常用补充
2023-09-22 10:58:24 补
1 | # 登录 && 退出 |
登录&退出
1 | * MySQL登录 |
SQL
1 | 1. 什么是SQL? |
注释&表信息
1 | --查看表注释 |
DDL
数据定义语言(data definition language)
操作数据库
1 | 1. C(Create):创建 |
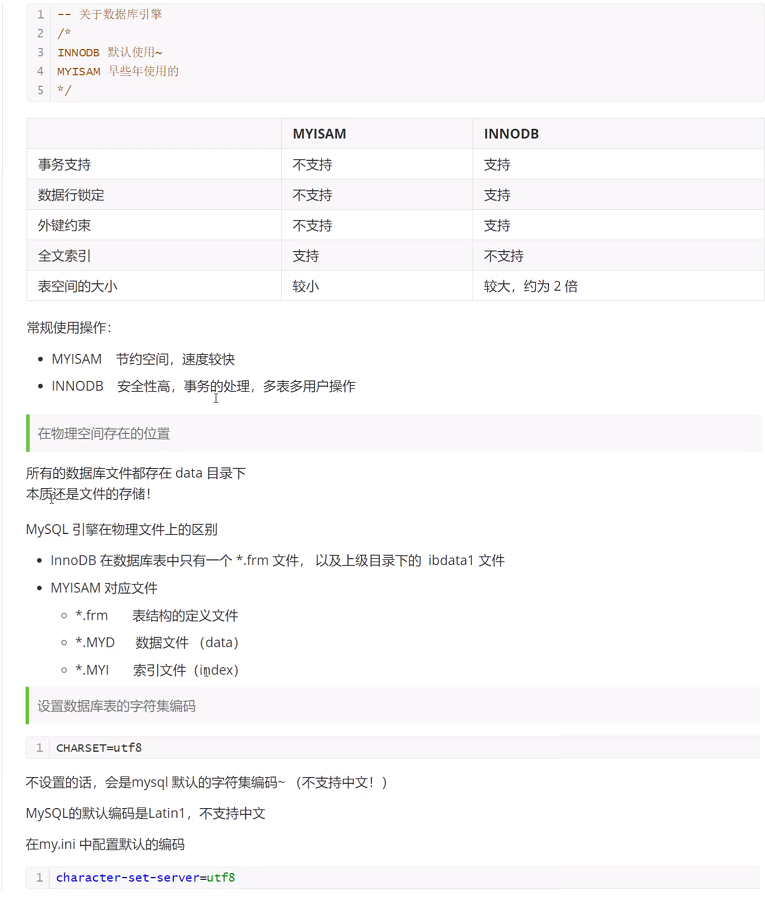
INNODB/MYISAM
操作表
- C(Create):创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
311. 语法:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
....
列名n 数据类型n
);
* 注意:最后一列,不需要加逗号(,)
* 数据库类型:
1. int:整数类型
* age int,
2. double:小数类型
* score double(5,2)
3. date:日期,只包含年月日,yyyy-MM-dd
4. datetime:日期,包含年月日时分秒 yyyy-MM-dd HH:mm:ss
5. timestamp:时间错类型 包含年月日时分秒 yyyy-MM-dd HH:mm:ss
* 如果将来不给这个字段赋值,或赋值为null,则默认使用当前的系统时间,来自动赋值
6. varchar:字符串
* name varchar(20):姓名最大20个字符
* zhangsan 8个字符 张三 2个字符
* 创建表
create table student(
id int,
name varchar(32),
age int ,
score double(4,1),
birthday date,
insert_time timestamp
);
* 复制表:
* create table 表名 like 被复制的表名; - R(Retrieve):检索
1
2
3
4
5
6
7
8
9
10* 查询某个数据库中所有的表名称
* show tables;
* show create table 表名称;
* 查询表结构
* describe 表名;
* desc 表名;
* 查看表t1的索引信息
* SHOW INDEX FROM t1;
* 最后一个插入的数据,自增ID的值是多少
* SELECT @last := LAST_INSERT_ID(); - U(Update):修改
1
2
3
4
5
6
7
8
9
10
111. 修改表名
alter table 表名 rename to 新的表名;
2. 修改表的字符集
alter table 表名 character set 字符集名称;
3. 添加一列
alter table 表名 add 列名 数据类型;
4. 修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
5. 删除列
alter table 表名 drop 列名; - D(Delete):删除
1
2* drop table 表名;
* drop table if exists 表名 ;
DML
数据操作语言(Data Manipulation Language)
INSERT
1 | 添加数据: |
1 | --正确,因为用于col2的值引用了col1,而col1已经被赋值 |
1 | --如果t1存在主键s1=1,就更新数据s2=999【受影响行的值为2。】 |
UPDATE
1 | 修改数据: |
1 | --先*2 再+5 |
DELETE
1 | 删除数据: |
1 | --删除单个表 |
DQL
数据查询语言(data query language)
执行顺序
1 | select |
运算符
1 | > 、< 、<= 、>= 、= 、<> |
DCL
数据控制语言(Data Control Language)
【DBA:数据库管理员】
管理用户
1 | 1. 创建用户: |
1 | CREATE USER 'username'@'host' IDENTIFIED BY 'password'; #创建用户 |
管理权限
1 | 1. 查询权限: |
SELECT
版本
1 | select version(); |
DUAL临时表
1 | --在没有表被引用的情况下,允许您指定DUAL作为一个假的表名。 |
HAVING
HAVING不能用于应被用于WHERE子句的条目。
1 | --错误写法 |
LIMIT
1 | LIMIT子句可以被用于限制被SELECT语句返回的行数。 |
1 | --返回第6~15条记录。 |
多表关联
1 | --别名: |
- 笛卡尔积(交叉相乘)【一般我的用法】:
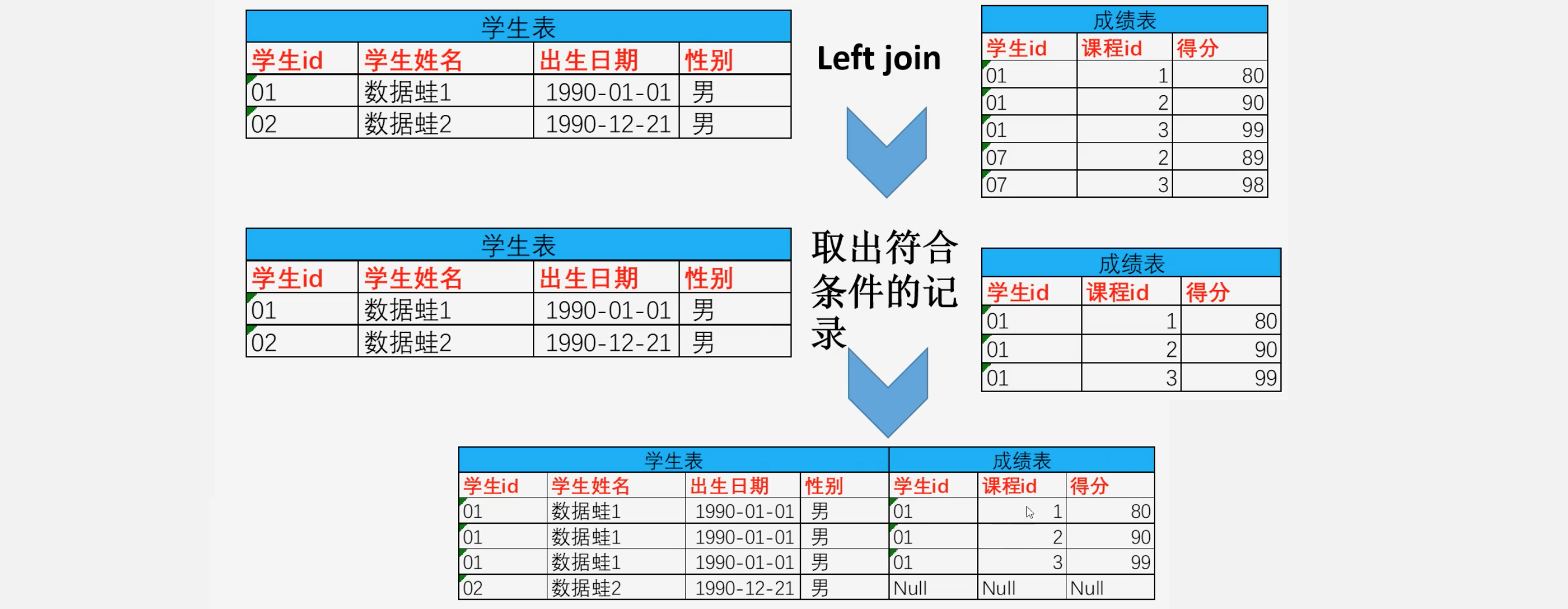
SELECT * FROM student,grade WHERE student.s_g_id=grade.g_id [and xxx='xxx'] - 左连接连接规则如下(右连接也是同理,只不过以右表为准了)
子查询
1 | 一个子查询会返回一个标量(单一值)、一个行、一个列或一个表(一行或多行及一列或多列)。 |
子查询作为标量操作数
1 | CREATE TABLE t1 (s1 INT, s2 CHAR(5) NOT NULL); |
1 | DROP TABLE t1 |
1 | --正确写法 |
用子查询进行比较
语法
1 | non_subquery_operand comparison_operator (subquery) |
1 | --表t1中有些值与表t2中的最大值相同。 |
IN,ANY,SOME
语法
1 | operand IN (subquery) |
1 | ANY的意思是“对于在子查询返回的列中的任一数值,如果比较结果为TRUE的话,则返回TRUE” |
ALL
语法
1 | operand comparison_operator ALL (subquery) |
1 | ALL的意思是“对于子查询返回的列中的所有值,如果比较结果为TRUE,则返回TRUE。” |
总结一下:只要后者有null,结果就为false。返回null。
1 | --NOT IN是<> ALL的别名。因此,这两个语句是相同的 |
行子查询
1 | 这里讨论属于标量或列子查询,即返回一个单一值或一列值的子查询。 |
1 | --如果在表t2的一个行中,column1=1并且column2=2,则查询结果均为TRUE。 |
1 | 行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。 |
EXISTS和NOT EXISTS
1 | --EXISTS只要子查询记录大于0,无论是否有null,都会为true |
优化子查询
1 | --子查询,转化为联合 |
约束
简介
- 概念
1
对表中的数据进行限定,保证数据的正确性、有效性和完整性。
- 分类
1
2
3
41. 主键约束:primary key
2. 非空约束:not null
3. 唯一约束:unique
4. 外键约束:foreign key
非空约束
:not null,值不能为null
1 | 1. 创建表时添加约束 |
唯一约束
:unique,值不能重复
1 | 1. 创建表时,添加唯一约束 |
主键约束
:primary key。
1 | 1. 注意: |
外键约束
:foreign key,让表于表产生关系,从而保证数据的正确性。
1 | 1. 在创建表时,可以添加外键 |
备份&还原
数据复制
1 | --新表不存在,创建与旧表结构一样的新表,但不会设置主键,再把数据添加到新表。 |
1 | --tableName2 表可以不存在,会在执行的过程中自动创建。 |
三大范式
- 概述
1
2
3
4
5
6
7
81NF:字段不可分;
2NF:有主键,非主键字段依赖主键;
3NF:非主键字段不能相互依赖;
解释:
1NF:原子性 字段不可再分,否则就不是关系数据库;
2NF:唯一性 一个表只说明一个事物;
3NF:每列都与主键有直接关系,不存在传递依赖; - 不符合第一范式的例子(关系数据库中create不出这样的表):
1
2
3表:字段1, 字段2(字段2.1, 字段2.2), 字段3 ......
存在问题: 因为设计不出这样的表, 所以没有问题; - 不符合第二范式的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13表:学号, 姓名, 年龄, 课程名称, 成绩, 学分;
这个表明显说明了两个事务:学生信息, 课程信息;
存在问题:
数据冗余:每条记录都含有相同信息;
删除异常:删除所有学生成绩,就把课程信息全删除了;
插入异常:学生未选课,无法记录进数据库;
更新异常:调整课程学分,所有行都调整。
修正:
学生:Student(学号, 姓名, 年龄);
课程:Course(课程名称, 学分);
选课关系:SelectCourse(学号, 课程名称, 成绩)。
满足第2范式只消除了插入异常。 - 不符合第三范式的例子:
1
2
3
4
5
6
7
8
9
10学号, 姓名, 年龄, 所在学院, 学院联系电话,关键字为单一关键字"学号";
存在依赖传递: (学号) → (所在学院) → (学院地点, 学院电话)
存在问题:
数据冗余:有重复值;
更新异常:有重复的冗余信息,修改时需要同时修改多条记录,否则会出现数据不一致的情况
删除异常
修正:
学生:(学号, 姓名, 年龄, 所在学院);
学院:(学院, 地点, 电话)。
事务
基本介绍
1 | 1. 概念: |
四大特征
1 | 1. 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败。 |
四种隔离级别
1 | * 概念:多个事务之间隔离的,相互独立的。 |
七种传播机制
可参考Spring事务的隔离级别和传播特性
别名:传播机制 传播特性 传播行为 传播方式
1 | # 常用 |
事务SQL
1 | SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; |
个人理解
以下纯个人见解(有些东西自己知道,实在是难以表述,下面逻辑可能混乱。):
1 | SESSION 与 GLOBAL 的区别: |