实际
2020-05-12 15:28:39
此篇文章使用版本:2.2.2.RELEASE
源码
Elasticsearch是Docker安装的7.4.0版本,并安装了ik分词器
关于Elasticsearch可以查看
1. Elasticsearch没看文档之前,整理的一些知识
2. Elasticsearch中文文档,内容不全
3. Elasticsearch 7.4.0官方文档操作
1 | # 查看所有节点(* 代表是主节点) |
1 | 2021-02-26 17:39:46 测试分词器 |
1)、SpringBoot2.2.2整合Elasticsearch7.4.0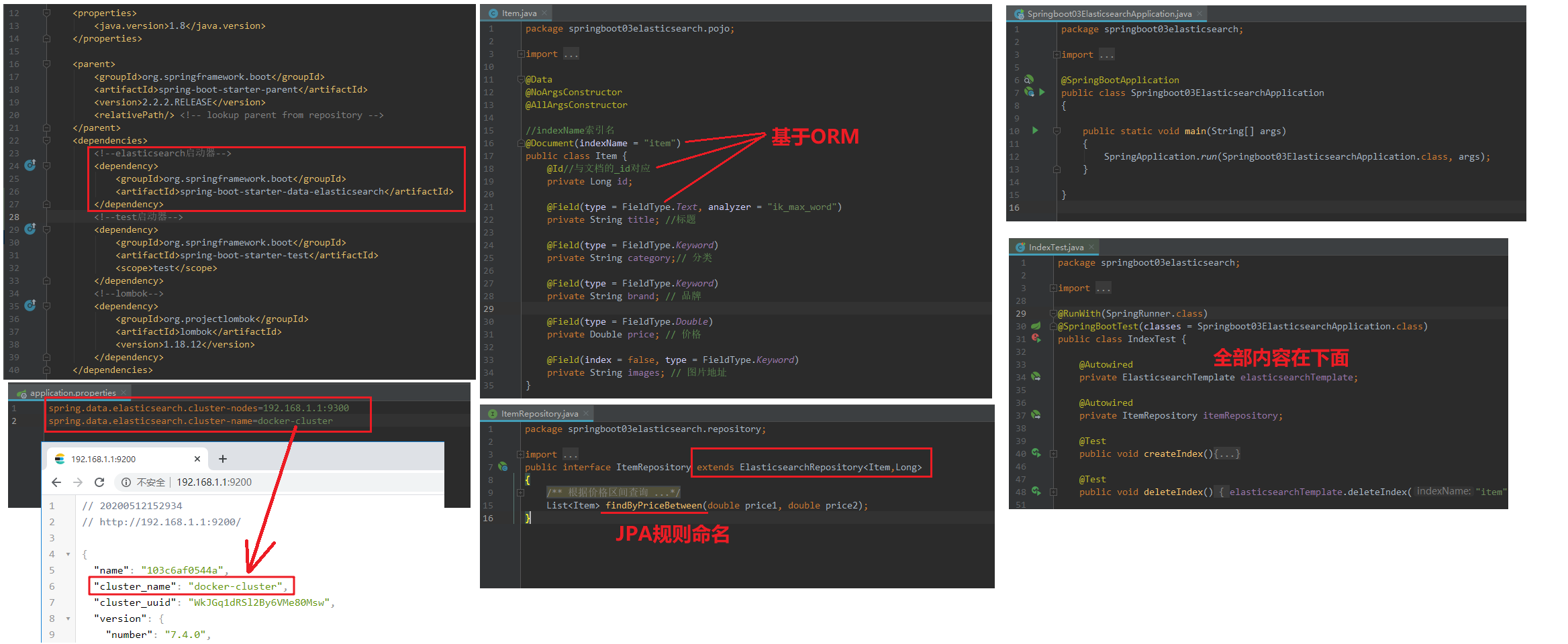
2)、JPA的方法命名规范
参考文档spring-data-jpa
3)、IndexTest.java 单元测试
1 | (SpringRunner.class) |