案例效果
先上一张图,看看是否符合你的要求。再往下看。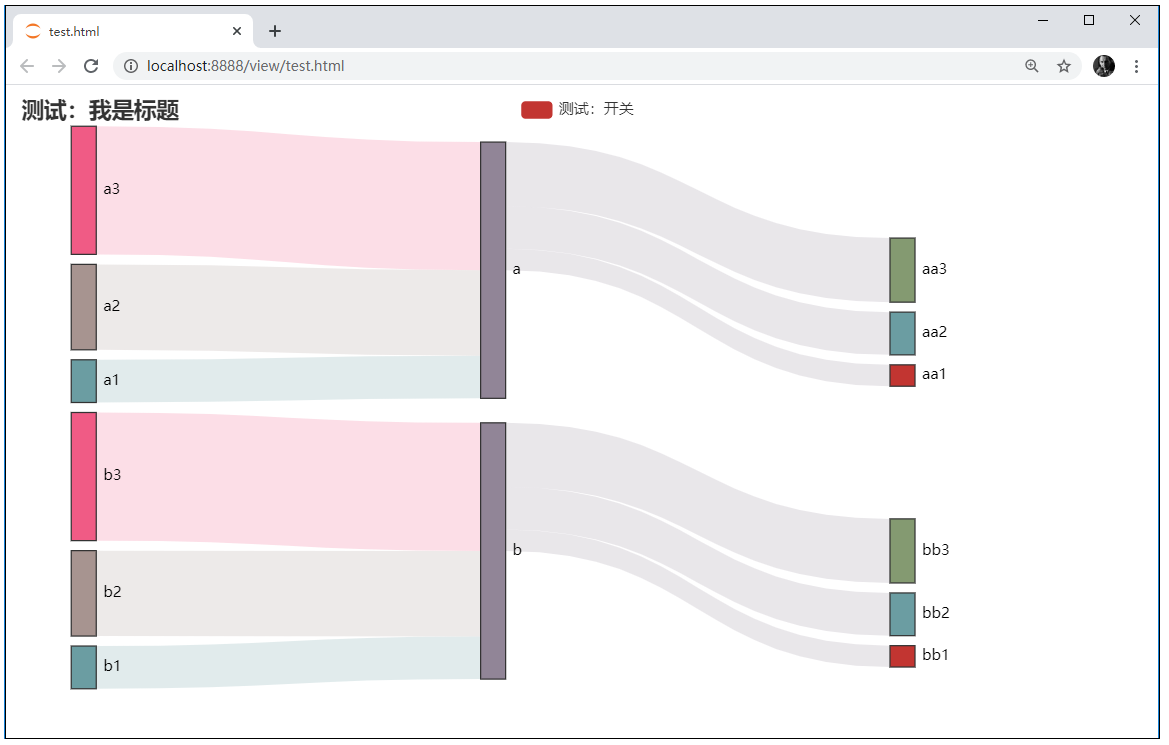
说明一下
在安装之前要有Python的环境,没有的话可参考Python3.8.2安装
要正确配置Python的环境变量,下面我使用pip3命令是因为我的Scripts目录下有pip3.exe,pip3.8.exe文件。
当前我也可以使用pip3.8命令,如果你只有pip.exe就使用pip命令来替换pip3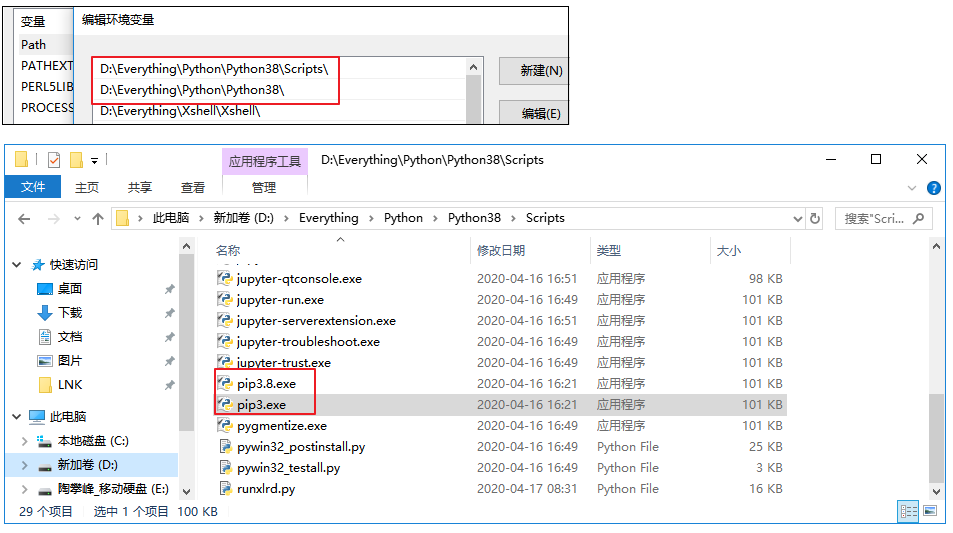
安装jupyter notebook
- 当时我刚开始安装的时候特别慢,10KB/S以内,后来知道是还需要配置镜像
1
2
3
4
5
6# 安装jupyter【所要安装的依赖比较多,慢慢等待,我当时安装速度是350KB/S左右】
pip3 install jupyter -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# 启动
# 默认访问地址:http://localhost:8888/tree
jupyter notebook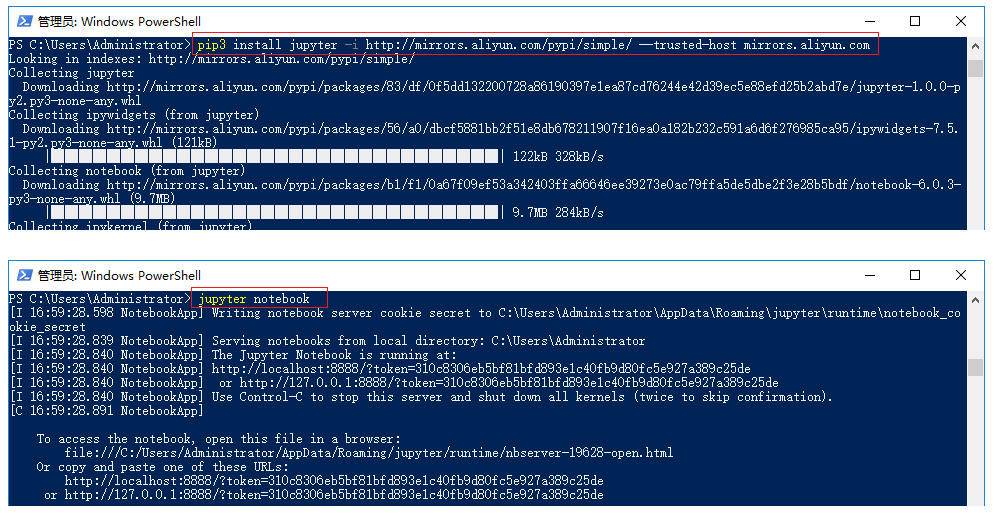
过程(重点)
- 安装
模块1所需依赖1
2
3
4
5
6
7
8# 解决问题`ModuleNotFoundError: No module named 'pyecharts'`
pip3 install pyecharts -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# 解决问题`ModuleNotFoundError: No module named 'pandas'`
pip3 install pandas -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# 解决问题`ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.`
pip3 install xlrd -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com jupyter notebook编辑.ipynb文件,使用pyecharts生成Sankey桑基图的HTML文件(代码解释)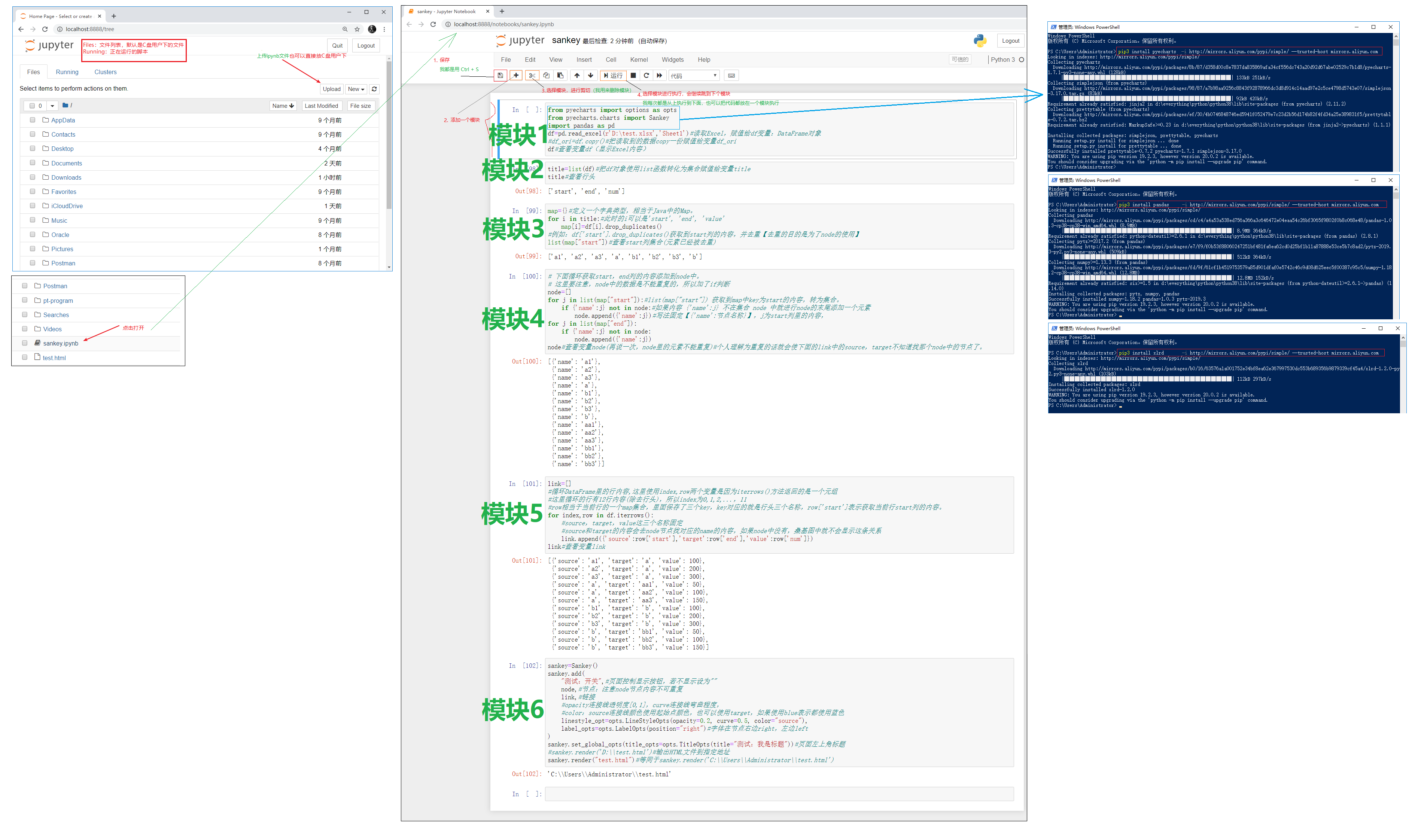
- 打开生产的HTML文件
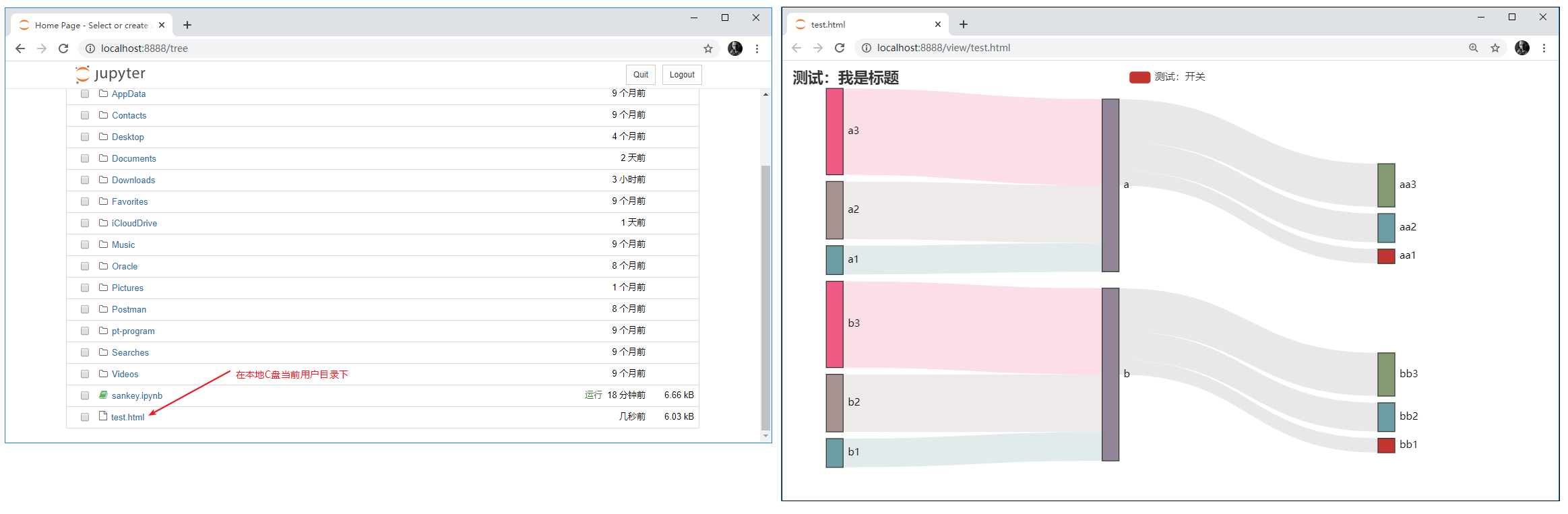
案例文件
案例文件sankey.ipynb,test.xlsx,test.html已上传到桑基图案例文件
ipynb文件的六个模块
- 模块1
1
2
3
4
5
6from pyecharts import options as opts
from pyecharts.charts import Sankey
import pandas as pd
df=pd.read_excel(r'D:\test.xlsx','Sheet1')#读取Excel,赋值给df变量:DataFrame对象
#df_ori=df.copy()#把读取到的数据copy一份赋值给变量df_ori
df#查看变量df(显示Excel内容) - 模块2
1
2title=list(df)#把df对象使用list函数转化为集合赋值给变量title
title#查看行头 - 模块3
1
2
3
4
5map={}#定义一个字典类型,相当于Java中的Map。
for i in title:#此时的i可以是'start', 'end', 'value'
map[i]=df[i].drop_duplicates()
#例如:df['start'].drop_duplicates()获取到start列的内容,并去重【去重的目的是为了node的使用】
list(map["start"])#查看start列集合(元素已经被去重) - 模块4
1
2
3
4
5
6
7
8
9
10# 下面循环获取start,end列的内容添加到node中。
# 这里要注意,node中的数据是不能重复的,所以加了if判断
node=[]
for j in list(map["start"]):#list(map["start"]) 获取到map中key为start的内容,转为集合。
if {'name':j} not in node:#如果内容 {'name':j} 不在集合 node 中就进行node的末尾添加一个元素
node.append({'name':j})#写法固定【{'name':节点名称}】,j为start列里的内容,
for j in list(map["end"]):
if {'name':j} not in node:
node.append({'name':j})
node#查看变量node(再说一次,node里的元素不能重复)#个人理解为重复的话就会使下面的link中的source,target不知道找那个node中的节点了。 - 模块5
1
2
3
4
5
6
7
8
9link=[]
#循环DataFrame里的行内容,这里使用index,row两个变量是因为iterrows()方法返回的是一个元组
#这里循环的行有12行内容(除去行头),所以index为0,1,2,...,11
#row相当于当前行的一个map集合,里面保存了三个key,key对应的就是行头三个名称,row['start']表示获取当前行start列的内容。
for index,row in df.iterrows():
#source,target,value这三个名称固定
#source和target的内容会去node节点找对应的name的内容,如果node中没有,桑基图中就不会显示这条关系
link.append({'source':row['start'],'target':row['end'],'value':row['num']})
link#查看变量link - 模块6
1
2
3
4
5
6
7
8
9
10
11
12
13sankey=Sankey()
sankey.add(
"测试:开关",#页面控制显示按钮,若不显示设为""
node,#节点:注意node节点内容不可重复
link,#链接
#opacity连接线透明度[0,1],curve连接线弯曲程度,
#color:source连接线颜色使用起始点颜色,也可以使用target,如果使用blue表示都使用蓝色
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right")#字体在节点右边right,左边left
)
sankey.set_global_opts(title_opts=opts.TitleOpts(title="测试:我是标题"))#页面左上角标题
#sankey.render('D:\\test.html')#输出HTML文件到指定地址
sankey.render("test.html")#等同于sankey.render('C:\\Users\\Administrator\\test.html') - 模块6也可使用以下方式替换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15do=(
Sankey()
.add(
"测试:开关",#页面控制显示按钮,若不显示设为""
node,#节点:注意node节点内容不可重复
link,#链接
#opacity连接线透明度[0,1],curve连接线弯曲程度,
#color:source连接线颜色使用起始点颜色,也可以使用target,如果使用blue表示都使用蓝色
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right")#字体在节点右边right,左边left
)
.set_global_opts(title_opts=opts.TitleOpts(title="测试:我是标题"))#页面左上角标题
#sankey.render('D:\\test.html')#输出HTML文件到指定地址
.render("test2.html")#等同于sankey.render('C:\\Users\\Administrator\\test.html')
)