迭代器原理
在HashMap的entrySet与keySet区别?源码分析一文中也有提到.
要想成为迭代器,必须实现Iterable接口,而且还要重写它的iterator()方法进行返回迭代器对象.
如果不重写foreach方法,就调用默认的方法,这个我们在下面会讲到.
关于spliterator方法不做讲解
Iterable
1 | public interface Iterable<T> { |
Iterable的意思是可迭代的;可迭代对象;Collection集合接口继承它,重写iterator()方法,调用它用来返回一个迭代器,可使用迭代器进行遍历.
也可调用它的foreach方法,它里面有一个for循环也可进行遍历.
下面我们按照顺序先来看看iterator()方法,
Iterator
1 | public interface Iterator<E> { |
Iterator的意思是迭代器,说明实现它的类就成了迭代器,必须重写hasNext() next()两个方法.
其中hasNext()是用来判断是否有下一个值,有返回true(才能往下进行迭代),无返回false(终止迭代).next()方法是用来返回下一个要遍历的值,如果hasNext()为true,才能执行next()来返回下一个值.(这时有明确的先后关系的)
所以说迭代器遍历数据的原理,遍历数据的顺序
- 先通过
iterator()获取迭代器, - 调用迭代器的
hasNext()方法,看是否能迭代, - 如果可迭代,调用迭代器的
next()方法返回下一个迭代的值, - 执行循环体,执行完之后,再进行判断
hasNext()方法 …
for循环就是使用迭代器来循环的,其本质上和while循环无太大区别,只不过简化了写法,
下面是两种用法示例,其效果是相同的.(这里的HashMap在后面会进行讲解)
1 | HashMap<String,String> hashMap=new HashMap<>(); |
分析完了iterator(),我们来分析一下foreach方法,它的参数是Consumer,下面我们来看一下
Consumer
1 | /* 拿出`Iterable`的foreach方法,方便查看 */ |
1 | /* 这是一个函数接口 */ |
下面进行改写
1 | HashMap<String,String> hashMap=new HashMap<>(); |
当然你也可以重写它的foreach方法,这里本质上我们将讲完了集合是如果遍历的数据.
ArrayList
extends,implements关系
1 | public class ArrayList<E> extends AbstractList<E> |
实现了List(列表)接口,
List继承Collection(集合)节口,
而Collection节口又继承了Iterable(迭代器)接口,才可以使迭代成为可能.
基本属性
1 | private static final int DEFAULT_CAPACITY = 10; |
可以看出,默认容量大小是10.后面会讲到最小为10.
内部是由Object数组构成的.
size用于记录集合的大小.添加+1,移除-1,清除=0.
modCount结构改变一次,就+1
构造方法
1 | public ArrayList() { |
无参构造默认为空.有参构造可指定集合默认大小.
增
尾插入
1 | public boolean add(E e) { |
由上面注释,我们可以知道,在插入的时候,会进行对数组大小初始化,也就是容量.
在插入之前先进行试探,如果超出数组长度进行1.5倍扩容.
如果扩容后大小还是没试探数(size + 1)大的话,扩容就为试探数.
如果扩容后大小超出默认最大值,扩容大小就为Integer.MAX_VALUE
添加成功会返回true,内部的结构变化记录数modCount在扩容,插入前会+1
指定位置插入
1 | public void add(int index, E element) { |
关于上面的System.arraycopy(elementData, index, elementData, index + 1,size - index);
举个例子:
例如长度为10的原数组,数据为{11,22,33,null,null,null,null,null,null,null}此时size=3.
执行add(1,88);数组就会变为{11,88,22,33,null,null,null,null,null,null}此时size=4.
参数含义
- 原数组
- 从元数据的起始位置开始
- 目标数组
- 目标数组的开始起始位置
- 要copy的数组的长度
也就是把>=index的数据下标都+1了,在index位置插入你指定的数据.
删
删除指定的第一个数据
1 | public boolean remove(Object o) { |
指定位置进行删除
1 | public E remove(int index) { |
同上,主要是删除前检查指定的index是否符合.
改
指定位置修改
1 | public E set(int index, E element) { |
把指定位置的数据进行修改,把旧值进行返回.
查
获取指定位置数据
1 | public E get(int index) { |
这个没什么好说的,直接获取值.
其他方法
交集,差集,并集
1 | public static void main(String[] args) |
size返回集合大小
1 | public int size() { |
clear清空数据
1 | public void clear() { |
isEmpty检查是否为空
1 | public boolean isEmpty() { |
indexOf返回第一个指定数据的下标
1 | public int indexOf(Object o) { |
lastIndexOf返回最后一个指定数据的下标
1 | public int lastIndexOf(Object o) { |
contains是否含有某个数据
1 | public boolean contains(Object o) { |
subList截取集合
如果集合是{a,b,c,d,e},截取subList(2,3);//{c}
所以,区间表示[2,3)包含前面的,不包含后面的.(前包后不包)
1 | public List<E> subList(int fromIndex, int toIndex) { |
LinkedList
继承关系
1 | public class LinkedList<E> |
实现了List集合,Deque双端队列.
基本属性
1 | private static class Node<E> { |
右上面可以看到,他是双向的链接,内部由头和尾节点进行维护.
构造方法
1 | public LinkedList() { |
增
头插入
1 | public boolean offerFirst(E e) { |
尾插入
1 | public boolean offer(E e) { |
1 | public boolean add(E e) { |
可以看出,如果当前插入的是第一个节点,将首尾节点都指向当前节点.
如果不是,就将尾节点指向当前节点,插入前的尾节点的下一个节点指向当前节点,
也就是把当前节点追加到链表最后.
指向位置插入
1 | public void add(int index, E element) { |
删
删除第一个
为空抛异常
1 | public E remove() { |
为空返回null
1 | public E poll() { |
删除最后一个
为空抛异常
1 | public E removeLast() { |
为空返回null
1 | public E pollLast() { |
删除指定位置元素
1 | public E remove(int index) { |
删除指定的第一个数据
1 | public boolean removeFirstOccurrence(Object o) { |
删除指定的最后一个数据
1 | public boolean removeLastOccurrence(Object o) { |
改
指定位置修改
1 | public E set(int index, E element) { |
查
获取第一个节点数据
为空抛异常
1 | public E element() { |
为空返回null
1 | public E peek() { |
获取最后一个节点数据
为空抛异常
1 | public E getLast() { |
为空返回null
1 | public E peekLast() { |
获取指定位置节点数据
1 | public E get(int index) { |
其他方法
size返回集合大小
1 | public int size() { |
clear清空数据
1 | public void clear() { |
indexOf返回第一个指定数据的下标
1 | public int indexOf(Object o) { |
lastIndexOf返回最后一个指定数据的下标
1 | public int lastIndexOf(Object o) { |
contains是否含有某个数据
1 | public boolean contains(Object o) { |
Vector
同ArrayList一样,只不过Vector的方法都加了synchronized,数组的扩容机制不同(默认2倍扩容).
只要看到了ArrayList,Vector也就好理解了,这里就不做过多的阐述了.
extends,implements关系
1 | public class Vector<E> |
和ArrayList继承关系相同.
基本属性
1 | // 底层数组维护,长度默认10 |
同ArrayList一样,也是由数组进行维护,但是增加了扩容增量的概念,后面会讲到.
为什么要有Vector呢? 下面我们来继续往下看
构造方法
1 | public Vector() { |
由上可以看出,底层维护的数组长度默认10,扩容增量默认0
增
尾插入
1 | // 无返回值 |
指定位置插入
1 | public void add(int index, E element) { |
删
删除指定下标数据
1 | // 返回被删除的值 |
删除第一个指定数据
1 | public boolean remove(Object o) { |
删除全部
1 | public void clear() { |
改
修改指定位置数据
1 | // 返回原值 |
查
返回第一个数据
1 | public synchronized E firstElement() { |
返回最后一个数据
1 | public synchronized E lastElement() { |
返回指定位置数据
1 | public synchronized E get(int index) { |
其他方法
size返回集合大小
1 | public synchronized int size() { |
setSize设置集合大小
1 | public synchronized void setSize(int newSize) { |
isEmpty
1 | public synchronized boolean isEmpty() { |
indexOf
返回第一个数据的下标
1 | public int indexOf(Object o) { |
返回[index,elementCount-1]第一个数据的下标
1 | public synchronized int indexOf(Object o, int index) { |
lastIndexOf
返回最后一个数据的下标
1 | public synchronized int lastIndexOf(Object o) { |
返回[0,index]最后一个数据的下标
1 | public synchronized int lastIndexOf(Object o, int index) { |
capacity返回容量
也就是内部数组的长度
1 | public synchronized int capacity() { |
contains是否含有某个数据
1 | public boolean contains(Object o) { |
subList截取集合
如果集合是{a,b,c,d,e},截取subList(2,3);//{c}
所以,区间表示[2,3)包含前面的,不包含后面的.(前包后不包)
1 | public synchronized List<E> subList(int fromIndex, int toIndex) { |
trimToSize内部数组长度变为集合大小
1 | public synchronized void trimToSize() { |
HashMap
extends,implements关系
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
属性
1 | // 把key和value封装成Node节点,数组的长度是2次幂. |
构造函数
HashMap()
1 | public HashMap() { |
无参构造方法
构造一个空的HashMap,初始容量为16,负载因子为0.75
注意:(此时还未指定初始容量,在扩容时指定默认16)
HashMap(int initialCapacity)
1 | public HashMap(int initialCapacity) { |
构造一个空的HashMap,指定容量,负载因子也为0.75HashMap(int initialCapacity)这个构造方法调用了下面的构造方法.
HashMap(int initialCapacity, float loadFactor)
1 | // 3.构造一个空的初始容量为initialCapacity,负载因子为loadFactor的HashMap |
构造一个空的HashMap,指定容量,指定负载因子
设置阈值,阈值=容量*负载因子,当HashMap的size到了阈值时,就要进行resize,也就是扩容.tableSizeFor(initialCapacity)的主要功能就是返回一个2的次方数,如给定18,返回2的5次方(32)
1 | static final int tableSizeFor(int cap) { |
注意 HashMap要求容量必须是2的次方数.
这里cap为指定的容量,并且范围是[0,MAXIMUM_CAPACITY],如果指定容量小于等于2^n,就返回2^n,这里n取[0,30]
直接演示一下,为什么要使用右移运算,因为int是32位,
假设开始的n为00000000 000001xx xxxxxxxx xxxxxxxx,这里我们只管最前面那个1的值,后面都不管.n |= n >>> 1;可以理解为n = n | (n >>> 1);>>>右移运算可以理解为无论正负右移n位,右边去除n位,左边补n个0按位或运算只要有一个是1,结果就为1
如果还是不懂这两个运算,可以查看
位运算
- 第一次右移
n |= n >>> 1;00000000 000001xx xxxxxxxx xxxxxxxx00000000 0000011x xxxxxxxx xxxxxxxx - 第二次右移
n |= n >>> 2;00000000 0000011x xxxxxxxx xxxxxxxx00000000 00000111 1xxxxxxx xxxxxxxx - 第三次右移
n |= n >>> 4;00000000 0000011x xxxxxxxx xxxxxxxx00000000 00000111 11111xxx xxxxxxxx
…
由上我们可知,n为指定的容量-1,右移31次,可以把第一个1后面全部变为1,最后+1就成了2的次方数.
HashMap(Map<? extends K, ? extends V> m)
1 | public HashMap(Map<? extends K, ? extends V> m) { |
构造一个和指定Map有相同映射的HashMap,初始容量能充足的容下指定的Map,负载因子为0.75
直接看putMapEntries(m, false);
1 |
|
在下面目录增中介绍resize扩容和putVal添加
增
这里是HashMap最难理解的两个方法,resize扩容和putVal添加,当然红黑树就不看了.
1 | public V put(K key, V value) { |
进入putVal插入方法之前,先看一下下面的hash操作
1 | static final int hash(Object key) { |
这里是使高16位与低16位进行异或运算,异或运算同为0,不同才为1,
举个例子:
1111 1111 1111 1111 0100 1100 0000 1010=原hashcode
0000 0000 0000 0000 1111 1111 1111 1111=右移16位
1111 1111 1111 1111 1011 0011 1111 0101=异或结果
这样做的好处是,可以将hashcode高位和低位的值进行混合做异或运算,而且混合后,低位的信息中加入了高位的信息,
这样高位的信息被变相的保留了下来。掺杂的元素多了,那么生成的hash值的随机性会增大(冲突几率减小)。
刚才我们漏掉了resize()和putVal()两个函数,现在我们按顺序分析一波:
resize扩容
首先resize() ,先看一下哪些函数调用了resize(),从而在整体上有个概念: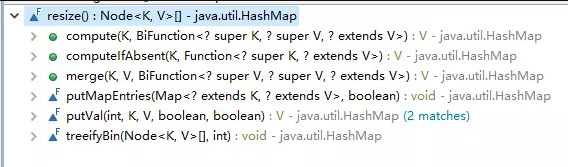
1 | final Node<K,V>[] resize() { |
1 | xxxxxxxx xxxxxxxx xxxxxxxx xxx10111 =假设当前循环节点e.hash |
扩容的情况
- size > threshold,进行2倍扩容(不一定)
- table==null(初始化)
扩容(resize)其实就是重新计算容量;而这个扩容是计算出所需容器的大小之后重新定义一个新的容器,将原来容器中的元素放入其中。
putVal添加
下面介绍putVal方法,先介绍他们参数1:hashkey的hashcode高16位与低16位异或运算得出的一个int值参数2:keykey参数3:valuevalue参数4:onlyIfAbsent它翻译为只有在没有,为true表示不覆盖,为false表示覆盖旧值参数5:evict它翻译为逐出,为false表示创建模式,为true则为非创建模式
调用它的其中三种情况:
- 构造函数
HashMap(Map<? extends K, ? extends V> m)中调用putMapEntries(m, false);,会调用putVal(hash(key), key, value, false, evict);
把传入的Map构造成HashMap时,把Map中的值添加到HashMap中,表示不覆盖,是创建模式. - 添加数据
put(K key, V value)中调用putVal(hash(key), key, value, false, true);
表示覆盖旧值,不是创建模式. - 添加数据
putIfAbsent(K key, V value)(实现Map接口方法)中调用putVal(hash(key), key, value, true, true);
表示不覆盖旧值,不是创建模式.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*
1. 表为空,初始化表
*/
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/*
2. 定位的位置为空,直接在此位置插入
*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
/*
3. 定义的位置有节点了,下面要分情况处理
*/
else {
Node<K,V> e; K k;
// 情况1,当前定位的节点是链表的第一个节点,获取此节点.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 情况2,当前定位的节点是红黑树节点,使用`putTreeVal`去红黑树中找到我们的节点.
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 情况3,当前定位的节点不是第一个节点,需要进行遍历查找我们想要的节点.
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// (1)找到链表的尾端还没找到,直接构造一个新节点,进行尾插入.
// 插入之后,链表长度>=8的时候,链表转化为红黑树
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
// (2)找到我们要插入的节点,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 我们获取的那个节点不为空,返回旧值.
// 如果旧值不为空,或入参onlyIfAbsent为false,替换新值.
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);//LinkedHashMap会用到
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);//LinkedHashMap会用到
return null;
}
删
删除指定key节点
1 | public V remove(Object key) { |
删除指定key,value节点
1 | // 实现了Map接口 |
清空数据
1 | public void clear() { |
改
修改指定key节点的value
1 | // 实现Map接口方法 |
修改指定key,value节点的value
1 |
|
查
根据key获取value
1 | public V get(Object key) { |
(重要)entrySet获取所有key和value
HashMap的entrySet与keySet区别?源码分析
1 | public Set<Map.Entry<K,V>> entrySet() { |
keySet获取所有key
同上
1 | public Set<K> keySet() { |
values获取所有value
同上
1 | public Collection<V> values() { |
其他方法
size返回集合大小
1 | public int size() { |
isEmpty检查是否为空
1 | public boolean isEmpty() { |
containsKey是否含有某个key
1 | public boolean containsKey(Object key) { |
containsValue是否含有某个value
从Node数组0,依次往后找,找到链表,再循环链表,直到找到value进行返回true.
1 | public boolean containsValue(Object value) { |
LinkedHashMap
在上面讲解到HashMap时,部分用到了LinkedHashMap的方法,添加数据时用到:afterNodeAccess(e); afterNodeInsertion(evict);删除数据时用到:afterNodeRemoval(node);替换数据时用到:afterNodeAccess(e);
这三个方法也是LinkedHashMap与HashMap的区别所在,我们下面来往下看 ->
extends,implements关系
1 | public class LinkedHashMap<K,V> |
可以看出LinkedHashMap继承了HashMap,也就是它可以使用或重写HashMap中的方法,并可以使用HashMap中属性.
属性
1 | transient LinkedHashMap.Entry<K,V> head; |
可以看出,这同LinkedList似的,由原本HashMap数组+单向链表+红黑树维护,变成了双向链表维护.
内部类Entry
1 | static class Entry<K,V> extends HashMap.Node<K,V> { |
可以看出,它继承HashMap的Node节点,但是它多出了两个属性before after
其中before表示上一个节点,after表示下一个节点.
构造方法
LinkedHashMap()
1 | public LinkedHashMap() { |
LinkedHashMap(int initialCapacity)
1 | public LinkedHashMap(int initialCapacity) { |
LinkedHashMap(int initialCapacity, float loadFactor)
1 | public LinkedHashMap(int initialCapacity, float loadFactor) { |
LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)
除了这个可以指定内部的顺序,其他的都不可以指定,accessOrder = true按照访问顺序来排序accessOrder = false默认插入顺序来排序
1 | public LinkedHashMap(int initialCapacity, |
LinkedHashMap(Map<? extends K, ? extends V> m)
1 | public LinkedHashMap(Map<? extends K, ? extends V> m) { |
与HashMap的不同点
newNode(int hash, K key, V value, Node<K,V> e)
1 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { |
afterNodeAccess(Node<K,V> e)
1 | void afterNodeAccess(Node<K,V> e) { |
进来的情况:不是尾节点,并且是访问顺序来排序.
假设有四个节点a,b,c,d
情况1:get(a):排序之后b,c,d,a
情况2:get(b):排序之后a,c,d,b
情况3:get(c):同上,排序之后a,b,d,c
情况4:get(d):是尾节点,不会进行排序
总结:访问谁,把谁断开进行尾插。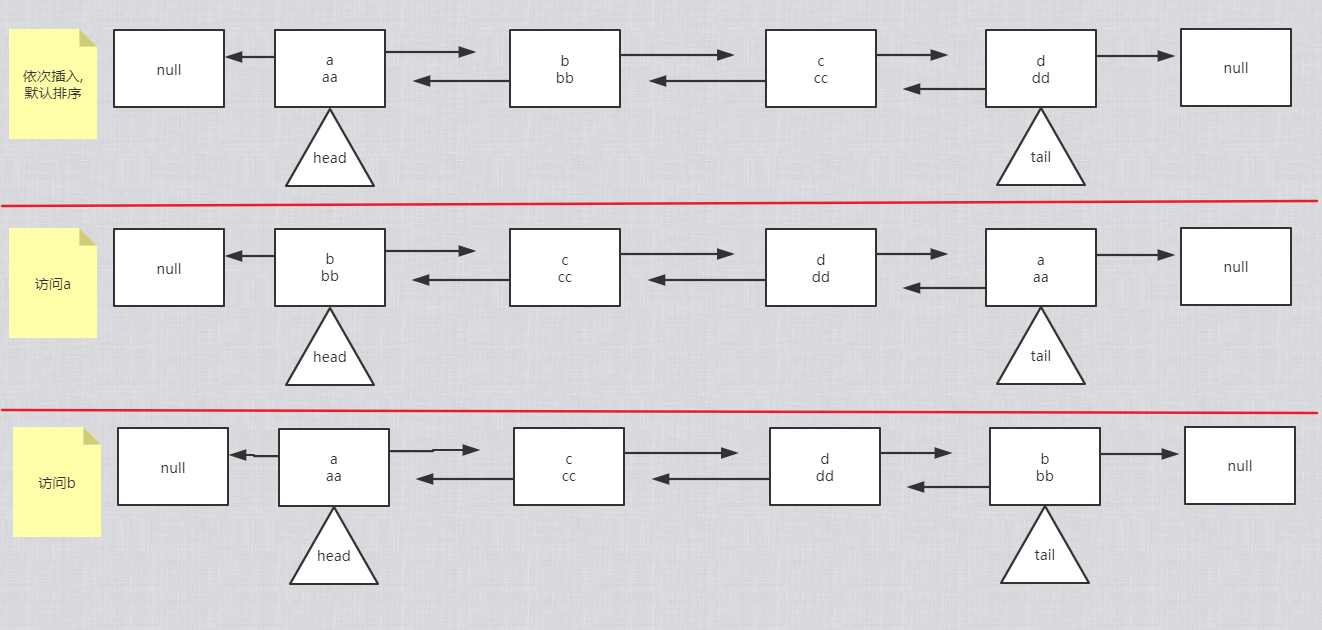
afterNodeInsertion(boolean evict)
1 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
因为removeEldestEntry(first)会返回false,所以此方法暂无意义,
这里盲猜应该是继承LinkedHashMap的类会用到此方法.
afterNodeRemoval(Node<K,V> e)
1 | void afterNodeRemoval(Node<K,V> e) { // unlink |
看了上面注释,总结一下:就是把访问的那个节点断开进行尾插,把断开处前后相连,如果是头节点或尾节点再对head和tail的指向做处理.
插入
这个在HashMap分析时已经讲到,这里主要讲不同的地方.
1 | public V put(K key, V value) { |
删除
1 | final Node<K,V> removeNode(int hash, Object key, Object value, |
替换
1 | public V replace(K key, V value) { |
获取
1 | public V get(Object key) { |
循环方式不同
1 | public boolean containsValue(Object value) { |
都是由head也就是第一个节点,开始往后循环,直到循环到尾节点.
也就是说默认循环的顺序与插入的顺序有关,
如果指定了访问顺序为true,就与访问顺序有关,上面我们说到了,访问节点会把要访问的节点放入尾部.entrySet() keySet() values()也是一样.
下面entrySet的foreach方法
1 | public final void forEach(Consumer<? super Map.Entry<K,V>> action) { |
HashTable
因为HashTable很少用,这里做个简单讲解,
它是1.0出来的,HashMap是1.2出来的,就是因为它效率低.
如果真想用线程安全的,使用ConcurrentHashMap效果更好.
为什么很少用,查看下面继承,实现关系中Dictionary的注释
extends,implements关系
1 | public class Hashtable<K,V> |
可以看出连父类的源码都清除的写出了,类已经过时了.
构造方法
Hashtable()
1 | public Hashtable() { |
我们可以看出,默认容量是11,负载因子是0.75
Hashtable(int initialCapacity)
1 | public Hashtable(int initialCapacity) { |
Hashtable(int initialCapacity, float loadFactor)
1 | public Hashtable(int initialCapacity, float loadFactor) { |
这里可以看出初始化了负载因子,表和阈值.阈值=容量*负载因子,默认阈值就是11*0.75=8.25,也就是8.
Hashtable(Map<? extends K, ? extends V> t)
1 | public Hashtable(Map<? extends K, ? extends V> t) { |
调用构造函数进行初始化,再进putAll方法,把所有数据重新插入.
1 | public synchronized void putAll(Map<? extends K, ? extends V> t) { |
通过t.entrySet()先获取原Map的所有节点,再依次进行插入,可以看出此方法也是同步方法.
其中的put方法我们继续往下看 ->
put添加
1 | public synchronized V put(K key, V value) { |
可以看出,HashTable是不可以插入null的值的,
再把key的hashcode与数组长度进行取余,注意的是这里的长度可不是2的平方数,
取余之后,进行定位,
1.定位有数据,就一直往下找,找定位头节点的next执行,直到找到相同的key,替换并返回旧值.
2.如果定位无数据,直接进入addEntry方法,并返回null.(可以猜出addEntry方法就是扩容和插入的方法)
addEntry链表头插入
1 | private void addEntry(int hash, K key, V value, int index) { |
如果大于等于阈值,就进行扩容,进行rehash方法,在下面讲到.
rehash之后,对table数组重新赋值,重新定位.
获取新定位的数据,这里进行的是单向链表头插入,
rehash扩容
1 | protected void rehash() { |
注意这里扩容是新容量 = 原容量*2 + 1 ;,新的容量最大只能为MAX_ARRAY_SIZE=Integer.MAX_VALUE - 8;
把数据重新定位到新的数组中去.(在重新定位的时候,要注意是这里是头插入).
获取数据
获取数据是怎样的呢?
1 | public synchronized V get(Object key) { |
看得出来,和HashMap是方法差不多的,只不过方法都加了synchronized同步.
特点总结
- 所有的方法都是synchronized同步的
- 初始化容量是11,容量不是2的平方数
- 扩容为
新容量 = 原容量*2 + 1 ;,容量最大为Integer.MAX_VALUE - 8 - 插入是不能插入key或value为null的值
- 插入是头插入,没有红黑树,只有
数组+单向链表 - 循环也是从下标0开始循环,如果是链表,就循环链表,直到循环到最后
TreeMap
看之前做好心理准备,内容较多,并且需要你有HashMap和红黑树作为基础.
这个是基于红黑树实现NavigableMap接口的Map,所以查看此篇文章之前应该先对红黑树有个认识.
对于红黑树的简单理解可以查看红黑树
这个不细讲,主要理解有哪些不同点.
extends,implements关系
1 | public class TreeMap<K,V> |
由继承和实现关系就可以看出,它可以指定排序的方式.
属性
1 | // 标记颜色 |
构造方法
TreeMap()
1 | public TreeMap() { |
comparator = null;,默认按照key的自然顺序进行排序
TreeMap(Comparator<? super K> comparator)
1 | public TreeMap(Comparator<? super K> comparator) { |
指定比较器,也就是相当于指定了排序方式.
TreeMap(Map<? extends K, ? extends V> m)
1 | public TreeMap(Map<? extends K, ? extends V> m) { |
把普通的Map数据转换为红黑树结构的TreeMap
TreeMap(SortedMap<K, ? extends V> m)
1 | public TreeMap(SortedMap<K, ? extends V> m) { |
把排序的SortMap数据转换为红黑树的TreeMap,并把比较器设置为SortedMap的比较器.
内部类Entry
1 | static final class Entry<K,V> implements Map.Entry<K,V> { |
可以看出,内部有左右父指针,保存了k,v的值.其颜色默认为黑色.
在设置值setValue时,设置新值,返回旧值.
增
在讲添加方法之前,要讲到比较器,因为由比较器来实现红黑树的,
比较器是比较插入数据的key与根节点的key值,哪个大,哪个小,
<0左插入>0右插入=0直接插入(返回旧值)
put(K key, V value)
1 | public V put(K key, V value) { |
compare(Object k1, Object k2)
1 | final int compare(Object k1, Object k2) { |
compareTo(String anotherString)
1 | // Math类中的方法,取最小int值 |
都在注释上了,如果看不懂,就打断点,走两次这个方法就知道了.
char对应的int值,参考下图.
ASCII码表_char对应int值
fixAfterInsertion(Entry<K,V> x)
调整位置,查看红黑树
1 | private void fixAfterInsertion(Entry<K,V> x) { |
设置颜色,获取左右父节点
1 | // 给节点设置颜色 |
左旋
查看红黑树
1 | private void rotateLeft(Entry<K,V> p) { |
右旋
查看红黑树
1 | private void rotateRight(Entry<K,V> p) { |
其内容参考红黑树原理 ,
这个调整的方法我看了一下,和我理解的红黑树是完全一样的,和讲解中的也是一样的,
如果想搞懂其为什么,可以查看上面红黑树原理文章.对比着目录旋转和颜色变换规则来查看此方法.
查
get(Object key)
1 | public V get(Object key) { |
getEntry(Object key)
1 | // 获取节点数据,和执行put方法插入时候差不多, |
getFirstEntry()
获取key值最小的节点
1 | final Entry<K,V> getFirstEntry() { |
getLastEntry()
获取key值最大的节点
1 | final Entry<K,V> getLastEntry() { |
predecessor(Entry<K,V> t)
如果使比较器按照key的值,从小到大排序.
那么这个方法就是获取指定节点的前一个节点,
如果是头节点(key最小),则返回null.
如果看了之后,可以对比着这张图来看.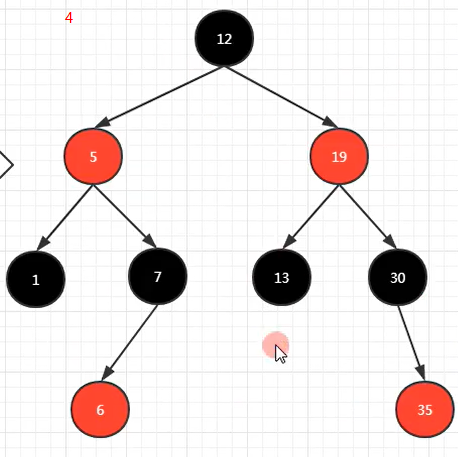
1 | static <K,V> Entry<K,V> predecessor(Entry<K,V> t) { |
successor(Entry<K,V> t)
道理同上,获取后一个节点,如果是尾节点(key最大),返回null.
1 | static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) { |
getLowerEntry(K key)
同predecessor方法,不同的是,它是根据key来查找到比key的值前面的那个节点.
如果你不能正确理解,可以尝试对比下面这张图:if(key=19) -> return 13那个节点.if(key=35) -> return 30那个节点.if(key=12,根节点) -> return 7那个节点.if(key=1) -> return null.
1 | final Entry<K,V> getLowerEntry(K key) { |
getHigherEntry(K key)
道理同上.它是根据key来查找到比key的值后面的那个节点.
1 | final Entry<K,V> getHigherEntry(K key) { |
getFloorEntry(K key)
获取与指定key对应的节点,
如果没有这样的节点存在,返回小于指定key的最大key的节点,
若最小key还大于指定的key,就返回null(也就是找不到比指定key更小的节点了)
对比下图,if(key=13) -> return 13那个节点.if(key=15) -> return 13那个节点.if(key=8) -> return 7那个节点.if(key=50) -> return 35那个节点.if(key=0) -> return null.
1 | final Entry<K,V> getFloorEntry(K key) { |
getCeilingEntry(K key)
获取与指定key对应的节点,
如果没有这样的节点存在,返回大于指定key的最小key的节点,
若最大key还小于指定的key,就返回null(也就是找不到比指定key更大的节点了)
对比下图,if(key=13) -> return 13那个节点.if(key=15) -> return 19那个节点.if(key=8) -> return 12那个节点.if(key=50) -> return null.if(key=0) -> return 1那个节点.
1 | final Entry<K,V> getCeilingEntry(K key) { |
删
clear()
清空数据
1 | public void clear() { |
remove(Object key)
1 | public V remove(Object key) { |
deleteEntry(Entry<K,V> p)
1 | // 下面是主要讲思路,不讲解`fixAfterDeletion`方法调整位置. |
pollFirstEntry()
找到key值最小的节点,并删除.
返回删除的节点数据,节点中只包含key,value.没有其他属性.
1 | public Map.Entry<K,V> pollFirstEntry() { |
pollLastEntry()
同上,不同的是删除最后一个.
1 | public Map.Entry<K,V> pollLastEntry() { |
改
replace(K key, V value)
根据key找到节点,替换值,返回旧值.
找不到节点返回null.
1 | public V replace(K key, V value) { |
replace(K key, V oldValue, V newValue)
同上,不同的是匹配key的同时,value也要匹配.
修改成功返回true,否则false.
1 | public boolean replace(K key, V oldValue, V newValue) { |
循环
entrySet()
看这个之前,你最好能够理解HashMap的entrySet与keySet区别?源码分析
这里主要讲一下不同点.
1 | // TreeMap的全局变量,其中EntrySet是TreeMap内部类 |
内部类EntrySet
1 | class EntrySet extends AbstractSet<Map.Entry<K,V>> { |
内部类EntryIterator
1 | final class EntryIterator extends PrivateEntryIterator<Map.Entry<K,V>> { |
内部类PrivateEntryIterator
1 | abstract class PrivateEntryIterator<T> implements Iterator<T> { |
可以看出,它的循环也是同key值的顺序排列的,默认是从小到大的顺序排列,先访问到最小key的节点.
所以它不同于HashMap,它遍历是有序的,HashMap是无需的.
keySet()
这个稍微有点不同,它可以根据比较器排序后的Map遍历.
1 | public Set<K> keySet() { return navigableKeySet(); } |
navigableKeySet()
1 | private transient KeySet<K> navigableKeySet; |
内部类KeySet
1 | static final class KeySet<E> extends AbstractSet<E> implements NavigableSet<E> { |
keyIterator()
1 | Iterator<K> keyIterator() { |
内部类KeyIterator
1 | final class KeyIterator extends PrivateEntryIterator<K> { |
values()
1 | public V next() { return nextEntry().value; } |
同上,只不过next()是获取下一个节点的value属性.
HashSet
经过上面的分析,我们终于可以分析Set类型的集合了,
其实我们在分析HashMap的时候,就知道的差不多了,我们再次重新认识一下它.
extends,implements关系
1 | public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable{ |
我们可以看到 HashSet是实现Set接口的,这个毋庸置疑.
而Set接口是继承Collection(集合)接口的.
Collection继承Iterable接口,才可以使迭代成为可能.
基本属性
1 | private transient HashMap<E,Object> map; |
可以看出,它实质上就是保存在HashMap中的key值,
还有一个不可改变的Object对象.
add(E e)
1 | public boolean add(E e) { |
可以看出,HashSet插入往HashMap中插入数据的,只不过插入的value是不可变的成员变量PRESENT.
添加的key不存在返回true,存在返回false.
iterator()
1 | public Iterator<E> iterator() { |
size()
1 | public int size() { |
contains(Object o)
1 | public boolean contains(Object o) { |
remove(Object o)
1 | public boolean remove(Object o) { |
LinkedHashSet
通过了HashSet的讲解,看得出来了解Set的本质,就是需要了解Map.
LinkedHashSet也不例外,下面我们来看一下.
extends,implements关系
1 | public class LinkedHashSet<E> |
看得出来,它正如LinkedHashMap继承HashMap一样,
不同点
1 | /* 父类HashSet的方法 */ |
1 | public LinkedHashSet() { |
看得出来,其本质就是LinkedHashMap,这里就不做过多阐述.
默认容量和负载因子与HashMap一样,分别是16 0.75f
TreeSet
通过我们对HashSet与LinkedHashSet的了解,我们知道了其本质就是HashMap与LinkedHashMap的key.
extends,implements关系
1 | public class TreeSet<E> extends AbstractSet<E> |
属性
1 | private transient NavigableMap<E,Object> m; |
其原理同HashSet,下面写出add添加代码,不做过多阐述.
add(E e)
1 | public boolean add(E e) { |