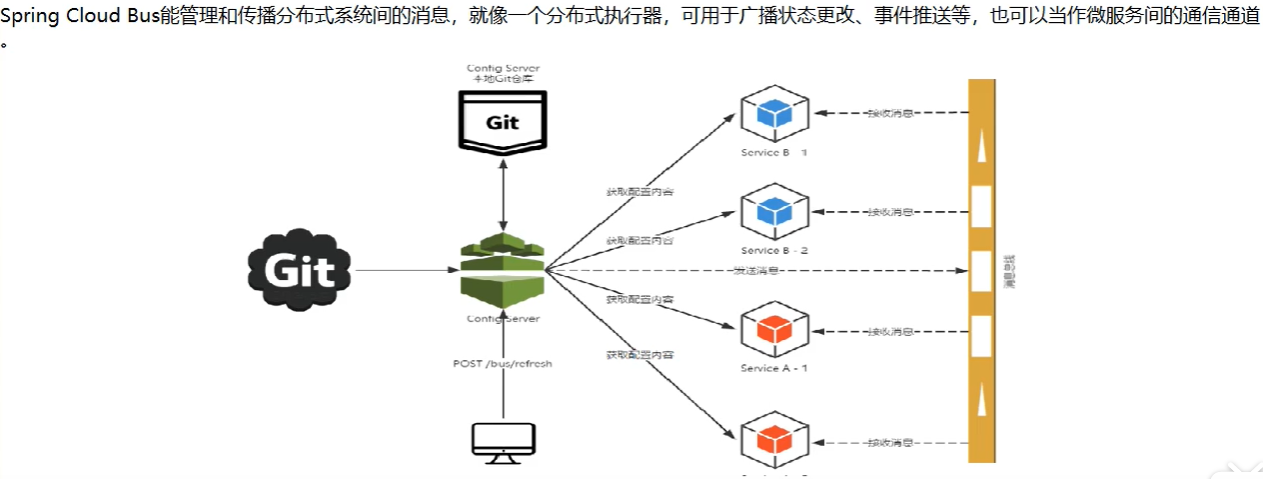
3)、为什么被称为总线?
手动刷新总线
1)、基于spring-cloud-config的3344,3355进行修改。另外新建一份3366,同3355配置,只改端口号。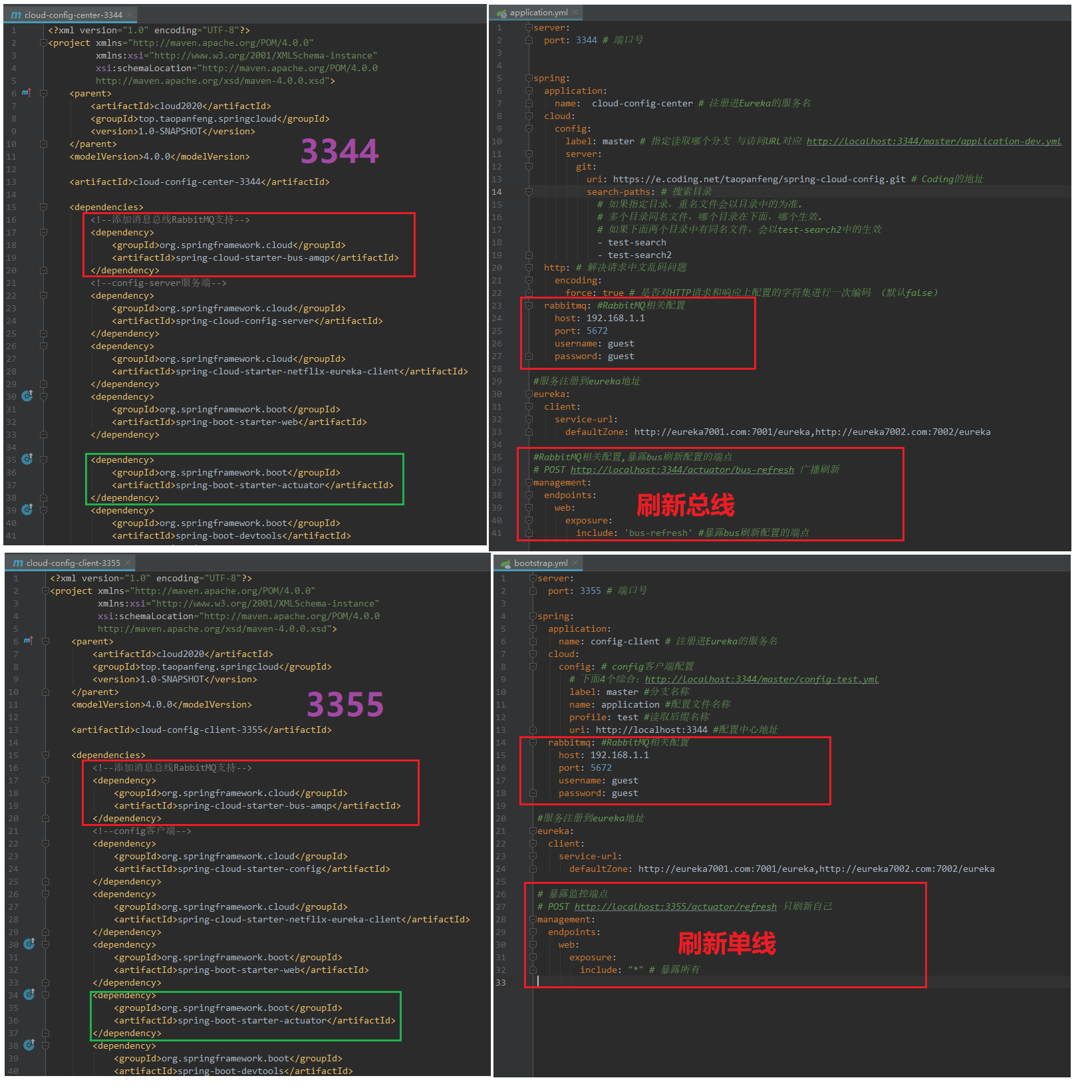
2)、启动测试。访问访问端会刷新总线,访问客户端会刷新单线。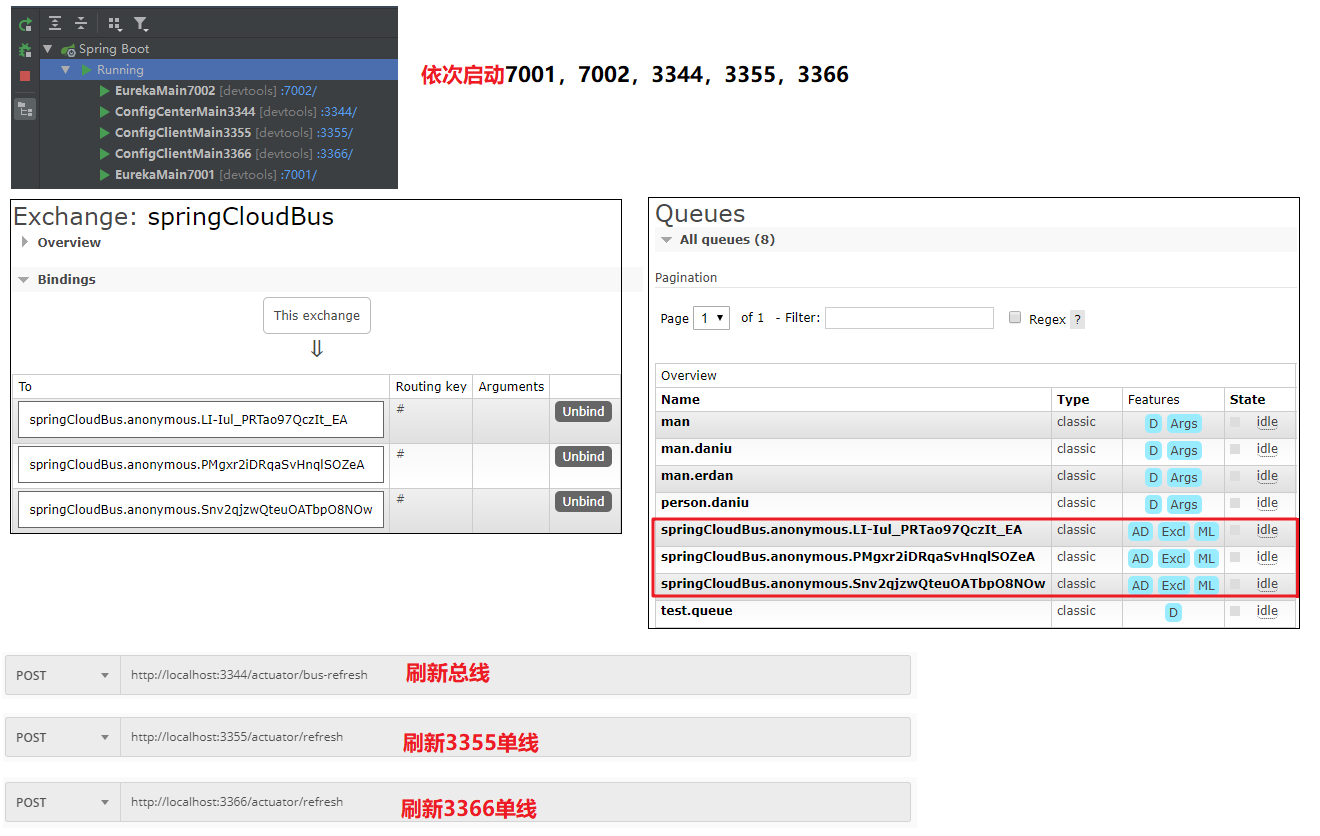
手动刷新单线
定点刷新
只刷新3355,而不刷新3366
发送POST请求http://localhost:3344/actuator/bus-refresh/config-client:3355
1 | config-client对应 -> spring.application.name=config-client |
上面的也可以使用下面来替换,只不过一个访问localhost:3344,一个是localhost:3355
发送POST请求http://localhost:3355/actuator/refresh
Stream
spring-cloud-stream消息驱动
参考文档:
Spring Cloud Stream 讲解 最全教程,包括配置文件描述
springCloud 之 spring-cloud-stream 自定义管道channel名称 集成消息中间件rabbitmq
概述
1)、是什么?
一句话:屏蔽底层消息中间件的差异,降低切换成本,统一消息的编程模型。(好比jdbc接口)
Spring Cloud Stream 官网
Spring Cloud Stream 中文指导手册
2)、设计思想
》》》标注MQ(Message Queue 消息队列)
- 生产者/消费者之间靠消息媒介传递信息内容:消息(Message)
- 消息必须走特定的通道:消息通道(MessageChannel)
- 消息通道里的消息如何被消费呢,谁负责收发处理:消息通道(MessageChannel)的子接口订阅通道(SubscribableChannel),由消息处理器(MessageHandler)消息处理器所订阅
》》》为什么使用Spring Cloud Stream?
只是举个栗子,应该不会有项目会使用两种消息中间件。
》》》stream凭什么可以统一底层差异
》》》Binder
、INPUT对应于消费者
、OUTPUT对应于生产者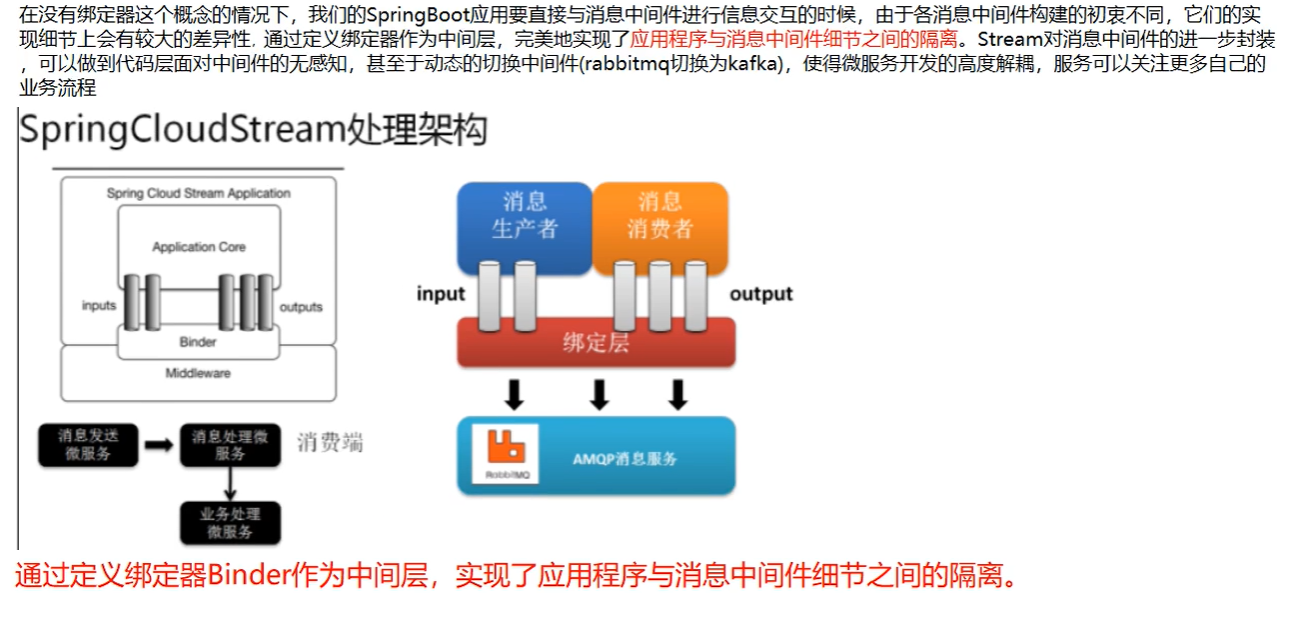
》》》Stream中的消息通信方式遵循了发布-订阅模式
Topic主题进行广播
、在RabbitMQ就是Exchange
、在Kafka中就是Topic
3)、Spring Cloud Stream标准流程套路
Binder很方便的连接中间件,屏蔽差异Channel通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel对队列进行配置Source和Sink简单的可以理解为参照对象是Spring Cloud Stream 自身,从Stream发布消息就是输出,接受消息就是输入
4)、编码API和常用注解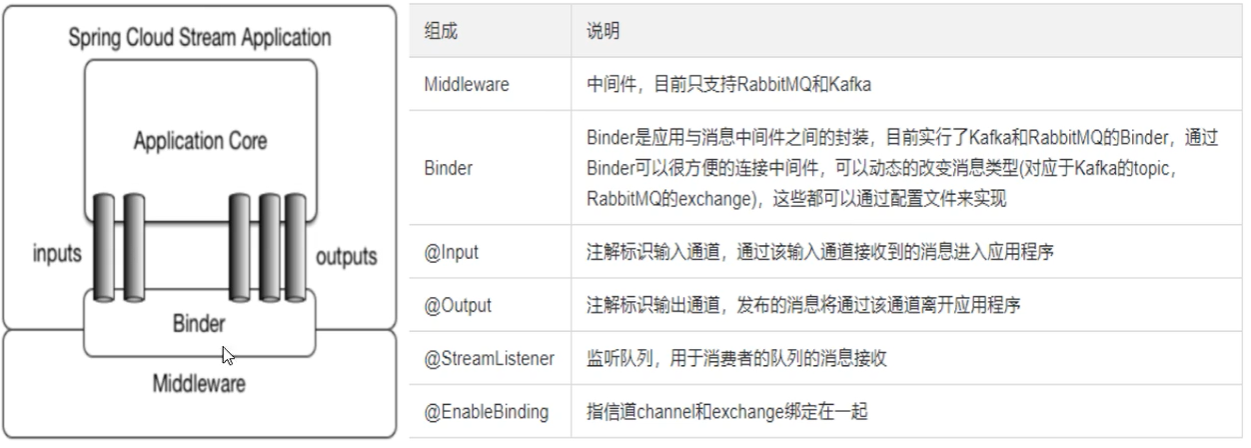
入门案例
1)、生产者8801
2)、消费者8802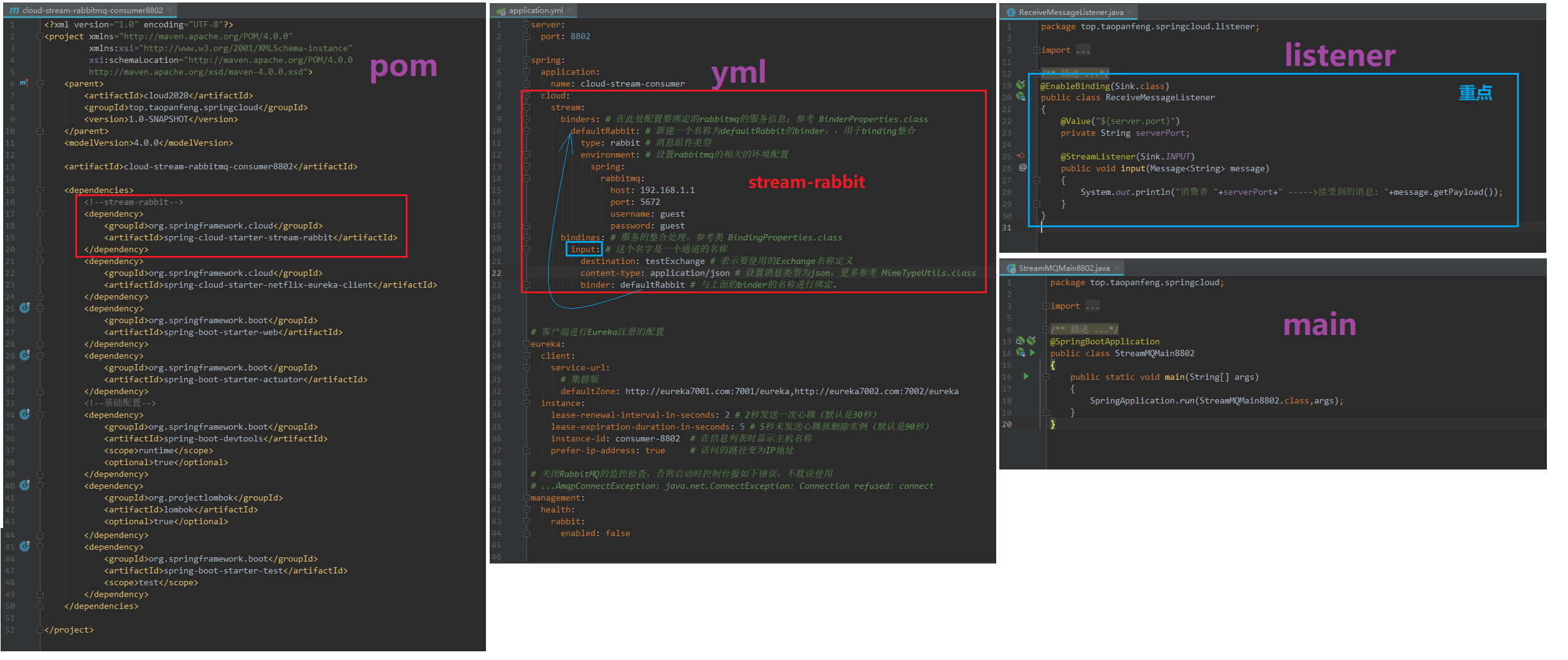
3)、消费者8803,与8802一致,只是端口不同。
4)、测试
依次启动7001,7002,8801,8802,8803
请求http://localhost:8801/sendMessage发送三条数据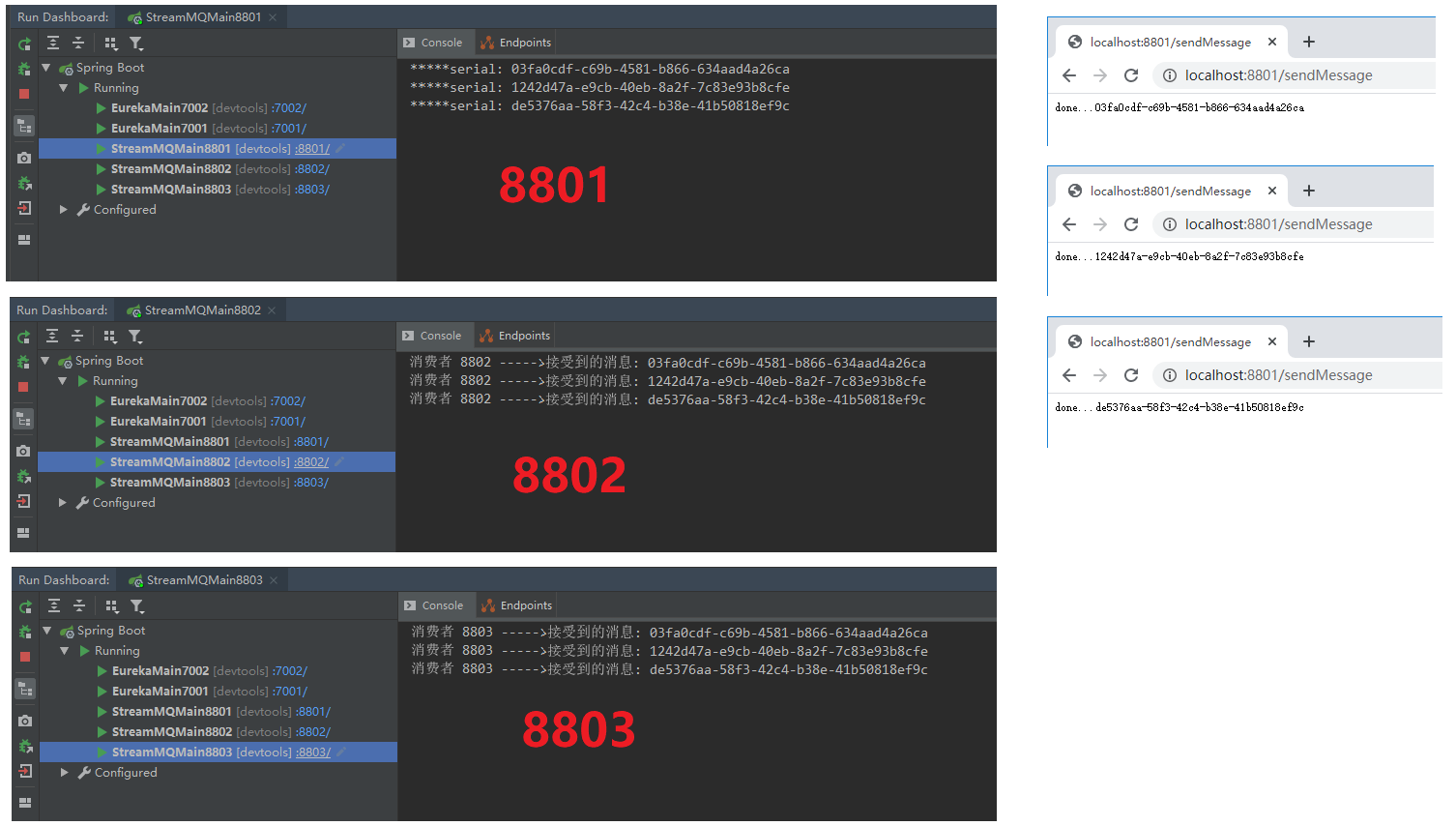
从图中可以看出,我们的8802,8803都消费了数据,存在重复消费的问题。如果不想重复消费怎么办呢?
可以使用分组的概念
分组
1)、概念
destination:testExchange # 对应这RabbitMQ的Exchange名称为testExchange,默认topic
group:B # 会创建一个持久化的队列testExchange.B ,如果不指定会生成一个临时的队列,项目关闭则队列消失。
队列存在,则Exchange会与队列绑定,队列消失,则会自动解绑。
group是进行分组,每个组可以有多个消费者,一个组只能有一个消费者进行消费。
也就是说如果把8802,8803分到一个组就可以解决重复消费的问题。
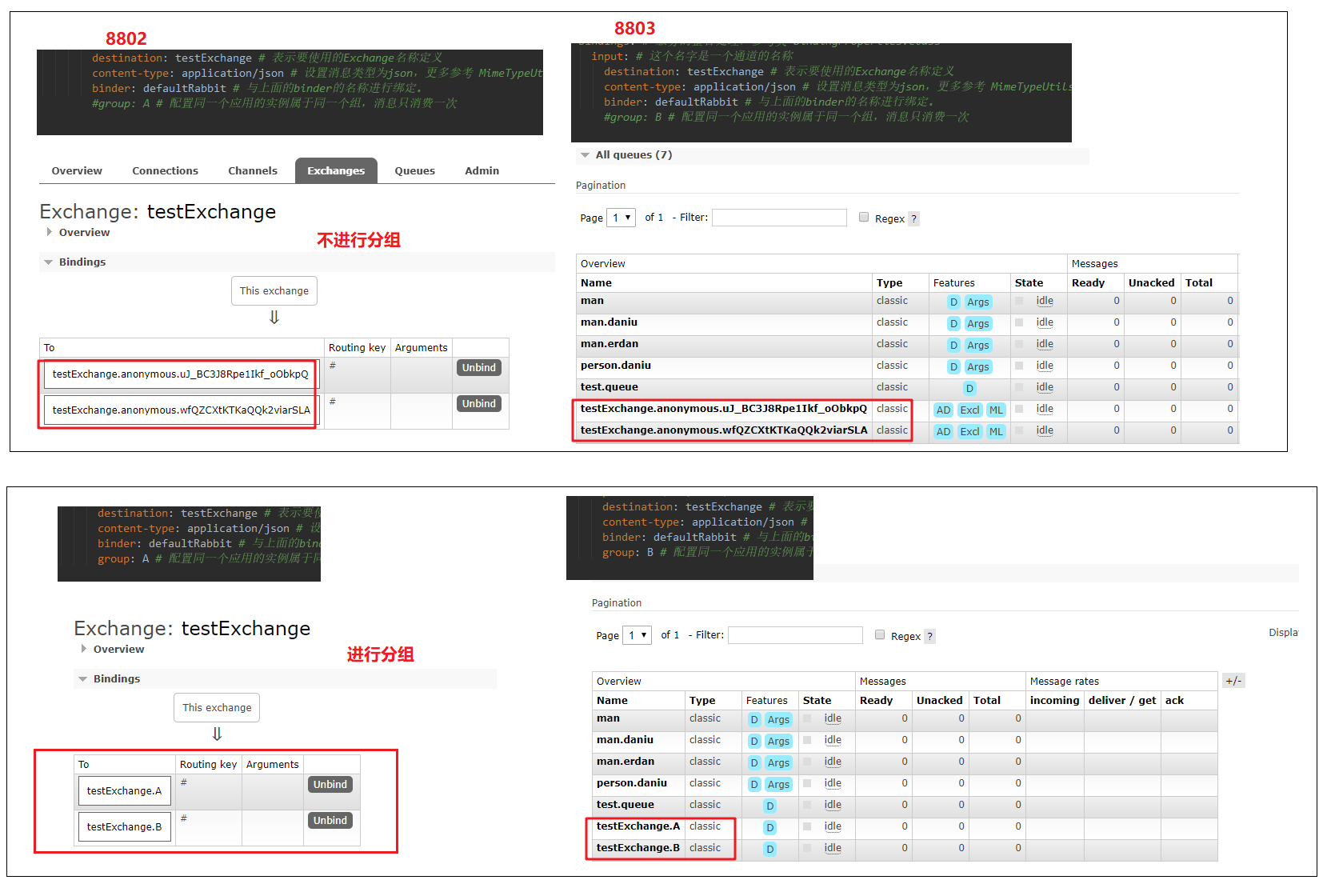
2)、测试
8002,8003分到同一个组。8001不变。不进行分组。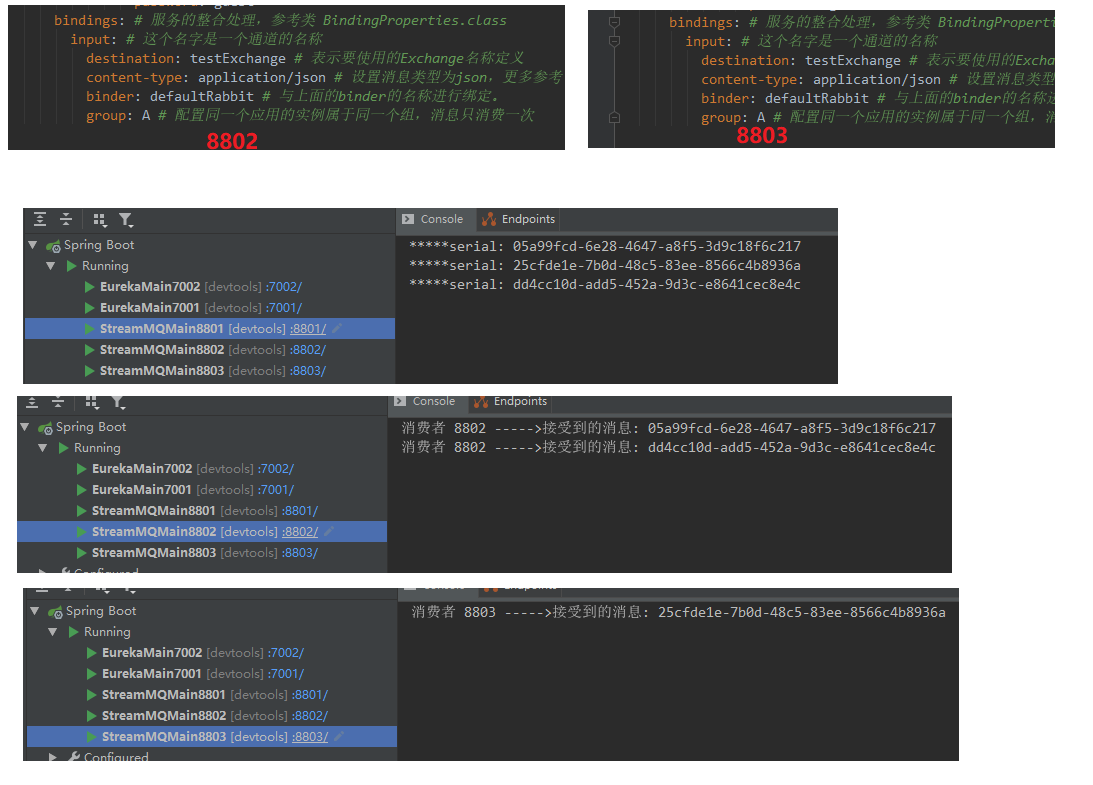
持久化
8001不进行分组,进行分发三条消息。
8002进行分组启动,8003不分组启动。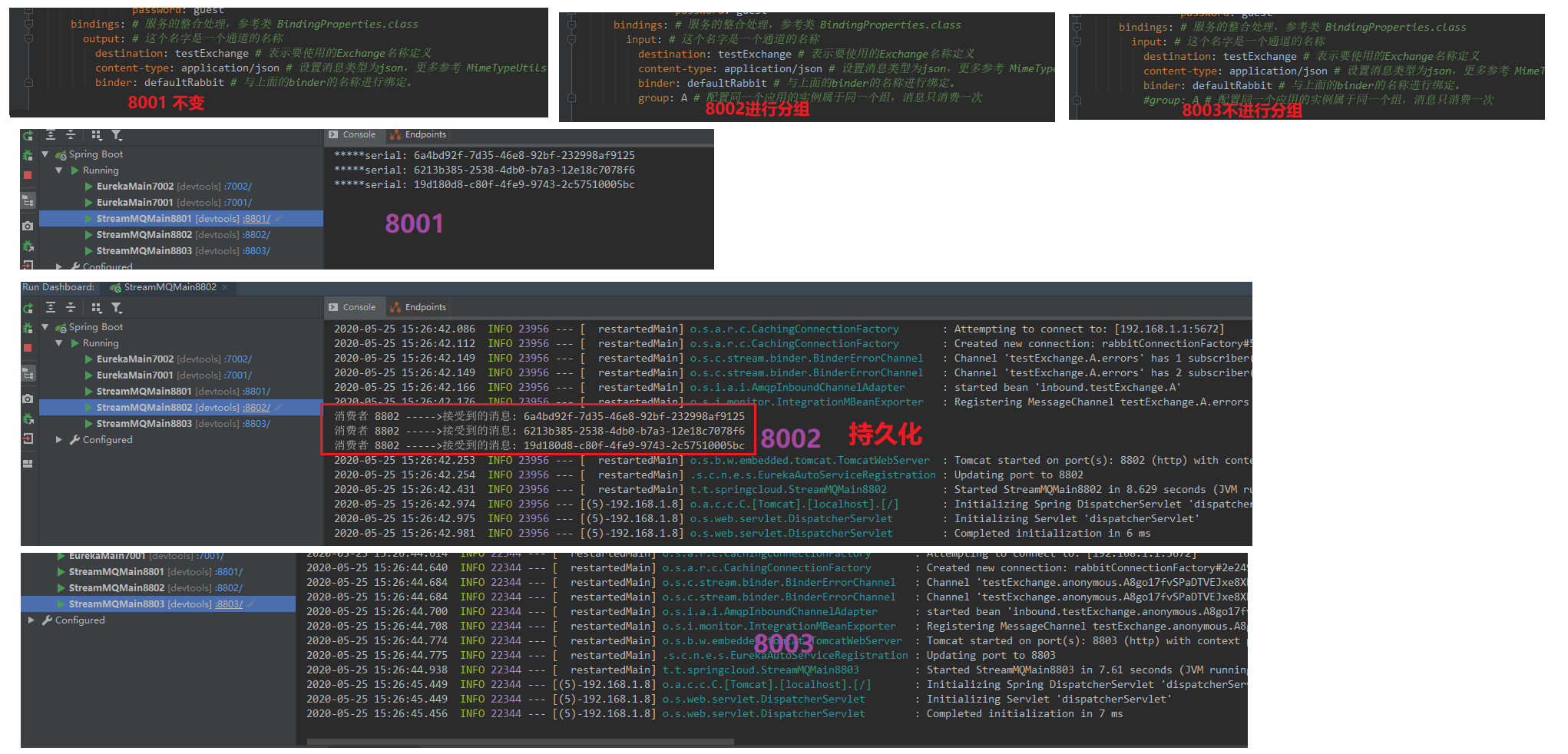
从上面的分组的概念,可以理解为:原存在队列testExchange.A队列,并与队列进行了绑定,路由键井号,表示任意。
因为停止了项目,并不会删除分组的队列,会删除临时的队列。所以,8801发送的时候,消息已经存在队列中的,只是没有进行消费。
这时候,启动8802,8803进行消费,8802的队列存在,则直接消费,8803是生产的临时的,所以消费不了。是刚创建的空队列。
关系图
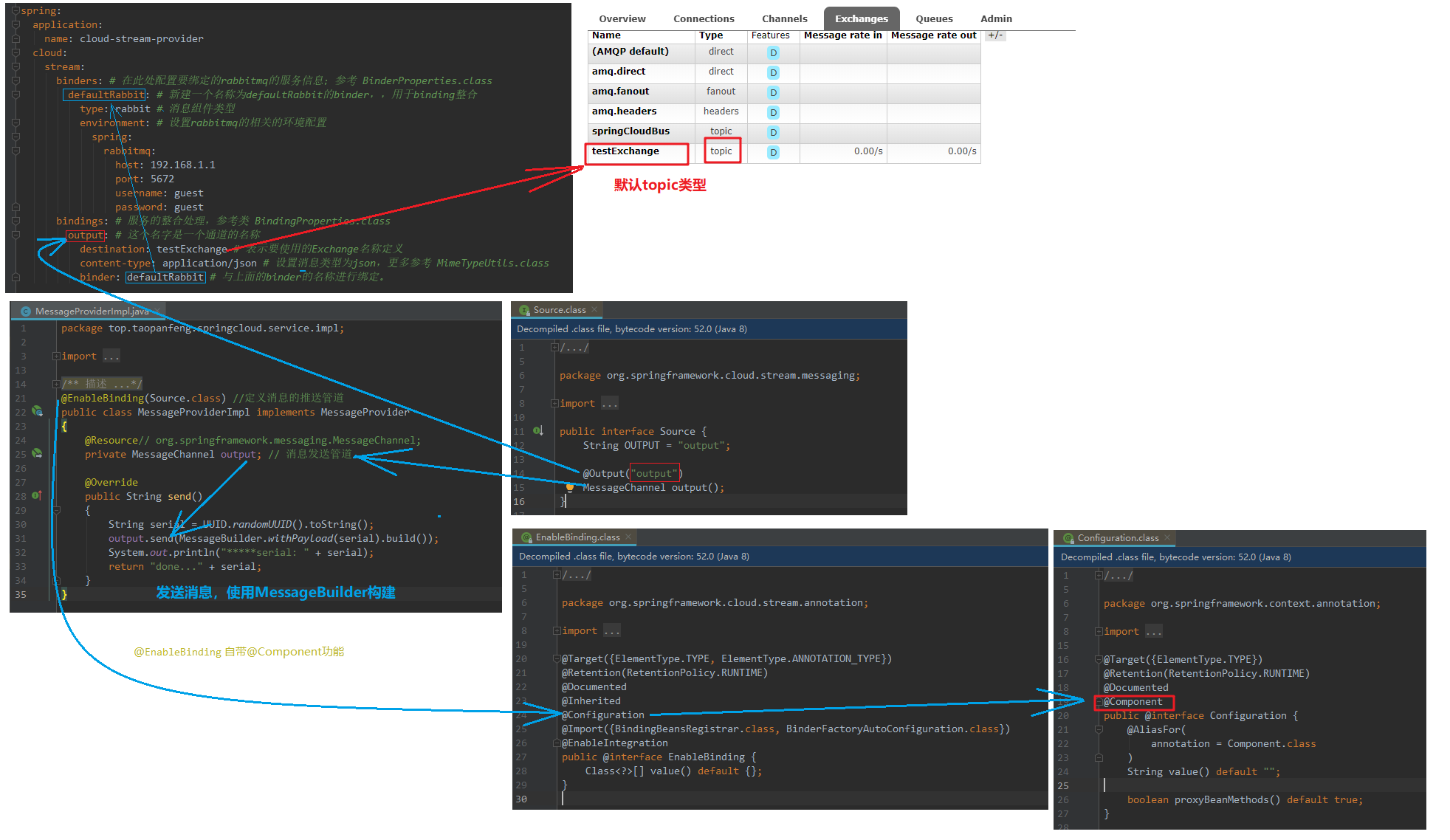
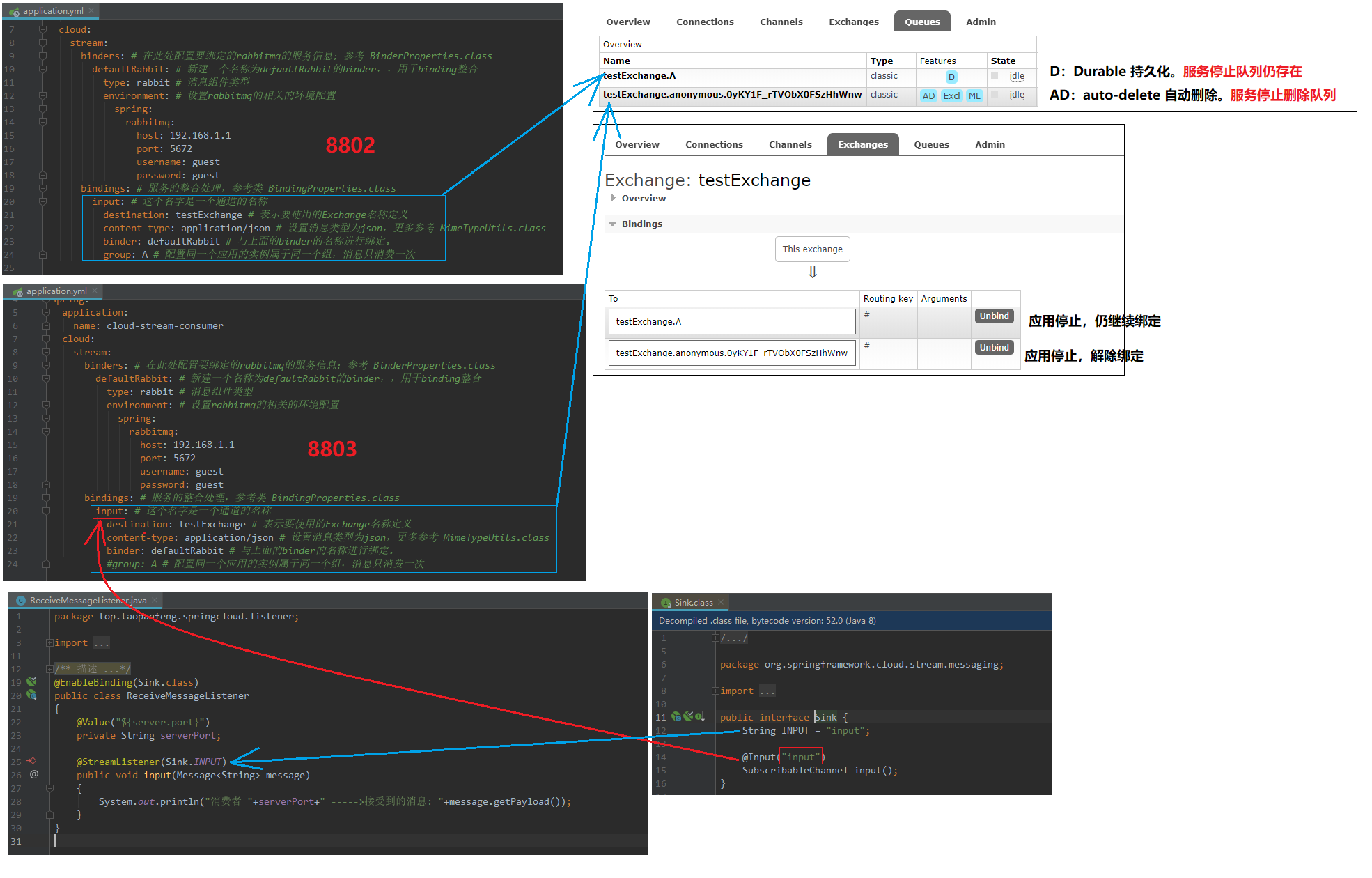
自定义input,output
只修改8801,8802作为演示。
1)、8801修改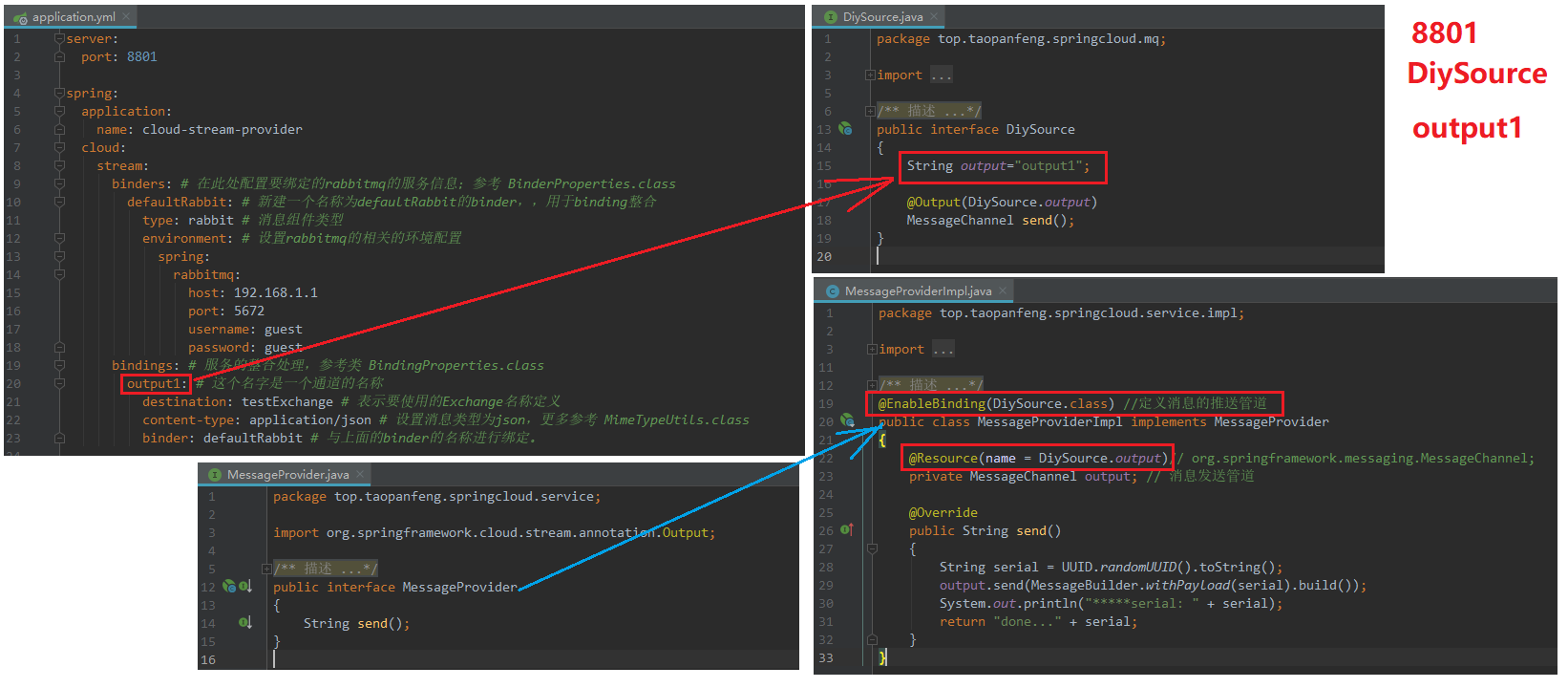
2)、8802修改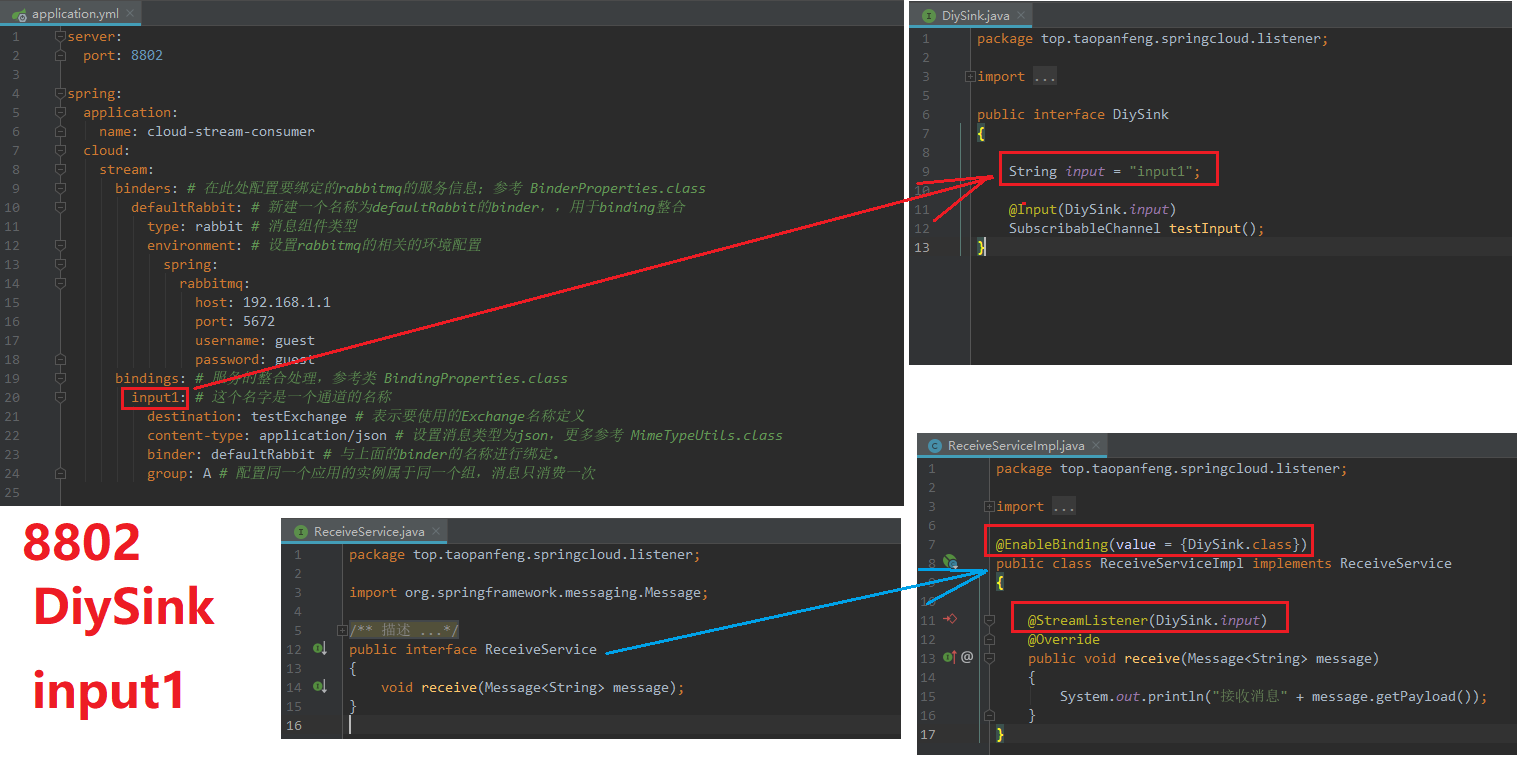
3)、测试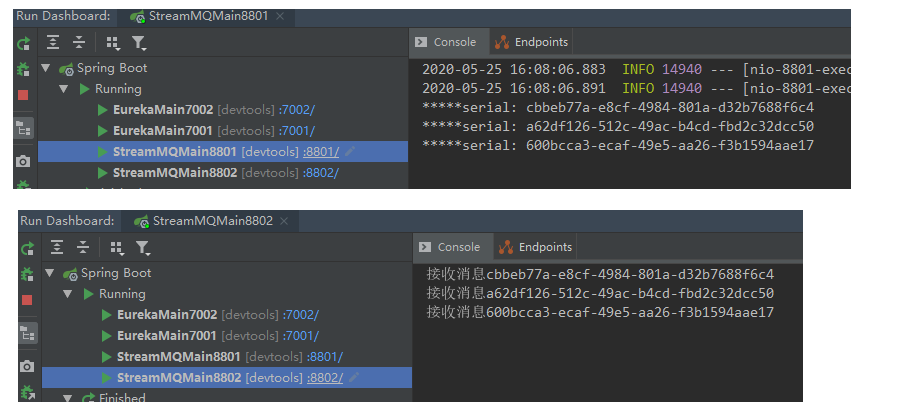
spring-cloud-sleuth
分布式链路追踪
2020-05-25 16:22:27
概述
1)、为什么会出现这个技术?需要解决哪些问题?
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,
每一个前段请求都会形成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。
2)、是什么?
官方文档
Spring Cloud Sleuth提供了一套完整的服务跟踪的解决方案,在分布式系统中提供追踪解决方案并且兼容支持了zipkin
3)、解决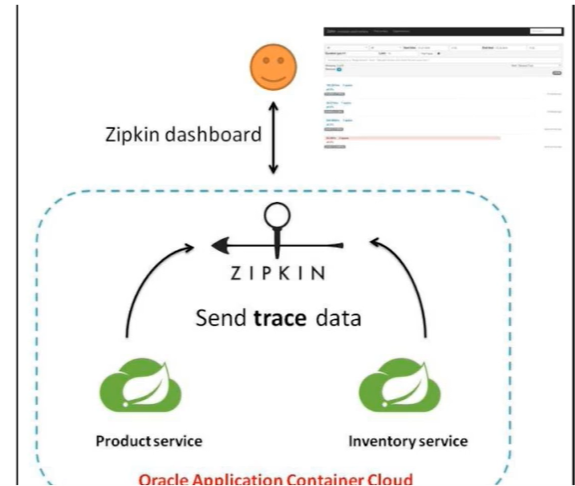
搭建步骤
1)、zipkin下载,启动
SpringCloud从F版已不需要自己构建Zipkin Server了,只需要调用jar包即可。
这里选择zipkin-server-2.12.9-exec.jar
zipkin 下载地址
运行jar:java -jar zipkin-server-2.12.9-exec.jar
运行控制台:http://localhost:9411/zipkin/
2)、更深入的理解
完整的调用链路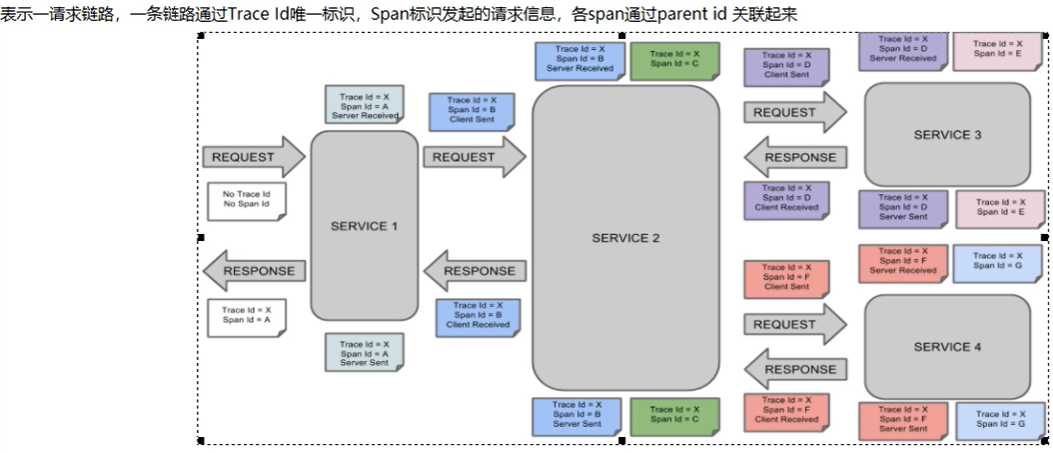
对于上图的解释
名词解释
、Trace:类似于树结构的Span结合,表示一条调用链路,存在唯一标识
、span:标识调用链路来源,通俗的理解span就是一次请求信息
3)、修改代码
》》》修改8001与80,都是同样加入红色部分。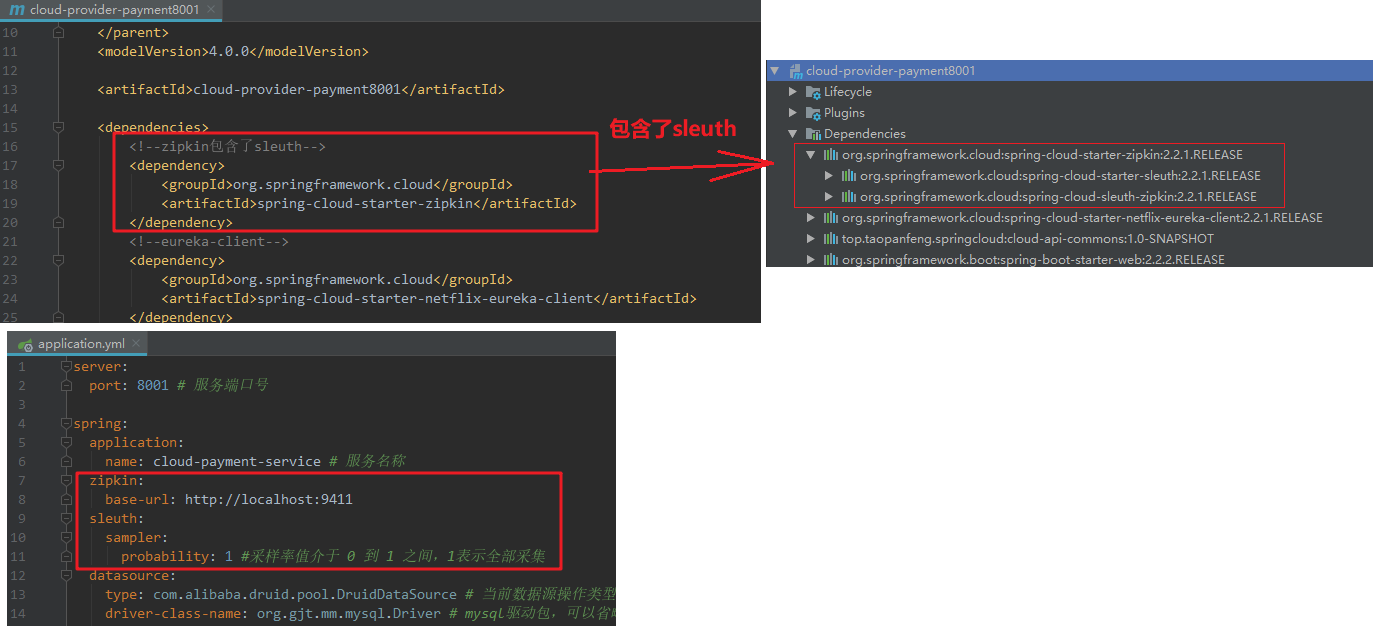
4)、测试
先启动ziplin的jar包,再依次启动7001,7002,8001,80
访问1次8001:http://localhost:8001/payment/get/1
访问2次80:http://localhost/consumer/payment/get/1