关于浏览过的文章
https://github.com/CL0610/Java-concurrency
http://www.dengshenyu.com/后端技术/2016/05/01/jmm-happens-before.html
https://www.jianshu.com/p/1508eedba54d
https://www.cnblogs.com/chenssy/p/6393321.html
https://www.jianshu.com/p/4853ad07e1ff
https://blog.csdn.net/yanluandai1985/article/details/82686486
https://www.cnblogs.com/zhangjk1993/archive/2017/03/29/6641745.html
https://blog.csdn.net/noodleprince/article/details/79711307
https://blog.csdn.net/javazejian/article/details/77410889
https://blog.csdn.net/luluyo/article/details/92403054
https://blog.csdn.net/hanchao5272/article/details/79779639
https://www.jianshu.com/p/19be99a6480a
关于synchronized具备原子性的问题
synchronized是”万能”的,为什么还需要volatile呢?
Java并发编程:Semaphore、CountDownLatch、CyclicBarrier
并发编程的优缺点
为什么要用到并发
一直以来,硬件的发展极其迅速,也有一个很著名的摩尔定律
因此,多核的CPU的背景下,催生了并发编程的趋势,通过并发编程的形式可以将多核CPU的计算能力发挥到极致,性能得到提升。
另外,在特殊的业务场景下先天的就适合于并发编程。
比如在图像处理领域,一张1024X768像素的图片,包含达到78万6千多个像素。即时将所有的像素遍历一边都需要很长的时间,面对如此复杂的计算量就需要充分利用多核的计算的能力。
又比如当我们在网上购物时,为了提升响应速度,需要拆分,减库存,生成订单等等这些操作,就可以进行拆分利用多线程的技术完成。
面对复杂业务模型,并行程序会比串行程序更适应业务需求,而并发编程更能吻合这种业务拆分 。
- 充分利用多核CPU的计算能力;
- 方便进行业务拆分,提升应用性能
并发编程有哪些缺点
多线程技术有这么多的好处,难道就没有一点缺点么,就在任何场景下就一定适用么?很显然不是。
频繁的上下文切换
时间片是CPU分配给各个线程的时间,因为时间非常短,所以CPU不断通过切换线程,让我们觉得多个线程是同时执行的,时间片一般是几十毫秒。
而每次切换时,需要保存当前的状态起来,以便能够进行恢复先前状态,而这个切换时非常损耗性能,过于频繁反而无法发挥出多线程编程的优势。
通常减少上下文切换可以采用无锁并发编程,CAS算法,使用最少的线程和使用协程。
无锁并发编程可以参照concurrentHashMap锁分段的思想,不同的线程处理不同段的数据,这样在多线程竞争的条件下,可以减少上下文切换的时间。CAS算法利用Atomic下使用CAS算法来更新数据,使用了乐观锁,可以有效的减少一部分不必要的锁竞争带来的上下文切换使用最少线程避免创建不需要的线程,比如任务很少,但是创建了很多的线程,这样会造成大量的线程都处于等待状态协程在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换
由于上下文切换也是个相对比较耗时的操作,所以在”java并发编程的艺术”一书中有过一个实验,并发累加未必会比串行累加速度要快。
可以使用Lmbench3测量上下文切换的时长 vmstat测量上下文切换次数
线程安全-死锁
多线程编程中最难以把握的就是临界区线程安全问题,稍微不注意就会出现死锁的情况,一旦产生死锁就会造成系统功能不可用。
代码示例
1 | public class DeadLockDemo { |
在上面的这个demo中,开启了两个线程threadA, threadB,其中threadA占用了resource_a, 并等待被threadB释放的resource_b。threadB占用了resource_b正在等待被threadA释放的resource_a。因此threadA,threadB出现线程安全的问题,形成死锁。
如上所述,完全可以看出当前死锁的情况。
避免死锁的情况
- 避免一个线程同时获得多个锁;
- 避免一个线程在锁内部占有多个资源,尽量保证每个锁只占用一个资源;
- 尝试使用定时锁,使用lock.tryLock(timeOut),当超时等待时当前线程不会阻塞;
- 对于数据库锁,加锁和解锁必须在一个数据库连接里,否则会出现解锁失败的情况
所以,如何正确的使用多线程编程技术有很大的学问,比如如何保证线程安全,如何正确理解由于JMM内存模型在原子性,有序性,可见性带来的问题,比如数据脏读,DCL(双重检验锁)等这些问题(在后续篇幅会讲述)。而在学习多线程编程技术的过程中也会让你收获颇丰。
应该了解的概念
同步VS异步
同步和异步通常用来形容一次方法调用。
同步方法调用一开始,调用者必须等待被调用的方法结束后,调用者后面的代码才能执行。异步用,指的是,调用者不用管被调用方法是否完成,都会继续执行后面的代码,当被调用的方法完成后会通知调用者。
例如同步调用在超时购物,如果一件物品没了,你得等仓库人员跟你调货,直到仓库人员跟你把货物送过来,你才能继续去收银台付款异步调用就像网购,你在网上付款下单后,什么事就不用管了,该干嘛就干嘛去了,当货物到达后你收到通知去取就好。
并发与并行
并发和并行是十分容易混淆的概念。
并发指的是多个任务交替进行并行是指真正意义上的“同时进行”。
实际上,如果系统内只有一个CPU,而使用多线程时,那么真实系统环境下不能并行,只能通过切换时间片的方式交替进行,而成为并发执行任务。
真正的并行也只能出现在拥有多个CPU的系统中。
阻塞和非阻塞
阻塞和非阻塞通常用来形容多线程间的相互影响
阻塞一个线程占有了临界区资源,那么其他线程需要这个资源就必须进行等待该资源的释放,会导致等待的线程挂起非阻塞它强调没有一个线程可以阻塞其他线程,所有的线程都会尝试地往前运行。
临界区
表示一种公共资源或者说是共享数据,可以被多个线程使用。
但是每个线程使用时,一旦临界区资源被一个线程占有,那么其他线程必须等待。
线程的状态&操作
线程创建
一个java程序从main()方法开始执行,然后按照既定的代码逻辑执行,看似没有其他线程参与,但实际上java程序天生就是一个多线程程序,包含了
- 分发处理发送给给JVM信号的线程
- 调用对象的finalize方法的线程
- 清除Reference的线程
- main线程,用户程序的入口
那么,如何在用户程序中新建一个线程了,只要有三种方式:
- 通过继承Thread类,重写run方法
- 通过实现runable接口
- 通过实现callable接口这三种方式
- 代码示例三种新建线程的方式具体看以上注释,需要主要的是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53package thread;
import java.util.concurrent.*;
public class test001
{
public static void main(String[] args)
{
//1.继承Thread
Thread thread = new Thread(){
public void run()
{
super.run();
System.out.println("继承Thread");
}
};
thread.start();
//2.实现runable接口
Thread thread1 = new Thread(new Runnable() {
public void run() {
System.out.println("实现runable接口");
}
});
thread1.start();
//3.实现callable接口
ExecutorService executorService= Executors.newSingleThreadExecutor();
Future<String> future=executorService.submit(new Callable<String>()
{
public String call() throws Exception
{
return "通过实现Callable接口";
}
});
try
{
String result=future.get();
System.out.println(result);
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
}
}
} - 由于java不能多继承可以实现多个接口,因此,在创建线程的时候尽量多考虑采用实现接口的形式;
- 实现callable接口,提交给ExecutorService返回的是异步执行的结果,
通常也可以利用FutureTask(Callable callable)将callable进行包装
然后FeatureTask提交给ExecutorsService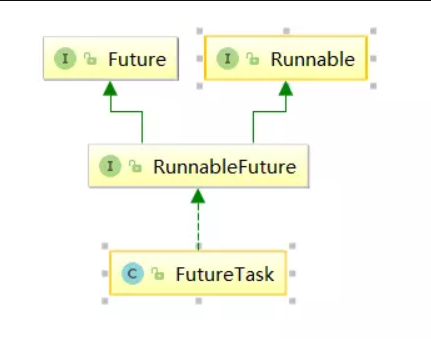
另外由于FeatureTask也实现了Runable接口也可以利用上面第二种方式(实现Runable接口)来新建线程;
- 可以通过Executors将Runable转换成Callable,具体方法是:Callable callable(Runnable task, T result), Callable callable(Runnable task)。
1
2
3
4
5
6
7
8
9
10
11
12// 简单创建
FutureTask<String> futureTask=new FutureTask<>(new Callable<String>()
{
public String call() throws Exception
{
System.out.println("FutureTask");
return null;
}
});
Thread thread2=new Thread(futureTask);
thread2.start();
线程生命周期
1 | + 新建(new Thread) |
线程状态
线程的状态,Thread类中枚举类State中的定义
NEW尚未启动的线程所处的状态。
例如:线程对象已经创建了,但还没有调用start()方法RUNNABLE在Java虚拟机中执行的线程所处的状态。
当线程有资格运行,但调度程序还没有把它选定为运行线程时线程所处的状态。
当start()方法调用时,线程首先进入可运行状态,随时可能被CPU调度执行。BLOCKED在等待监视器锁时被阻塞的线程所处的状态。
处于阻塞状态的线程正在等待其他线程释放监视器锁,不能进入同步块/方法WAITING无限期等待另一个线程执行特定操作的线程所处的状态。
例如,对一个对象调用Object.wait()的线程正在等待,另一个线程对该对象调用Object.notify()或Object.notifyAll可以使其唤醒为RUNNABLE状态.
调用了Thread.join()的线程正在等待指定的线程终止,所处的状态。
一个线程由于调用下列方法之一而处于等待状态:- Object.wait()
- Thread.join()
- LockSupport.park()
TIMED_WAITING在指定等待时间内等待另一个线程执行某个操作的线程所处的状态。
线程处于定时等待状态- Thread.sleep(long)
- Object.wait(long)
- Thread.join(long)
- LockSupport.parkNanos(long)
- LockSupport.parkUntil(long)
TERMINATED退出的线程所处的状态。
线程执行完了或因异常退出了run()方法。
关于调度问题:
RUNNABLE随时可能被CPU调度执行;
运行状态是获取CPU权限正在进行执行;
BLOCKED,WAITING,TIMED_WAITING状态是线程因为某种原因放弃CPU使用权,暂时停止运行.直到线程进入RUNNABLE状态,才有机会转到运行状态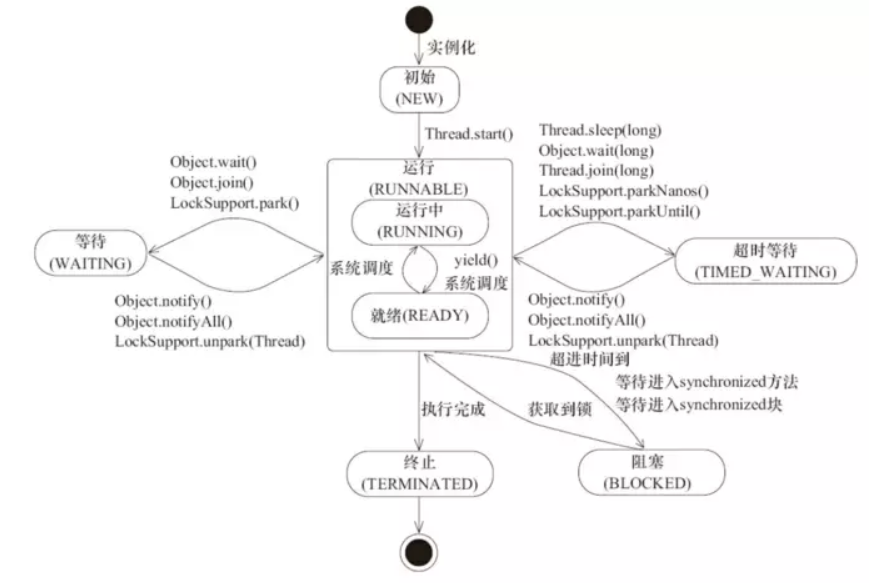
- 线程创建之后调用start()方法开始运行
- 调用wait(),join(),LockSupport.lock()进入
等待状态 - 调用wait(long timeout),sleep(long),join(long),LockSupport.parkNanos(),LockSupport.parkUtil()进入
超时等待状态 - 当
超时等待状态时间到达后,线程会切换到运行状态 - 另外
等待状态和超时等待状态时可以通过Object.notify(),Object.notifyAll()方法使线程转换到运行状态 - 当线程出现资源竞争时,即等待获取锁的时候,线程会进入到
阻塞状态 - 当线程获取锁时,线程进入到
运行状态 - 线程运行结束后,线程进入到
终止状态 - 状态转换可以说是线程的生命周期
- 另外需要注意的是
- 当线程进入到synchronized方法或者synchronized代码块时,线程切换到的是
阻塞状态 - 而使用java.util.concurrent.locks下lock进行加锁的时候线程切换的是
等待或者超时等待状态,因为lock会调用LockSupport的方法。
- 当线程进入到synchronized方法或者synchronized代码块时,线程切换到的是
用一个表格将上面六种状态进行一个总结归纳。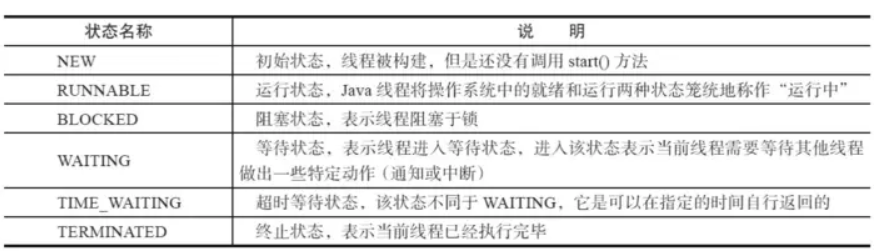
run()和start()
start会开启一个新线程,run不会对象.start();会先执行后面的内容,再执行对象中的run方法对象.run();会先执行对象中的run方法,再执行后面的内容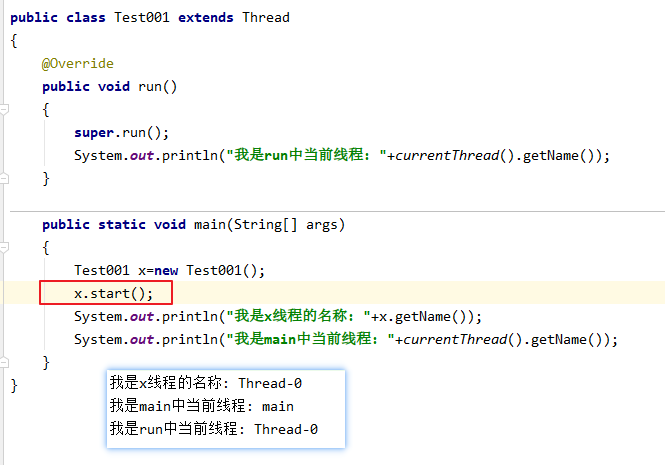
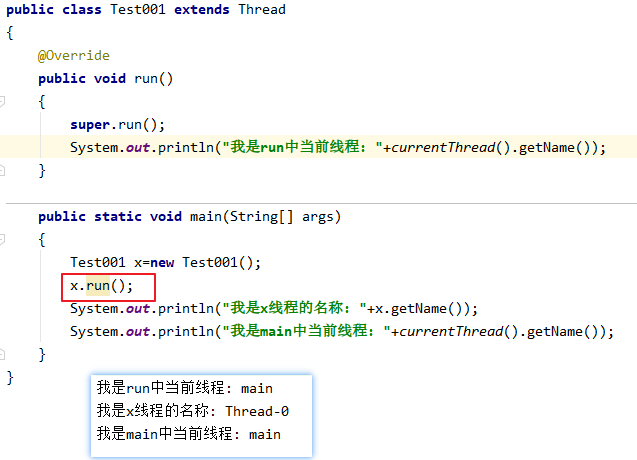
总结
start是开启一个新的线程,在新线程中执行
run是在主线程中执行该方法,和调普通方法一样
线程状态操作
除了新建一个线程外,线程在生命周期内还有需要基本操作,而这些操作会成为线程间一种通信方式
例如使用中断(interrupted)方式通知实现线程间的交互等等,下面就将具体说说这些操作。
interrupted
1 | // 2022-02-25 20:15:22 再理解 |
1 | 2020-07-06 14:37:25再理解 |
中断可以理解为线程的一个中断状态,它表示了一个运行中的线程是否被其他线程进行了中断操作。
中断好比其他线程对该线程打了一个招呼。
其他线程可以调用该线程的interrupt()方法对其进行中断操作,同时该线程可以调用 isInterrupted()来感知其他线程对其自身的中断操作,从而做出响应。
另外,同样可以调用Thread的静态方法 interrupted()对当前线程进行中断操作,该方法会清除中断状态。
需要注意的是,当抛出InterruptedException时候,会清除中断状态,也就是说在调用isInterrupted会返回false。
Object.interrupt()方法
- 源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44/**
* 中断这个线程。
*
* 除非当前线程本身正在中断, 这是允许的,
* 调用该线程的`checkAccess`方法, 这可能导致抛出`SecurityException`异常.
*
* 除非当前线程本身正在中断,否则调用`checkAccess()`方法将抛出`SecurityException`异常.
*
* 如果这个线程已经调用了这个方法,再调用
* `wait()/wait(long)/wait(long, int)`
* `join()/join(long)/join(long, int)`
* `sleep(long)/sleep(long, int)`
* 会清除中断状态,并抛出`InterruptedException`异常
*
* 如果线程在`java.nio.channels.InterruptibleChannel`的I/O操作中被阻塞,
* 这个线程将设置中断状态,并抛出`java.nio.channels.ClosedByInterruptException`异常
*
* 如果这个线程在`java.nio.channels.Selector`中被阻塞,那么这个线程将被设置中断状态,
* 并且它将立即从选择操作返回,可能带有一个非零值,就像调用了选择器(java.nio.channels.Selector)的`wakeup`方法一样。
*
* 如果前面的条件都不成立,那么这个线程的中断状态将被设置。
*
* 中断非活动的线程不一定会有任何影响。
*
* @throws SecurityException
* 如果当前线程不能修改此线程
*
* @revised 6.0
* @spec JSR-51
*/
public void interrupt() {
if (this != Thread.currentThread())
checkAccess();
synchronized (blockerLock) {
Interruptible b = blocker;
if (b != null) {
interrupt0(); // Just to set the interrupt flag
b.interrupt(this);
return;
}
}
interrupt0();
} - 示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
Thread thread = new Thread(() ->
{
try {
System.out.println(1);
if (!Thread.currentThread().isInterrupted())
System.out.println(2);
Thread.sleep(3 * 1000);
} catch (InterruptedException e) {
System.out.println("异常1...");
if (!Thread.currentThread().isInterrupted())
System.out.println(2222);
System.out.println(3);
System.out.println(sdf.format(new Date()));
}
});
System.out.println(sdf.format(new Date()));
thread.start();
try {
System.out.println(4);
Thread.sleep(1000);
System.out.println(5);
} catch (InterruptedException e) {
System.out.println("异常2...");
}
System.out.println(6);
thread.interrupt();
System.out.println(7); - 执行结果
1
2
3
4
5
6
7
8
9
10
112019-11-21 16:18:24 759
4
1
2
5
6
7
异常1...
2222
3
2019-11-21 16:18:25 818 - 分析
开启thread线程,打印4,主线休眠1s,让其他线程执行,这里执行thread线程,打印1,默认中断状态为false,所以打印2,
1秒之后,主线程恢复,打印5,没有异常,再往下走,打印6,把thread线程的中断状态改为true,表示中断,
这时只是进行了设置,此时CPU还在执行主线程,打印7,这时再把CPU给到thread线程,
这时在执行sleep方法,所以会立即异常,并清除中断状态,也就是再设置为false,所以还是会打印2222,再打印3,执行完毕…
整个过程1秒多点儿
Object.isInterrupted()方法
- 源码
1
2
3public boolean isInterrupted() {// false表示`不清除中断状态`
return isInterrupted(false);
}
无论调用多少次都返回true(因为无论调用多少次都不会清除中断状态)
1 | Thread.currentThread().interrupt(); |
Thread.interrupted()方法
- 源码
1
2
3public static boolean interrupted() {// true表示`清除中断状态`
return currentThread().isInterrupted(true);
}
第一次调用返回true,再次调用返回false(因为在第一次调用的时候就已经清除了中断状态)
1 | Thread.currentThread().interrupt(); |
深度理解Object.interrupt()方法
- 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47public class ThreadInterrupt {
public static void main(String[] args) {
final SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Thread thread0 = new Thread(new Runnable() {
public void run() {
while (!Thread.currentThread().isInterrupted()) {
try {
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 1");
Thread.sleep(10 * 1000);
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 2");
} catch (InterruptedException e) {
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 3");
}
}
}
});
Thread thread1 = new Thread(new Runnable() {
public void run() {
while (!Thread.currentThread().isInterrupted()) {
try {
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 4");
Thread.sleep(10 * 1000);
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 5");
} catch (InterruptedException e) {
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 6");
Thread.currentThread().interrupt();
}
}
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 7");
}
});
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 8");
thread0.start();
thread1.start();
try {
Thread.sleep(2000);
System.out.println(format.format(new Date()) + " " + Thread.currentThread().getName() + " 9");
thread0.interrupt();
thread1.interrupt();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} - 执行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
162019-11-21 16:34:34 main 8
2019-11-21 16:34:34 Thread-0 1
2019-11-21 16:34:34 Thread-1 4
2019-11-21 16:34:36 main 9
2019-11-21 16:34:36 Thread-1 6
2019-11-21 16:34:36 Thread-0 3
2019-11-21 16:34:36 Thread-1 7
2019-11-21 16:34:36 Thread-0 1
2019-11-21 16:34:46 Thread-0 2
2019-11-21 16:34:46 Thread-0 1
2019-11-21 16:34:56 Thread-0 2
2019-11-21 16:34:56 Thread-0 1
...
会一直循环10秒一次2 1 - 分析
先打印9,再开启两个线程,再让当前线程(main)休眠2s,也就是至少2s之内不可运行,让其他线程获得运行的机会(这里指thread0和thread1两个线程获得运行的机会),
这里执行thread0和执行thread1可以重排序,这里是先执行了thread0线程,打印1,然后睡眠10s,这时再把CPU给其他线程,这时只能执行thread1,打印4,thread1再睡眠10秒,
这时三个都在睡眠,main线程先醒来,就他自己,所以main线程无需竞争,直接获得运行资格继续往下执行,打印9,这时把thread0与thread1设置了中断状态为true,这时主线程也执行完毕了,
又因为他们两个线程都在sleep睡眠,所以,都出现异常,这里thread0的打印3打印1不能重排序,thread1的打印6当前线程(thread1)设置中断状态为true(也就是跳出了thread1的循环)打印7不能重排序,
但是他们两个线程没有先后关系,可以对这两个线程同时进行,交替执行命令,这里打印6,3,7,1 在6与7直接还进行了当前线程(thread1)设置中断状态为true(也就是跳出了thread1的循环),
这时候只有thread0还在循环执行,每过10s就会打印2,1
测试代码
Object.isInterrupted();//Boolean1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public static void main(String[] args)
{
Thread t = Thread.currentThread();
System.out.println("1: " + t.isInterrupted());
t.interrupt();
System.out.println("2: " + t.isInterrupted());
System.out.println("3: " + t.isInterrupted());
try {
Thread.sleep(2000);
System.out.println("not interrted...");
} catch (InterruptedException e) {
System.out.println("interrupted...");
System.out.println("4: " + t.isInterrupted());
}
System.out.println("5: " + t.isInterrupted());
}
//输出结果
// 1: false
// 2: true
// 3: true
// interrupted...
// 4: false
// 5: false实例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public class InterruptDemo {
public static void main(String[] args) throws InterruptedException {
//sleepThread睡眠1000ms
final Thread sleepThread = new Thread() {
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println("sleepThread抛出异常...");
}
super.run();
}
};
//busyThread一直执行死循环
Thread busyThread = new Thread() {
public void run() {
while (true) ;
}
};
sleepThread.start();
busyThread.start();
sleepThread.interrupt();
busyThread.interrupt();
while (sleepThread.isInterrupted()) ;
System.out.println("sleepThread isInterrupted: " + sleepThread.isInterrupted());
System.out.println("busyThread isInterrupted: " + busyThread.isInterrupted());
}
}输出结果
1
2
3sleepThread isInterrupted: false
busyThread isInterrupted: true
sleepThread抛出异常...
开启了两个线程分别为sleepThread和BusyThread, sleepThread睡眠1s,BusyThread执行死循环。
然后分别对着两个线程进行中断操作,可以看出sleepThread抛出InterruptedException后清除中断状态,而busyThread就不会清除中断状态。
另外,同样可以通过中断的方式实现线程间的简单交互, while (sleepThread.isInterrupted()) 表示在Main中会持续监测sleepThread,一旦sleepThread的中断状态清零,即sleepThread.isInterrupted()返回为false时才会继续Main线程才会继续往下执行。
因此,中断操作可以看做线程间一种简便的交互方式。
一般在结束线程时通过中断状态的方式可以有机会去清理资源,相对于武断而直接的结束线程,这种方式要优雅和安全。
join
- 先来示例
join方法可以看做是线程间协作的一种方式,很多时候,一个线程的输入可能非常依赖于另一个线程的输出
这就像两个好基友,一个基友先走在前面突然看见另一个基友落在后面了,这个时候他就会在原处等一等这个基友,等基友赶上来后,就两人携手并进。
其实线程间的这种协作方式也符合现实生活。在软件开发的过程中,从客户那里获取需求后,需要经过需求分析师进行需求分解后,这个时候产品,开发才会继续跟进。
Object.join()与Object.join(long millis)源码
- Object.join()
1
2
3
4
5
6
7
8
9
10
11/**
* 等待线程死亡。
*
* 此方法的调用与调用`join(0)`完全相同
*
* @throws InterruptedException
* 如果任何线程中断了当前线程。当抛出此异常时,当前线程的“interrupted status中断状态”将被清除。
*/
public final void join() throws InterruptedException {
join(0);
} - Object.join(long millis)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41/**
* 等待这个线程死亡的时间最多为 millis 毫秒。如果millis=0表示永远等待
*
* 这个实现以`this.isAlive`作为一个条件,循环调用`this.wait`
* 调用`this.notifyAll`使线程终止
* 建议不要在`Thread`实例的应用程序上使用`wait` `notify` `notifyAll`
*
* @param millis
* 等待的时间以毫秒为单位
*
* @throws IllegalArgumentException
* 如果 millis 的值是负数
*
* @throws InterruptedException
* 如果任何线程中断了当前线程。
* 当抛出此异常时,当前线程的“interrupted status中断状态”将被清除。
*/
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
join可以控制线程执行顺序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25//Thread的join的使用
public static void main(String[] args) throws Exception
{
Thread threadA=new Thread(()->{
for (int i = 0; i < 10; i++)
{
System.out.println(Thread.currentThread().getName()+i);
}
},"A");
threadA.start();
/*
加了这一行,当前main线程就会把CPU执行权交给A线程,
只有A线程执行完毕才会把CPU执行权交给main线程,继续往下执行
threadA.join();如果不加这行代码,他们就会随机执行。
*/
threadA.join();
Thread threadB=new Thread(()->{
for (int i = 0; i < 10; i++)
{
System.out.println(Thread.currentThread().getName()+i);
}
},"B");
threadB.start();
}简单示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public static void main(String[] args)
{
Thread t1 = new Thread(() -> System.out.println("t1"));
Thread t2 = new Thread(() ->
{
try
{
// 引用t1线程,等待t1线程执行完
t1.join();
} catch (InterruptedException e)
{
e.printStackTrace();
}
System.out.println("t2");
});
Thread t3 = new Thread(() ->
{
try
{
// 引用t2线程,等待t2线程执行完
t2.join();
} catch (InterruptedException e)
{
e.printStackTrace();
}
System.out.println("t3");
});
//这里三个线程的启动顺序可以任意,大家可以试下!
t3.start();
t2.start();
t1.start();
}
// 执行结果
t1
t2
t3
【一个线程实例A的RUN中执行了threadB.join(),其含义是:当前线程A会等待threadB线程终止后threadA才会继续执行。】
1 | public static void main(String[] args) |
- 输出结果
1
2
3
4
5
6
7
8111
222
333
444
555
我是thread1.run
666
777
关于join方法一共提供如下这些方法:
public final void join() throws InterruptedException {join(0);}public final synchronized void join(long millis) throws InterruptedException{...}public final synchronized void join(long millis, int nanos) throws InterruptedException{...}
Thread类除了提供join()方法外,另外还提供了超时等待的方法。
如果线程threadB在等待的时间内还没有结束的话,threadA会在超时之下一个续执行。
join方法源码关键是:
1 | ... |
可以看出来当前等待对象threadA会一直阻塞,直到被等待对象threadB结束后即isAlive()返回false的时候才会结束while循环,当threadB退出时会调用notifyAll()方法通知所有的等待线程。
- 下面用一个具体的例子来说说join方法的使用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class JoinDemo {
public static void main(String[] args) {
Thread previousThread = Thread.currentThread();
for (int i = 1; i <= 10; i++) {
Thread curThread = new JoinThread(previousThread);
curThread.start();
previousThread = curThread;
}
}
static class JoinThread extends Thread {
private Thread thread;
public JoinThread(Thread thread) {
this.thread = thread;
}
public void run() {
try {
thread.join();
System.out.println(thread.getName() + " terminated.");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
} - 执行结果在上面的例子中一个创建了10个线程,每个线程都会等待前一个线程结束才会继续运行。
1
2
3
4
5
6
7
8
9
10main terminated.
Thread-0 terminated.
Thread-1 terminated.
Thread-2 terminated.
Thread-3 terminated.
Thread-4 terminated.
Thread-5 terminated.
Thread-6 terminated.
Thread-7 terminated.
Thread-8 terminated.
可以通俗的理解成接力,前一个线程将接力棒传给下一个线程,然后又传给下一个线程……
sleep
public static native void sleep(long millis)方法显然是Thread的静态方法,很显然它是让当前线程按照指定的时间休眠
需要注意的是如果当前线程获得了锁,sleep方法并不会失去锁。
sleep是当前线程休眠,Thread中的静态方法,
Thread.sleep(毫秒数)即让当前运行的线程进入TIMED_WAITING(超时等待)状态,调用完成,当前线程进入休眠状态,直到休眠设置的毫秒数后由系统唤醒。
需要注意的是线程与同步锁没有关系,所以不会存在等待释放同步锁这么一说,它可以随意的嵌入方法代码的任何地方进行调用
sleep()和wait()
sleep方法经常拿来与Object.wait()方法进行比价,这也是面试经常被问的地方。
方法原型分别为:
1 | public final native void wait(long timeout) throws InterruptedException; |
1 | public static native void sleep(long millis) throws InterruptedException; |
相同点
- 都是线程同步时会用到的方法,使当前线程暂停运行,把运行机会交给其它线程。
- 如果任何线程在等待期间被中断都会抛出InterruptedException
- 都是native方法
不同点
所在类不同,wait()是Object类中的实例方法;而sleep()是线程Thread类中的静态方法关键点是对锁的保持不同,wait会释放锁;而sleep()并不释放锁
(wait()方法会释放占有的对象锁,使得该线程进入等待池中,等待下一次获取资源。而sleep()方法只是会让出CPU并不会释放掉对象锁)唤醒方法不完全相同,wait依靠notify或者notifyAll、中断发生、或者到达指定时间来唤醒;而sleep()则是到达指定的时间后被唤醒。
(sleep()方法在休眠时间达到后如果再次获得CPU时间片就会继续执行,而wait()方法必须等待Object.notify/Object.notifyAll通知、中断发生、或者到达指定时间来唤醒,并且再次获得CPU时间片才会继续执行。)使用的位置不同,wait只能用在同步代码块中,而sleep用在任何位置。
(wait()方法必须要在同步方法或者同步块中调用,也就是必须已经获得对象锁,而sleep()方法没有这个限制可以在任何地方种使用。)
wait
1 | //唤醒此对象监视器等待的单个线程,被唤醒线程进入就绪状态,先进先出 |
线程的等待与唤醒为什么在Object中而不在线程Thread中,需要强调的是,这里说的线程等待是指让线程等待在某一个对象的监视器上(用Object.wait()表示)
等待时会释放持有该对象的同步锁,依赖于synchronized关键字使用(否则报监视器状态异常IllegalMonitorStateException)。
同样,线程唤醒也是指唤醒等待在某一个对象监视器上的线程(用Object.notify()表示),也依赖于synchronized关键字。
说白了,线程的等待与唤醒都是基于某一对象的监视器。
- 代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public class WaitNotify {
public static void main(String[] args) {
final SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
final Object object = new Object();
Thread thread = new Thread(new Runnable() {
public void run() {
System.out.println(sdf.format(new Date()) + " " + Thread.currentThread().getName() + " `Thread-0`线程开始运行...");
// `Thread-0`线程等待`main`线程释放`object`同步锁之前 阻塞在`object`对象的监视器(monitor)上
synchronized (object) {
System.out.println(sdf.format(new Date()) + " " + Thread.currentThread().getName() + " 唤醒`main`线程...");
//唤醒一个在`object`对象监视器上等待的线程,唤醒的顺序是FIFO,这里唤醒`main`线程
object.notify();
System.out.println(sdf.format(new Date()) + " " + Thread.currentThread().getName() + " 已唤醒`main`线程...");
}
}
});
synchronized (object) {
System.out.println(sdf.format(new Date()) + " " + Thread.currentThread().getName() + " `main`线程开始执行...");
thread.start();
try {
// `main`线程休眠2s,为了其他线程能拿到CPU,这里指`Thread-0`
Thread.sleep(2 * 1000);
System.out.println(sdf.format(new Date()) + " " + Thread.currentThread().getName() + " `main`线程wait()...");
// 让`main`线程在`object`对象同步锁上一直等待,并释放`object`同步锁
// 使用`object.notify();`可将`main`线程在同步锁对象`object`上唤醒,使`main`线程继续往下执行
object.wait();
} catch (InterruptedException e) {
}
System.out.println(sdf.format(new Date()) + " " + Thread.currentThread().getName() + " `main`线程继续运行...");
}
}
} - 执行结果看了上面的执行结果,可知
1
2
3
4
5
62019-11-21 10:42:27 932 main `main`线程开始执行...
2019-11-21 10:42:27 933 Thread-0 `Thread-0`线程开始运行...
2019-11-21 10:42:29 933 main `main`线程wait()...
2019-11-21 10:42:29 933 Thread-0 唤醒`main`线程...
2019-11-21 10:42:29 933 Thread-0 已唤醒`main`线程...
2019-11-21 10:42:29 933 main `main`线程继续运行...wait(long timeout)是等待期间如果线程未被唤醒,则等待期间后自动唤醒notify()是唤醒一个等待线程,而notifyAll()是唤醒所有等待的线程
yield
public static native void yield();这是一个静态方法,一旦执行,它会是当前线程让出CPU
但是,需要注意的是,让出的CPU并不是代表当前线程不再运行了,如果在下一次竞争中,又获得了CPU时间片当前线程依然会继续运行。
另外,让出的时间片只会分配给当前线程相同优先级的线程。
- 什么是线程优先级?
现代操作系统基本采用时分的形式调度运行的线程,操作系统会分出一个个时间片,线程会分配到若干时间片,当前时间片用完后就会发生线程调度,并等待这下次分配。
线程分配到的时间多少也就决定了线程使用处理器资源的多少,而线程优先级就是决定线程需要或多或少分配一些处理器资源的线程属性。
在Java程序中,通过一个整型成员变量Priority来控制优先级,优先级的范围从1~10
在构建线程的时候可以通过setPriority(int)方法进行设置,默认优先级为5
优先级高的线程相较于优先级低的线程优先获得处理器时间片。
sleep()和yield()
相同点都是当前线程会交出处理器资源不同点sleep()交出来的时间片其他线程都可以去竞争,也就是说都有机会获得当前线程让出的时间片。而yield()方法只允许与当前线程具有相同优先级的线程能够获得释放出来的CPU时间片。
守护线程Daemon
守护线程是一种特殊的线程,就和它的名字一样,它是系统的守护者,在后台默默地守护一些系统服务,比如垃圾回收线程,JIT线程就可以理解守护线程。
与之对应的就是用户线程,用户线程就可以认为是系统的工作线程,它会完成整个系统的业务操作。
用户线程完全结束后就意味着整个系统的业务任务全部结束了,因此系统就没有对象需要守护的了,守护线程自然而然就会退。
当一个Java应用,只有守护线程的时候,虚拟机就会自然退出。
- Daemon线程的示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class DaemonDemo {
public static void main(String[] args) {
Thread daemonThread = new Thread(new Runnable() {
public void run() {
while (true) {
try {
System.out.println("i am alive");
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("finally block");
}
}
}
});
daemonThread.setDaemon(true);
daemonThread.start();
try {
//确保main线程结束前能给daemonThread能够分到时间片
Thread.sleep(800);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} - 输出结果上面的例子中daemodThread run方法中是一个while死循环,会一直打印,但是当main线程结束后daemonThread就会退出所以不会出现死循环的情况。
1
2
3i am alive
finally block
i am alive
main线程先睡眠800ms保证daemonThread能够拥有一次时间片的机会,也就是说可以正常执行一次打印“i am alive”操作和一次finally块中”finally block”操作。
紧接着main 线程结束后,daemonThread退出,这个时候只打印了”i am alive”并没有打印finnal块中的。
因此,这里需要注意的是守护线程在退出的时候并不会执行finnaly块中的代码,所以将释放资源等操作不要放在finnaly块中执行,这种操作是不安全的
线程可以通过setDaemon(true)的方法将线程设置为守护线程。
并且需要注意的是设置守护线程要先于start()方法,否则会报
1 | Exception in thread "main" java.lang.IllegalThreadStateException |
这样的异常,但是该线程还是会执行,只不过会当做正常的用户线程执行。
Java内存模型以及happens-before规则
JMM的介绍
在多线程中稍微不注意就会出现线程安全问题,那么什么是线程安全问题?
在<<深入理解Java虚拟机>>中看到的定义。原文如下:当多个线程访问同一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替运行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获取正确的结果,那这个对象是线程安全的。
出现线程安全的问题一般是因为主内存和工作内存数据不一致性和重排序导致的,
而解决线程安全的问题最重要的就是理解这两种问题是怎么来的,
那么,理解它们的核心在于理解java内存模型(JMM)。
在多线程条件下,多个线程肯定会相互协作完成一件事情,一般来说就会涉及到多个线程间相互通信告知彼此的状态以及当前的执行结果等,
另外,为了性能优化,还会涉及到编译器指令重排序和处理器指令重排序。下面会一一来聊聊这些知识。
内存模型抽象结构
线程间协作通信可以类比人与人之间的协作的方式,在现实生活中,之前网上有个流行语“你妈喊你回家吃饭了”,
就以这个生活场景为例,小明在外面玩耍,小明妈妈在家里做饭,做晚饭后准备叫小明回家吃饭,那么就存在两种方式:
共享变量
小明妈妈要去上班了十分紧急这个时候手机又没有电了,于是就在桌子上贴了一张纸条“饭做好了,放在…”小明回家后看到纸条如愿吃到妈妈做的饭菜,
那么,如果将小明妈妈和小明作为两个线程,那么这张纸条就是这两个线程间通信的共享变量,通过读写共享变量实现两个线程间协作;线程通信
妈妈的手机还有电,妈妈在赶去坐公交的路上给小明打了个电话,这种方式就是通知机制来完成协作。同样,可以引申到线程间通信机制。
通过上面这个例子,应该有些认识。
在并发编程中主要需要解决两个问题:1. 线程之间如何通信;2.线程之间如何完成同步(这里的线程指的是并发执行的活动实体)。
通信是指线程之间以何种机制来交换信息,主要有两种:共享内存和消息传递。这里,可以分别类比上面的两个举例。
java内存模型是共享内存的并发模型,线程之间主要通过读-写共享变量来完成隐式通信。
如果程序员不能理解Java的共享内存模型在编写并发程序时一定会遇到各种各样关于内存可见性的问题。
哪些是共享变量?
在java程序中所有实例域,静态域,数组元素都是放在堆内存中(所有线程均可访问到,是可以共享的),而局部变量,方法定义参数和异常处理器参数不会在线程间共享
共享数据会出现线程安全的问题,而非共享数据不会出现线程安全的问题。
关于JVM运行时内存区域在后面会讲到。JMM抽象结构模型
我们知道CPU的处理速度和主存的读写速度不是一个量级的,为了平衡这种巨大的差距,每个CPU都会有缓存。
因此,共享变量会先放在主存中,每个线程都有属于自己的工作内存,并且会把位于主存中的共享变量拷贝到自己的工作内存,之后的读写操作均使用位于工作内存的变量副本,并在某个时刻将工作内存的变量副本写回到主存中去。
JMM就从抽象层次定义了这种方式,并且JMM决定了一个线程对共享变量的写入何时对其他线程是可见的。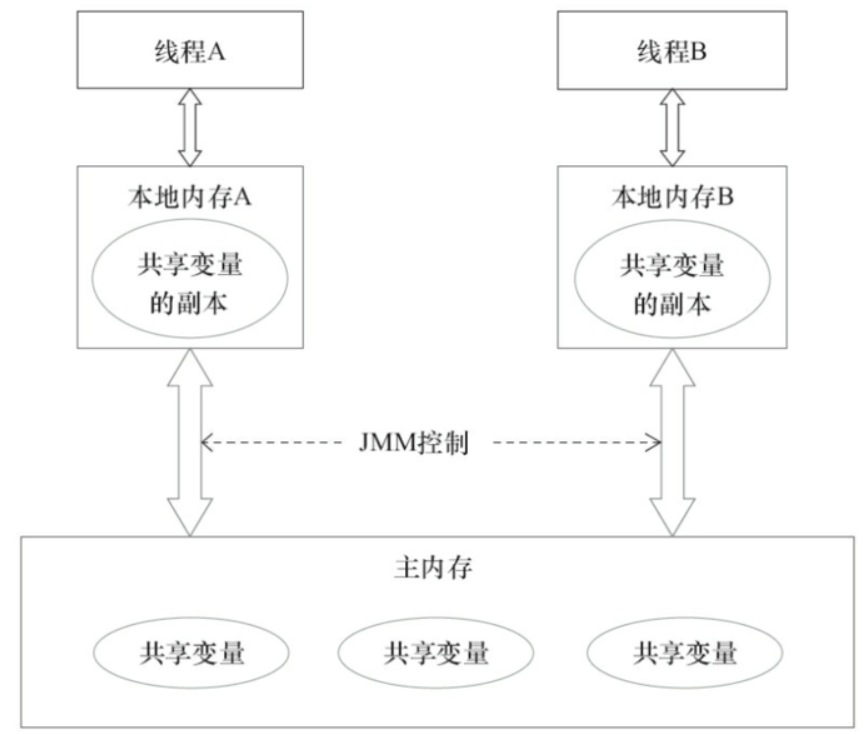
如图为JMM抽象示意图,线程A和线程B之间要完成通信的话,要经历如下两步:线程A从主内存中将共享变量读入线程A的工作内存后并进行操作,之后将数据重新写回到主内存中;
线程B从主存中读取最新的共享变量
从另一个角度去看,线程A和线程B就好像通过共享变量在进行隐式通信。
这其中有很有意思的问题,如果线程A更新后数据并没有及时写回到主存,而此时线程B读到的是过期的数据,这就出现了“脏读”现象。
可以通过同步机制(控制不同线程间操作发生的相对顺序)来解决或通过volatile关键字使得每次volatile变量都能够强制刷新到主存,从而对每个线程都是可见的。
重排序
一个好的内存模型实际上会放松对处理器和编译器规则的束缚,也就是说软件技术和硬件技术都为同一个目标而进行奋斗:在不改变程序执行结果的前提下,尽可能提高并行度。
JMM对底层尽量减少约束,使其能够发挥自身优势。
因此,在执行程序时,为了提高性能,编译器和处理器常常会对指令进行重排序。
一般重排序可以分为如下三种:
编译器优化的重排序编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;指令级并行的重排序现代处理器采用了指令级并行技术来将多条指令重叠执行。
如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;内存系统的重排序由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行的。
如图,1属于编译器重排序,而2和3统称为处理器重排序。
这些重排序会导致线程安全的问题,一个很经典的例子就是DCL问题,这个在以后的文章中会具体去聊。
针对编译器重排序JMM的编译器重排序规则会禁止一些特定类型的编译器重排序;针对处理器重排序编译器在生成指令序列的时候会通过插入内存屏障指令来禁止某些特殊的处理器重排序。
那么什么情况下,不能进行重排序了?下面就来说说数据依赖性。有如下代码:
1 | double pi = 3.14 //A |
这是一个计算圆面积的代码,由于A,B之间没有任何关系,对最终结果也不会存在关系,它们之间执行顺序可以重排序。
因此可以执行顺序可以是A->B->C或者B->A->C执行最终结果都是3.14,即A和B之间没有数据依赖性。
具体的定义为:如果两个操作访问同一个变量,且这两个操作有一个为写操作,此时这两个操作就存在数据依赖性
这里就存在三种情况:1. 读后写;2.写后写;3. 写后读,者三种操作都是存在数据依赖性的,如果重排序会对最终执行结果会存在影响。
编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖性关系的两个操作的执行顺序
另外,还有一个比较有意思的就是as-if-serial语义。
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提供并行度),(单线程)程序的执行结果不能被改变。
编译器,runtime和处理器都必须遵守as-if-serial语义。
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,runtime和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的
比如上面计算圆面积的代码,在单线程中,会让人感觉代码是一行一行顺序执行上,实际上A,B两行不存在数据依赖性可能会进行重排序,即A,B不是顺序执行的。
as-if-serial语义使程序员不必担心单线程中重排序的问题干扰他们,也无需担心内存可见性问题。
happens-before
上面的内容讲述了重排序原则,一会是编译器重排序一会是处理器重排序,如果让程序员再去了解这些底层的实现以及具体规则,那么程序员的负担就太重了,严重影响了并发编程的效率。
因此,JMM为程序员在上层提供了六条规则,这样我们就可以根据规则去推论跨线程的内存可见性问题,而不用再去理解底层重排序的规则。
定义
由于这两个操作可以在一个线程之内,也可以是在不同线程之间。
因此,JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证(如果A线程的写操作a与B线程的读操作b之间存在happens-before关系,尽管a操作和b操作在不同的线程中执行,但JMM向程序员保证a操作将对b操作可见)。
具体的定义为:
- 如果
A操作happens-beforeB操作,那么A操作的执行结果将对B操作可见,而且A操作的执行顺序排在B操作之前。 - 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。
如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)。
- 上面的1)是JMM对程序员的承诺。
从程序员的角度来说,可以这样理解happens-before关系:如果A happens-before B,那么Java内存模型将向程序员保证——A操作的结果将对B可见,且A的执行顺序排在B之前。注意,这只是Java内存模型向程序员做出的保证! - 上面的2)是JMM对编译器和处理器重排序的约束原则。
正如前面所言,JMM其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。
JMM这么做的原因是:程序员对于这两个操作是否真的被重排序并不关心,程序员关心的是程序执行时的语义不能被改变(即执行结果不能被改变)。
因此,happens-before关系本质上和as-if-serial语义是一回事。
比较一下as-if-serial和happens-before:
- as-if-serial语义保证单线程内程序的执行结果不被改变,happens-before关系保证正确同步的多线程程序的执行结果不被改变。
- as-if-serial语义给编写单线程程序的程序员创造了一个幻境:单线程程序是按程序的顺序来执行的。happens-before关系给编写正确同步的多线程程序的程序员创造了一个幻境:正确同步的多线程程序是按happens-before指定的顺序来执行的。
只要结果不改变,就可以进行重排序 - as-if-serial语义和happens-before这么做的目的,都是为了在不改变程序执行结果的前提下,尽可能地提高程序执行的并行度。
规则
程序顺序规则一个线程中的每个操作,happens-before于该线程中的任意后续操作
(一段代码在单线程中执行的结果是有序的。
注意是执行结果,因为虚拟机、处理器会对指令进行重排序。
虽然重排序了,但是并不会影响程序的执行结果,所以程序最终执行的结果与顺序执行的结果是一致的。
故而这个规则只对单线程有效,在多线程环境下无法保证正确性。)监视器锁规则对一个监视器的解锁,happens-before于随后对这个监视器的加锁
(无论是在单线程环境还是多线程环境,一个锁处于被锁定状态,那么必须先执行unlock操作后面才能进行lock操作。)volatile变量规则对一个volatile域的写,happens-before于任意后续对这个volatile的读传递性如果A happens-before B,且B happens-before C,那么A happens-before C。start()线程启动规则Thread对象的start()方法先行发生于此线程的每个一个动作;
(假定线程A在执行过程中,在A的run方法中执行ThreadB.start()来启动线程B,那么线程A对共享变量的修改在接下来线程B开始执行后确保对线程B可见。)join()线程终结规则线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
(假定线程A在执行的过程中,通过制定ThreadB.join()等待线程B终止,那么线程B在终止之前对共享变量的修改在线程A等待返回后可见。)线程中断规则对线程interrupted()方法的调用先行于被中断线程的代码检测到中断时间的发生。finalize()对象终结规则一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始。示例1
假设线程A执行writer()方法之后,线程B执行reader()方法,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
public void reader() {
if (flag) { //3
int i = a; //4
...
}
}
}
那么线程B执行4的时候一定能看到线程A写入的值吗?注意,a不是volatile变量。
答案是肯定的。因为根据happens-before规则,我们可以得到如下关系:- 根据程序顺序规则,1 happens-before 2;3 happens-before 4。
- 根据volatile规则,2 happens-before 3。
- 根据传递性规则,1 happens-before 4。
因此,综合运用程序顺序规则、volatile规则及传递性规则,我们可以得到1 happens-before 4,即线程B在执行4的时候一定能看到A写入的值。
上述关系图示如下: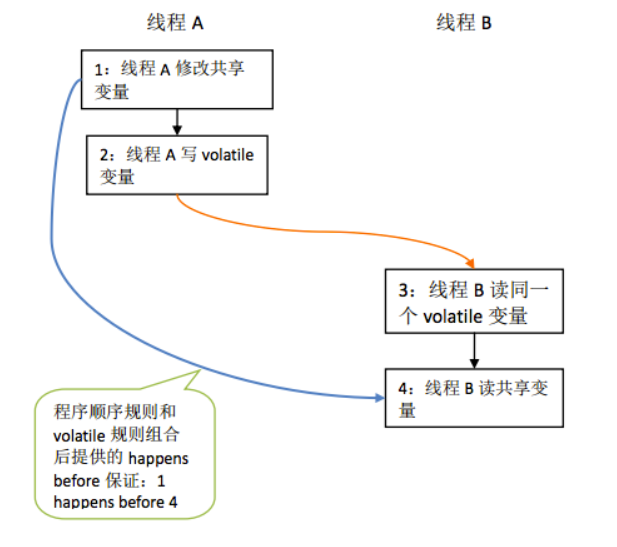
示例2
1 | class MonitorExample { |
假设线程A执行writer()方法之后,线程B执行reader()方法。
那么根据happens-before规则,我们可以得到:
- 根据程序顺序规则,1 happens-before 2,2 happens-before 3;4 happens-before 5,5 happens-before 6。
- 根据监视器锁规则,3 happens-before 4。
- 根据传递性规则,2 happens-before 5。
上述关系图示如下: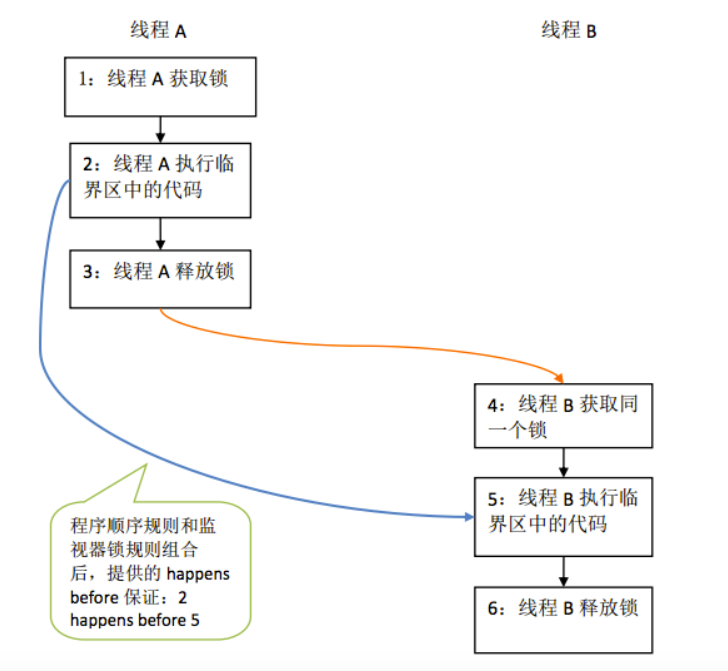
示例3
1 | int a = 3; //1 |
这里//2对b赋值的操作会用到变量a,那么java的“单线程happen-before原则”就保证//2的中的a的值一定是3,而不是0,5,等其他乱七八糟的值,因为//1书写在//2前面,//1对变量a的赋值操作对//2一定可见。
因为//2中有用到//1中的变量a,再加上java内存模型提供了“单线程happen-before原则”,所以java虚拟机不许可操作系统对//1 //2操作进行指令重排序,即不可能有//2在//1之前发生。
但是对于下面的代码:两个语句直接没有依赖关系,所以指令重排序可能发生,即对b的赋值可能先于对a的赋值。
1 | int a = 3; |
示例4
1 | public class A { |
1 | //线程1执行的代码: |
1 | //线程2执行的代码: |
1 | //线程3执行的代码: |
如果某个时刻执行完“线程1” 马上执行“线程2”,因为“线程1”执行A类的method1方法后肯定要释放锁,“线程2”在执行A类的method2方法前要先拿到锁,符合“锁的happen-before原则”,那么在“线程2”method2方法中的变量var一定是3,所以变量b的值也一定是3。
但是如果是“线程1”、“线程3”、“线程2”这个顺序,那么最后“线程2”method2方法中的b值是3,还是4呢?其结果是可能是3,也可能是4。
的确“线程3”在执行完method3方法后的确要unlock,然后“线程2”有个lock,但是这两个线程用的不是同一个锁,所以JMM这个两个操作之间不符合八大happen-before中的任何一条,所以JMM不能保证“线程3”对var变量的修改对“线程2”一定可见,虽然“线程3”先于“线程2”发生。
示例5
1 | volatile int a; |
1 | a = 1; //1 |
1 | b = a; //2 |
如果线程1 执行//1,“线程2”执行了//2,并且“线程1”执行后,“线程2”再执行,那么符合“volatile的happen-before原则”所以“线程2”中的a值一定是1。
总结
上面已经聊了关于JMM的两个方面:
- JMM的抽象结构(主内存和线程工作内存);
- 重排序以及happens-before规则。
接下来,我们来做一个总结。从多个方面进行考虑。
- 如果让我们设计JMM应该从哪些方面考虑,也就是说JMM承担哪些功能;
- happens-before与JMM的关系;
- 由于JMM,多线程情况下可能会出现哪些问题?
JMM的设计
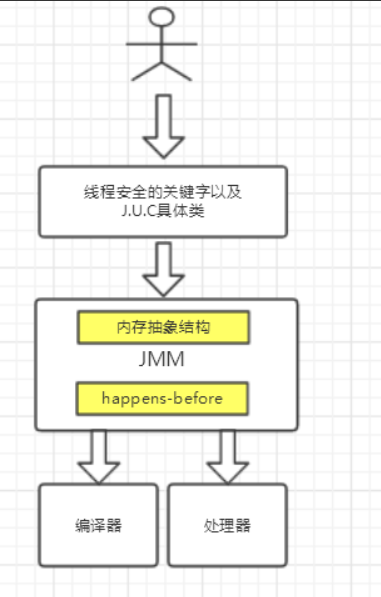
JMM是语言级的内存模型,在我的理解中JMM处于中间层,包含了两个方面:(1)内存模型;(2)重排序以及happens-before规则。
同时,为了禁止特定类型的重排序会对编译器和处理器指令序列加以控制。
而上层会有基于JMM的关键字和J.U.C包下的一些具体类用来方便程序员能够迅速高效率的进行并发编程。
站在JMM设计者的角度,在设计JMM时需要考虑两个关键因素:
程序员对内存模型的使用程序员希望内存模型易于理解、易于编程。程序员希望基于一个强内存模型来编写代码。编译器和处理器对内存模型的实现编译器和处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。编译器和处理器希望实现一个弱内存模型。
另外还要一个特别有意思的事情就是关于重排序问题
更简单的说,重排序可以分为两类:
- 会改变程序执行结果的重排序。
- 不会改变程序执行结果的重排序。
JMM对这两种不同性质的重排序,采取了不同的策略,如下。
- 对于会改变程序执行结果的重排序,JMM要求编译器和处理器必须禁止这种重排序。
- 对于不会改变程序执行结果的重排序,JMM对编译器和处理器不做要求(JMM允许这种 重排序)
JMM的设计图为: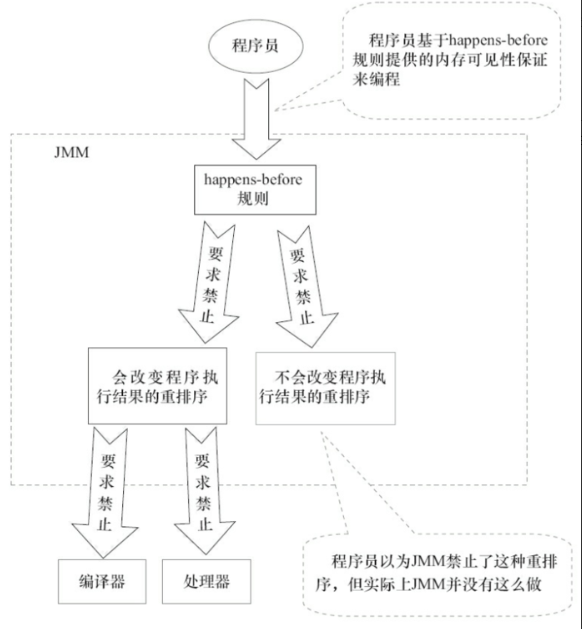
从图可以看出:
- JMM向程序员提供的happens-before规则能满足程序员的需求。
JMM的happens-before规则不但简单易懂,而且也向程序员提供了足够强的内存可见性保证
(有些内存可见性保证其实并不一定真实存在,例如下面的的A happens-before B)。1
2
3double pi = 3.14 //A
double r = 1.0 //B
double area = pi * r * r //C - JMM对编译器和处理器的束缚已经尽可能少。从上面的分析可以看出,JMM其实是在遵循一个基本原则:
只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。
例如,如果编译器经过细致的分析后,认定一个锁只会被单个线程访问,那么这个锁可以被消除。
再如,如果编译器经过细致的分析后,认定一个volatile变量只会被单个线程访问,那么编译器可以把这个volatile变量当作一个普通变量来对待。
这些优化既不会改变程序的执行结果,又能提高程序的执行效率。
happens-before与JMM的关系
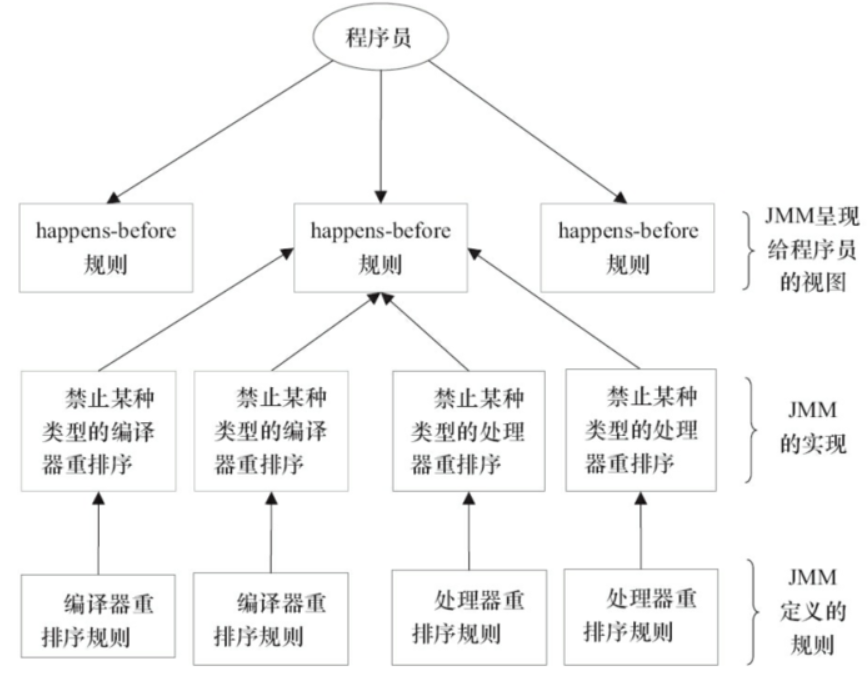
一个happens-before规则对应于一个或多个编译器和处理器重排序规则。
对于Java程序员来说,happens-before规则简单易懂,它避免Java程序员为了理解JMM提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现方法
今后可能需要关注的问题
从上面内存抽象结构来说,可能出在数据“脏读”的现象,这就是数据可见性的问题,
另外,重排序在多线程中不注意的话也容易存在一些问题,比如一个很经典的问题就是DCL(双重检验锁),这就是需要禁止重排序,
另外,在多线程下原子操作例如i++不加以注意的也容易出现线程安全的问题。
但总的来说,在多线程开发时需要从原子性,有序性,可见性三个方面进行考虑。
J.U.C包下的并发工具类和并发容器也是需要花时间去掌握的,这些东西在以后得文章中多会一一进行讨论。
彻底理解synchronized
synchronized简介
在学习知识前,我们先来看一个现象:
- 示例代码开启了10个线程,每个线程都累加了1,000,000次,如果结果正确的话自然而然总数就应该是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class SynchronizedDemo implements Runnable {
private static int count = 0;
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(new SynchronizedDemo());
thread.start();
}
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("result: " + count);
}
public void run() {
for (int i = 0; i < 1000000; i++)
count++;
}
}10 * 1,000,000 = 10,000,000。
可就运行多次结果都不是这个数,而且每次运行结果都不一样。这是为什么了?有什么解决方案了?这就是我们今天要聊的事情。
在之前的学习中我们知道了java内存模型的一些知识,并且已经知道出现线程安全的主要来源于JMM的设计,主要集中在主内存和线程的工作内存而导致的内存可见性问题,以及重排序导致的问题,进一步知道了happens-before规则。
线程运行时拥有自己的栈空间,会在自己的栈空间运行,如果多线程间没有共享的数据也就是说多线程间并没有协作完成一件事情,那么,多线程就不能发挥优势,不能带来巨大的价值。
那么共享数据的线程安全问题怎样处理?很自然而然的想法就是每一个线程依次去读写这个共享变量,这样就不会有任何数据安全的问题,因为每个线程所操作的都是当前最新的版本数据。
那么,在java关键字synchronized就具有使每个线程依次排队操作共享变量的功能。
很显然,这种同步机制效率很低,但synchronized是其他并发容器实现的基础,对它的理解也会大大提升对并发编程的感觉,从功利的角度来说,这也是面试高频的考点。
好了,下面,就来具体说说这个关键字。
synchronized实现原理
在java代码中使用synchronized可是使用在代码块和方法中,根据Synchronized用的位置可以有这些使用场景: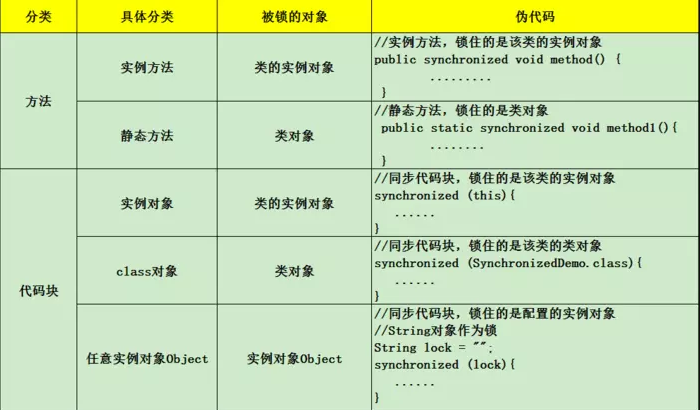
如图,synchronized可以用在方法上也可以使用在代码块中,其中方法是实例方法和静态方法分别锁的是该类的实例对象和该类的对象。
而使用在代码块中也可以分为三种,具体的可以看上面的表格。
这里的需要注意的是:如果锁的是类对象的话,尽管new多个实例对象,但他们仍然是属于同一个类依然会被锁住,即线程之间保证同步关系。
现在我们已经知道了怎样synchronized了,看起来很简单,拥有了这个关键字就真的可以在并发编程中得心应手了吗?爱学的你,就真的不想知道synchronized底层是怎样实现了吗?
对象锁(monitor)机制
现在我们来看看synchronized的具体底层实现。先写一个简单的demo:
1 | public class SynchronizedDemo { |
上面的代码中有一个同步代码块,锁住的是类对象,并且还有一个同步静态方法,锁住的依然是该类的类对象。
编译之后,切换到SynchronizedDemo.class的同级目录之后,然后用javap -v SynchronizedDemo.class查看字节码文件: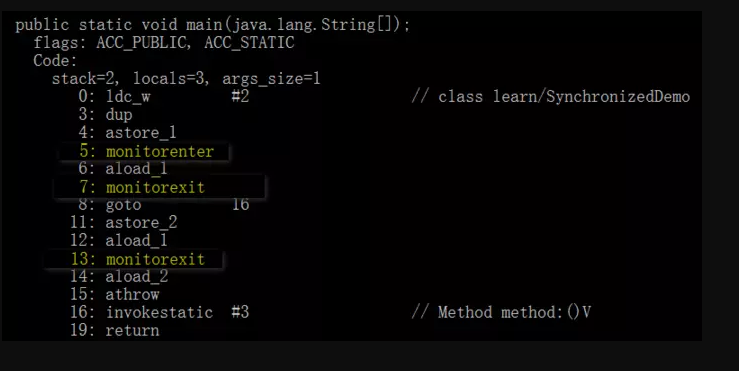
如图,上面用黄色高亮的部分就是需要注意的部分了,这也是添Synchronized关键字之后独有的。
执行同步代码块后首先要先执行monitorenter指令,退出的时候monitorexit指令。
通过分析之后可以看出,使用Synchronized进行同步,其关键就是必须要对对象的监视器monitor进行获取,当线程获取monitor后才能继续往下执行,否则就只能等待。
而这个获取的过程是互斥的,即同一时刻只有一个线程能够获取到monitor。
上面的demo中在执行完同步代码块之后紧接着再会去执行一个静态同步方法,而这个方法锁的对象依然就这个类对象,那么这个正在执行的线程还需要获取该锁吗?
答案是不必的,从上图中就可以看出来,执行静态同步方法的时候就只有一条monitorexit指令,并没有monitorenter获取锁的指令。
这就是锁的重入性,即在同一线程中,线程不需要再次获取同一把锁。
Synchronized先天具有重入性。每个对象拥有一个计数器,当线程获取该对象锁后,计数器就会加一,释放锁后就会将计数器减一。
任意一个对象都拥有自己的监视器,当这个对象由同步块或者这个对象的同步方法调用时,执行方法的线程必须先获取该对象的监视器才能进入同步块和同步方法,
如果没有获取到监视器的线程将会被阻塞在同步块和同步方法的入口处,进入到BLOCKED阻塞状态(关于之前我们讲到的线程的状态转换以及基本操作)
任意线程对Object的访问,首先要获得Object的监视器,如果获取失败,该线程就进入同步状态,线程状态变为BLOCKED阻塞状态,
当Object的监视器占有者释放后,在同步队列中得线程就会有机会重新获取该监视器。
synchronized的happens-before关系
在之前我们讲到happens-before规则,抱着学以致用的原则我们现在来看一看Synchronized的happens-before规则
即监视器锁规则:对同一个监视器的解锁,happens-before于对该监视器的加锁。
- 示例代码该代码的happens-before关系如图所示:
1
2
3
4
5
6
7
8
9
10
11public class MonitorDemo {
private int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
} // 6
}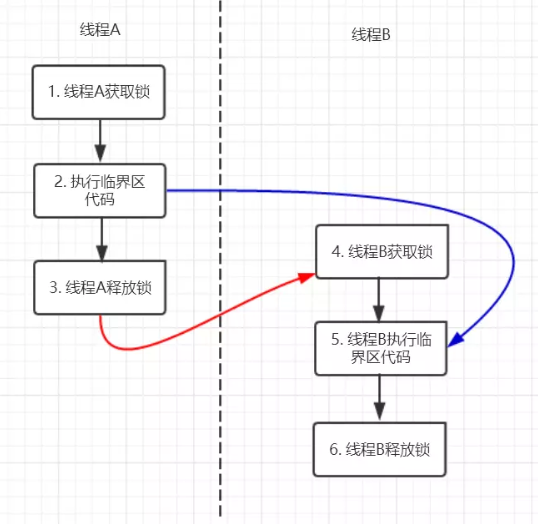
在图中每一个箭头连接的两个节点就代表之间的happens-before关系黑色的是通过程序顺序规则推导出来红色的为监视器锁规则推导而出:线程A释放锁happens-before线程B加锁蓝色的则是通过程序顺序规则和监视器锁规则推测出来happens-befor关系,通过传递性规则进一步推导的happens-before关系
现在我们来重点关注2 happens-before 5,通过这个关系我们可以得出什么?
- 根据happens-before的定义中的一条:如果A happens-before B,则A的执行结果对B可见,并且A的执行顺序先于B。
线程A先对共享变量A进行加一,由2 happens-before 5关系可知线程A的执行结果对线程B可见即线程B所读取到的a的值为1。
锁获取和锁释放的内存语义
我们先来看看基于java内存抽象模型的Synchronized的内存语义。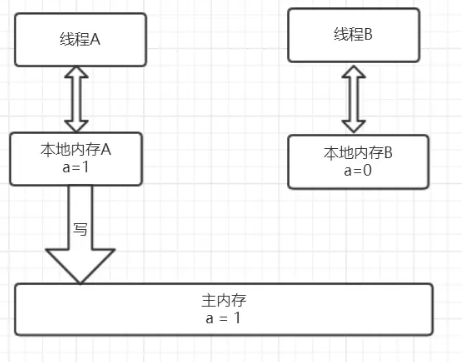
从上图可以看出,线程A会首先先从主内存中读取共享变量a=0的值然后将该变量拷贝到自己的本地内存,进行加一操作后,再将该值刷新到主内存,
整个过程即为线程A 加锁–>执行临界区代码–>释放锁相对应的内存语义。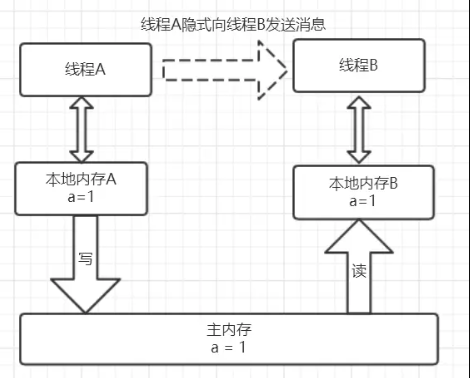
线程B获取锁的时候同样会从主内存中共享变量a的值,这个时候就是最新的值1,然后将该值拷贝到线程B的工作内存中去,释放锁的时候同样会重写到主内存中。
从整体上来看,线程A的执行结果(a=1)对线程B是可见的,
实现原理为:
解释1:释放锁的时候会将值刷新到主内存中,其他线程获取锁时会强制从主内存中获取最新的值。
解释2:先获得锁→清空工作内存→在主内存中拷贝最新变量的副本到工作内存→执行完代码→将更改后的共享变量的值刷新到主内存中→释放锁。
另外也验证了2 happens-before 5,2的执行结果对5是可见的。
从另外一个角度来看,这就像线程A通过主内存中的共享变量和线程B进行通信,A 告诉 B 我们俩的共享数据现在为1啦,
这种线程间的通信机制正好吻合java的内存模型正好是共享内存的并发模型结构。
synchronized优化
通过上面的讨论现在我们对Synchronized应该有所印象了,它最大的特征就是在同一时刻只有一个线程能够获得对象的监视器(monitor),从而进入到同步代码块或者同步方法之中,即表现为互斥性(排它性)。
这种方式肯定效率低下,每次只能通过一个线程,既然每次只能通过一个,这种形式不能改变的话,那么我们能不能让每次通过的速度变快一点了。打个比方,去收银台付款,之前的方式是,大家都去排队,然后去纸币付款收银员找零,有的时候付款的时候在包里拿出钱包再去拿出钱,这个过程是比较耗时的,然后,支付宝解放了大家去钱包找钱的过程,现在只需要扫描下就可以完成付款了,也省去了收银员跟你找零的时间的了。
同样是需要排队,但整个付款的时间大大缩短,是不是整体的效率变高速率变快了?这种优化方式同样可以引申到锁优化上,缩短获取锁的时间
在聊到锁的优化也就是锁的几种状态前,有两个知识点需要先关注:(1)CAS操作 (2)Java对象头,这是理解下面知识的前提条件。
CAS操作
什么是CAS?
加锁是一种悲观的策略,它总是认为每次访问共享资源的时候,总会发生冲突,所以宁愿牺牲性能(时间)来保证数据安全。无锁是一种乐观的策略,它假设线程访问共享资源不会发生冲突,所以不需要加锁,因此线程将不断执行,不需要停止。一旦碰到冲突,就重试当前操作直到没有冲突为止。
无锁的策略使用一种叫做比较交换的技术(CAS Compare And Swap)来鉴别线程冲突,一旦检测到冲突产生,就重试当前操作直到没有冲突为止。
CAS的实现需要硬件指令集的支撑,在JDK1.5后虚拟机才可以使用处理器提供的CMPXCHG指令实现。
悲观锁&乐观锁
简介
悲观锁(Pessimistic Lock):
每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁。由于数据进行加锁,期间对该数据进行读写的其他线程都会进行等待。
乐观锁(Optimistic Lock):
每次获取数据的时候,都不会担心数据被修改,所以每次获取数据的时候都不会进行加锁,但是在更新数据的时候需要判断该数据是否被别人修改过。如果数据被其他线程修改,则不进行数据更新,如果数据没有被其他线程修改,则进行数据更新。由于数据没有进行加锁,期间该数据可以被其他线程进行读写操作。
适用场景:
悲观锁:比较适合写入操作比较频繁的场景,如果出现大量的读取操作,每次读取的时候都会进行加锁,这样会增加大量的锁的开销,降低了系统的吞吐量。
乐观锁:比较适合读取操作比较频繁的场景,如果出现大量的写入操作,数据发生冲突的可能性就会增大,为了保证数据的一致性,应用层需要不断的重新获取数据,这样会增加大量的查询操作,降低了系统的吞吐量。
总结:两种所各有优缺点,读取频繁使用乐观锁,写入频繁使用悲观锁。
CAS如何鉴别冲突
CAS核心算法:执行函数:CAS(V,E,N)
1 | V表示准备要被更新的变量 |
算法思路:V是共享变量,我们拿着自己准备的这个E,去跟V去比较,
如果E == V ,说明当前没有其它线程在操作,所以,我们把N 这个值 写入对象的 V 变量中。
如果 E != V ,说明我们准备的这个E,已经过时了,所以我们要重新准备一个最新的E ,去跟V 比较,比较成功后才能更新 V的值为N。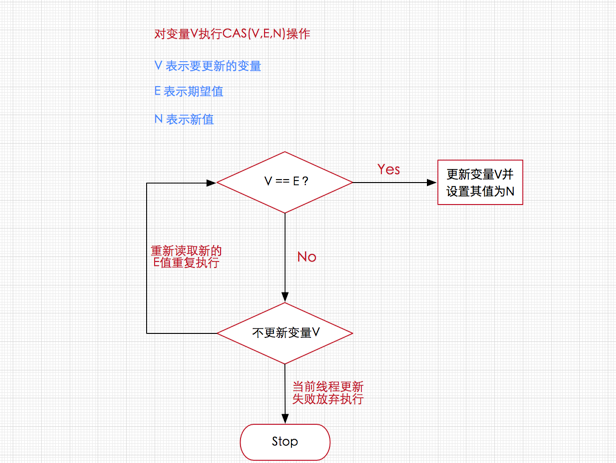
CAS的效果
如果多个线程同时使用CAS操作一个变量的时候,只有一个线程能够修改成功。其余的线程提供的期望值已经与共享变量的值不一样了,所以均会失败。
由于CAS操作属于乐观派,它总是认为自己能够操作成功,所以操作失败的线程将会再次发起操作,而不是被OS(Operating System 操作系统)挂起。
所以说,即使CAS操作没有使用同步锁,其它线程也能够知道对共享变量的影响。
因为其它线程没有被挂起,并且将会再次发起修改尝试,所以无锁操作即CAS操作天生免疫死锁。
另外一点需要知道的是,CAS是系统原语,CAS操作是一条CPU的原子指令,所以不会有线程安全问题。
Java提供的CAS操作:原子操作类
Java提供了一个Unsafe类,其内部方法操作可以像指针一样直接操作内存,方法都是native的。
为了让Java程序员能够受益于CAS等CPU指令,JDK并发包中有一个atomic包,它们是原子操作类,它们使用的是无锁的CAS操作,并且统统线程安全。
atomic包下的几乎所有的类都使用了这个Unsafe类。
- atomic包
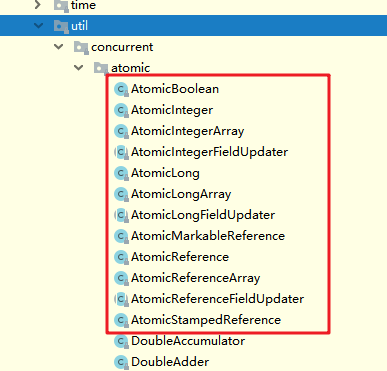
- 分类如下

这些类中,最有代表性的就是AtomicInteger类。
AtomicInteger类源码,省略了部分代码
1 | public class AtomicInteger extends Number implements java.io.Serializable { |
查看指针类unsafe类的incrementAndGet方法的代码实现,颇具教学意义。
这个方法是一个死循环,不断尝试获取最新的值,也就不断获取 CAS(V,E,N)中的E,也就是我们要提供的期望的值。
如果此时 共享变量V 与 我们的 E 相同,那么就把 V 的值 修改成 N。
下面代码中,先不断尝试获取最新的共享变量的值V,如果其它线程也在同时获取V,并且其它线程抢先将共享变量V 修改成了 V+1,
那么此时,当前线程持有的共享变量的值是V,它去与实际的共享变量值V+1比较,将会比较失败,所以本次自增失败。
但是因为是一个死循环,当前线程将会重新调用 get()方法获取最新的值,直到在其它线程执行CAS操作之前,抢先执行自增共享变量的操作。
1 | public final int incrementAndGet(){ |
ABA问题及其解决方案
在CAS的核心算法中,通过死循环不断获取最新的E。
如果在此之间,V被修改了两次,但是最终值还是修改成了旧值V,这个时候,就不好判断这个共享变量是否已经被修改过。
为了防止这种不当写入导致的不确定问题,原子操作类提供了一个带有时间戳的原子操作类。
带有时间戳的原子操作类AtomicStampedReference (音:a tommy k,S dan P de,Reference)
CAS(V,E,N)
当带有时间戳的原子操作类AtomicStampedReference对应的数值被修改时,除了更新数据本身外,还必须要更新时间戳。
当AtomicStampedReference设置对象值时,对象值以及时间戳都必须满足期望值,写入才会成功。
因此,即使对象值被反复读写,写回原值,只要时间戳发生变化,就能防止不恰当的写入。
Synchronized VS CAS
两者主要的区别。
元老级的Synchronized(未优化前)最主要的问题是:在存在线程竞争的情况下会出现线程阻塞和唤醒锁带来的性能问题,因为这是一种互斥同步(阻塞同步)。
而CAS并不是直接将线程挂起,当CAS操作失败后会进行一定的尝试,而非进行耗时的挂起唤醒的操作,因此也叫做非阻塞同步。
CAS的应用场景
在J.U.C包中利用CAS实现类有很多,可以说是支撑起整个concurrency包的实现,在Lock实现中会有CAS改变state变量,在atomic包中的实现类也几乎都是用CAS实现,
关于这些具体的实现场景在之后会详细聊聊,现在有个印象就好了。
CAS的问题
ABA问题
因为CAS会检查旧值有没有变化,这里存在这样一个有意思的问题。
比如一个旧值A变为了成B,然后再变成A,刚好在做CAS时检查发现旧值并没有变化依然为A,但是实际上的确发生了变化。
解决方案可以沿袭数据库中常用的乐观锁方式,添加一个版本号可以解决。原来的变化路径A->B->A就变成了1A->2B->3C。
java这么优秀的语言,当然在java 1.5后的atomic包中提供了AtomicStampedReference来解决ABA问题,解决思路就是这样的。参考上面提到的.自旋时间过长
使用CAS时非阻塞同步,也就是说不会将线程挂起,会自旋(无非就是一个死循环)进行下一次尝试,如果这里自旋时间过长对性能是很大的消耗。
如果JVM能支持处理器提供的pause(暂停)指令,那么在效率上会有一定的提升。只能保证一个共享变量的原子操作
当对一个共享变量执行操作时CAS能保证其原子性,如果对多个共享变量进行操作,CAS就不能保证其原子性。
有一个解决方案是利用对象整合多个共享变量,即一个类中的成员变量就是这几个共享变量。然后将这个对象做CAS操作就可以保证其原子性。
atomic中提供了AtomicReference来保证引用对象之间的原子性。参考上面提到的.
Java对象头
在同步的时候是获取对象的monitor,即获取到对象的锁。
那么对象的锁怎么理解?无非就是类似对对象的一个标志,那么这个标志就是存放在Java对象的对象头。
Java对象头里的Mark Word里默认的存放的对象的Hashcode,分代年龄和锁标记位。
32位JVM Mark Word默认存储结构为
如图在Mark Word会默认存放hasdcode,年龄值以及锁标志位等信息。
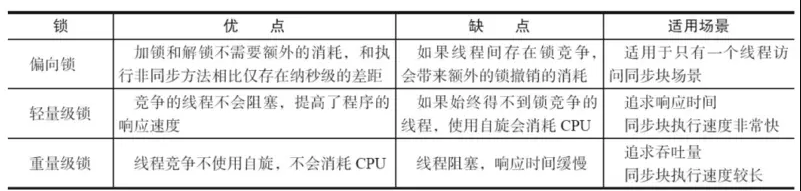
Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态 偏向锁状态 轻量级锁状态 重量级锁状态。
这几个状态会随着竞争情况逐渐升级,锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。
这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
对象的MarkWord变化为下图: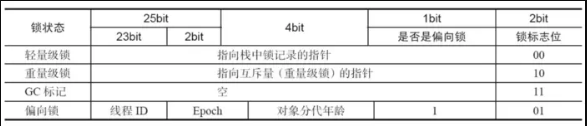
偏向锁
大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。偏向锁(01):一段同步代码只能被一个线程访问,不存在竞争.
偏向锁的获取
当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,
以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。
如果测试成功,表示线程已经获得了锁。
如果测试失败,则需要再测试一下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁):如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程
偏向锁的撤销
偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。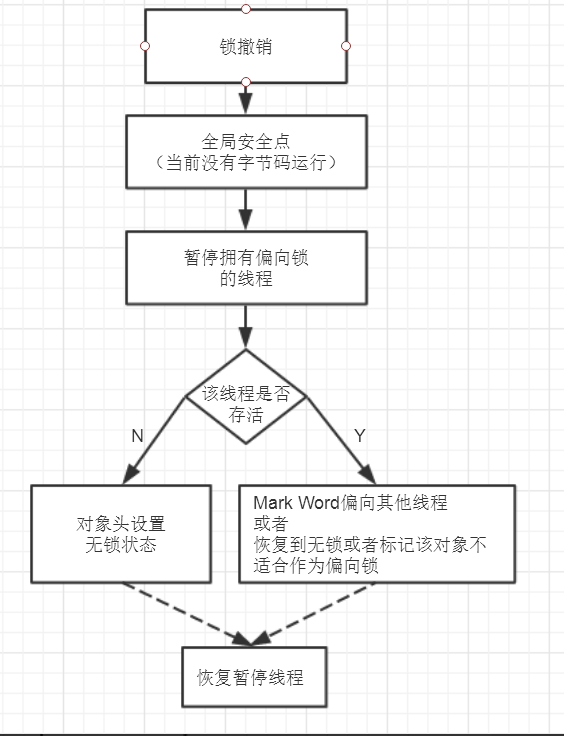
如图,偏向锁的撤销,需要等待全局安全点(在这个时间点上没有正在执行的字节码)。
它会首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否活着,
如果线程不处于活动状态,则将对象头设置成无锁状态;
如果线程仍然活着,拥有偏向锁的栈会被执行,遍历偏向对象的锁记录,栈中的锁记录和对象头的Mark Word要么重新偏向于其他线程,要么恢复到无锁或者标记对象不适合作为偏向锁,最后唤醒暂停的线程。
下图线程1展示了偏向锁获取的过程,线程2展示了偏向锁撤销的过程。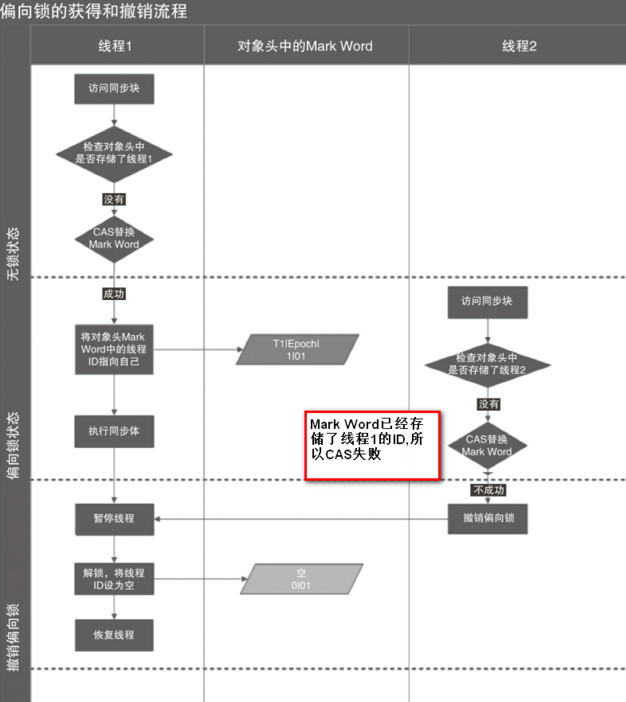
如何关闭偏向锁
偏向锁在Java 6和Java 7里是默认启用的,但是它在应用程序启动几秒钟之后才激活,如有必要可以使用JVM参数来关闭延迟:-XX:BiasedLockingStartupDelay=0。
如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态
轻量级锁
轻量级锁(00):当锁是偏向锁的时候,被其他线程访问了,这时偏向锁就升级为轻量级锁.其他线程会不断自旋获取锁,不会阻塞,从而提高性能.
加锁
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。
然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。
如果成功,当前线程获得锁,
如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,
如果成功,则表示没有竞争发生。
如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
下图是两个线程同时争夺锁,导致锁膨胀的流程图。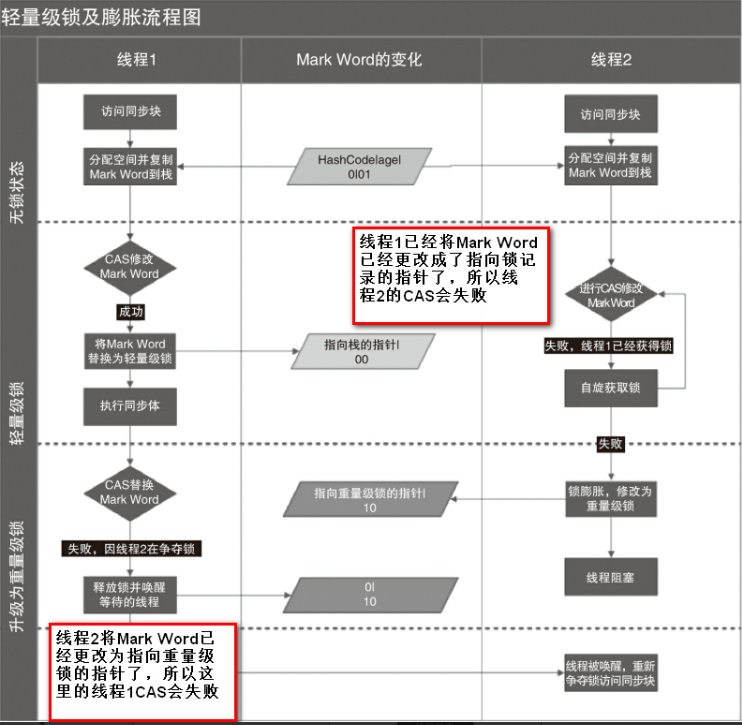
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。
当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
重量级锁
重量级锁(10):当只有一个等待线程,则该线程自旋等待.但自旋到一定的次数,或一个等待,一个持有锁,当第三个过来时,轻量就会变为重量级锁.一个获取锁,其他线程进行阻塞,而不是自旋等待.
各种锁的比较
锁的粗化
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class VolatileDemo {
private static boolean isOver = false;
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
public void run() {
System.out.println("测试1---"+isOver);
while (!isOver)
System.out.println(111);
System.out.println("测试2---"+isOver);
}
});
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isOver = true;
}
}执行结果
立即打印测试1---false,然后一直循环打印111,循环1秒后打印测试2---true
分析System.out.println源码如下1
2
3
4
5
6public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}可以发现是println方法是加了synchronized的
jvm中对锁的优化有一条为锁的粗化如果一系列的连续操作都对同一个对象反复加锁和解锁,
甚至加锁操作是出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗。
如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(膨胀)到整个操作序列的外部(由多次加锁编程只加锁一次)。1
2
3
4
5synchronized{
while(!isOver){
sout();
}
}所以synchronized会将isOver 的值在锁释放前刷回共享内存(共享内存也称为系统内存,也称为主内存)
修改示例
经过上面的理解,我们现在应该知道了该怎样解决了。更正后的代码为:
1 | public class SynchronizedDemo implements Runnable { |
开启十个线程,每个线程在原值上累加1,000,000次,最终正确的结果为10 * 1,000,000=10,000,000,
这里能够计算出正确的结果是因为在做累加操作时使用了同步代码块,这样就能保证每个线程所获得共享变量的值都是当前最新的值,
如果不使用同步的话,就可能会出现A线程累加后,而B线程做累加操作有可能是使用原来的就值,即“脏值”。这样,就导致最终的计算结果不是正确的。
而使用Syncnized就可能保证内存可见性,保证每个线程都是操作的最新值。
彻底理解volatile
volatile简介
通过之前的学习,我们了解到synchronized是阻塞式同步,在线程竞争激烈的情况下会升级为重量级锁。
而volatile就可以说是java虚拟机提供的最轻量级的同步机制。
但它同时不容易被正确理解,也至于在并发编程中很多程序员遇到线程安全的问题就会使用synchronized。
Java内存模型告诉我们,各个线程会将共享变量从主内存中拷贝到工作内存,然后执行引擎会基于工作内存中的数据进行操作处理。
线程在工作内存进行操作后何时会写到主内存中?
这个时机对普通变量是没有规定的,而针对volatile修饰的变量给java虚拟机特殊的约定,
线程对volatile变量的修改会立刻被其他线程所感知,即不会出现数据脏读的现象,从而保证数据的“可见性”。
现在我们有了一个大概的印象就是:被volatile修饰的变量能够保证每个线程能够获取该变量的最新值,从而避免出现数据脏读的现象。
volatile实现原理
volatile是怎样实现了?比如一个很简单的Java代码:
1 | instance = new Instancce() //instance是volatile变量 |
在生成汇编代码时会在volatile修饰的共享变量进行写操作的时候会多出Lock前缀的指令
我们想这个Lock指令肯定有神奇的地方,那么Lock前缀的指令在多核处理器下会发现什么事情了?
主要有这两个方面的影响:
- 将当前处理器缓存行的数据写回系统内存;
- 这个写回内存的操作会使得其他CPU里缓存了该内存地址的数据无效
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1,L2或其他)后再进行操作,但操作完不知道何时会写到内存。
如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。
但是,就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题。
所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,
当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
因此,经过分析我们可以得出如下结论:
- Lock前缀的指令会引起处理器缓存写回内存;
- 一个处理器的缓存回写到内存会导致其他处理器的缓存失效;
- 当处理器发现本地缓存失效后,就会从内存中重读该变量数据,即可以获取当前最新值。
这样针对volatile变量通过这样的机制就使得每个线程都能获得该变量的最新值。
volatile的happens-before关系
经过上面的分析,我们已经知道了volatile变量可以通过缓存一致性协议保证每个线程都能获得最新值,即满足数据的“可见性”。
我一直将并发分析的切入点分为两个核心,三大性质。两个核心
- JMM(Java内存模型)包括:主内存(系统内存)和工作内存(线程内存)
- happens-before
三大性质
- 原子性
- 可见性
- 有序性
(关于三大性质的总结在以后得文章会和大家共同探讨)
废话不多说,先来看两个核心之一:volatile的happens-before关系。
在happens-before规则中有一条volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
下面我们结合具体的代码,我们利用这条规则推导下:
1 | public class VolatileExample { |
上面的实例代码对应的happens-before关系如下图所示: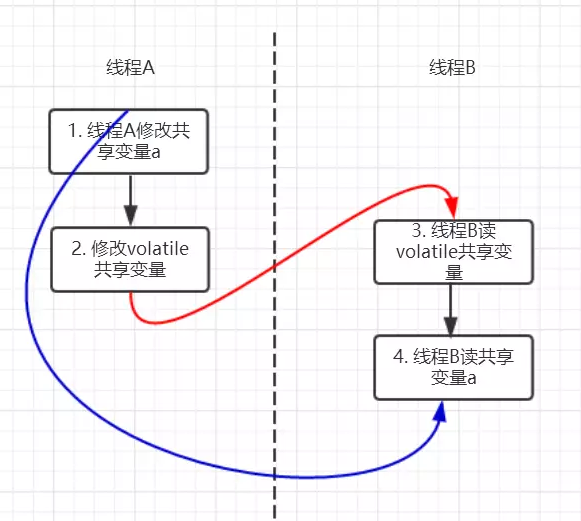
加锁线程A先执行writer方法,然后线程B执行reader方法,图中每一个箭头两个节点就代码一个happens-before关系,黑色的代表根据程序顺序规则推导出来红色的是根据volatile变量的写happens-before 于任意后续对volatile变量的读蓝色的就是根据传递性规则推导出来的
这里的2 happen-before 3,同样根据happens-before规则定义:
如果A happens-before B,则A的执行结果对B可见,并且A的执行顺序先于B的执行顺序
我们可以知道操作2执行结果对操作3来说是可见的,也就是说当线程A将volatile变量 flag更改为true后线程B就能够迅速感知。
volatile的内存语义
还是按照两个核心的分析方式,分析完happens-before关系后我们现在就来进一步分析volatile的内存语义。
还是以上面的代码为例,假设线程A先执行writer方法,线程B随后执行reader方法,初始时线程的本地内存中flag和a都是初始状态,
下图是线程A执行volatile写后的状态图。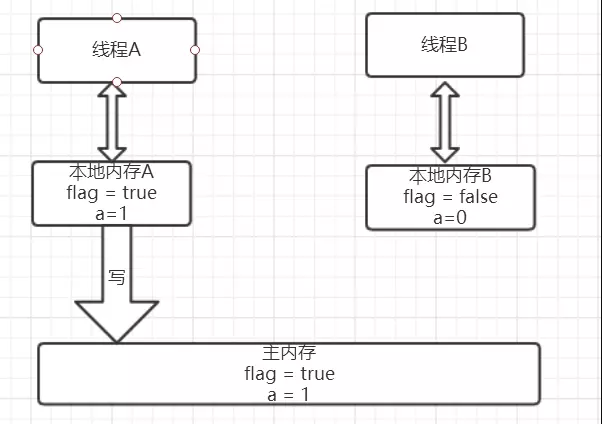
当volatile变量写后,线程中本地内存中共享变量就会置为失效的状态,因此线程B再需要读取从主内存中去读取该变量的最新值。
下图就展示了线程B读取同一个volatile变量的内存变化示意图。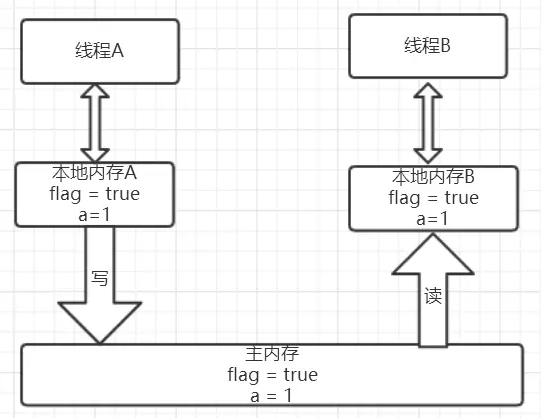
从另外一个角度来看,线程A和线程B之间进行了一次通信,线程A在写volatile变量时,
实际上就像是给B发送了一个消息告诉线程B你现在的值都是旧的了,然后线程B读这个volatile变量时就像是接收了线程A刚刚发送的消息。
既然是旧的了,那线程B该怎么办了?自然而然就只能去主内存去取啦。
好的,我们现在两个核心:happens-before以及内存语义现在已经都了解清楚了。
是不是还不过瘾,突然发现原来自己会这么爱学习(微笑脸),那我们下面就再来一点干货—-volatile内存语义的实现。
内存语义的实现
我们都知道,为了性能优化,JMM在不改变正确语义的前提下,会允许编译器和处理器对指令序列进行重排序,
那如果想阻止重排序要怎么办了?答案是可以添加内存屏障。
内存屏障
JMM内存屏障分为四类见下图,
Store写:将处理器缓存的数据刷新到内存中。(工作内存新值写入到主内存)
Load读:将内存存储的数据拷贝到处理器的缓存中。(工作内存中读取主内存的数据)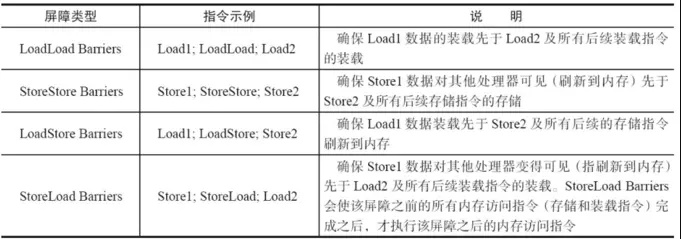
java编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。
为了实现volatile的内存语义,JMM会限制特定类型的编译器和处理器重排序,JMM会针对编译器制定volatile重排序规则表:
“NO”表示禁止重排序。
为了实现volatile内存语义时,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎是不可能的,为此,JMM采取了保守策略:
- 在每个volatile写操作的前面插入一个StoreStore屏障
- 在每个volatile写操作的后面插入一个StoreLoad屏障
- 在每个volatile读操作的后面插入一个LoadLoad屏障
- 在每个volatile读操作的后面插入一个LoadStore屏障
需要注意的是:volatile写操作是在前后分别插入内存屏障,而volatile读操作是在后面插入两个内存屏障StoreStore屏障禁止上面的普通写和下面的volatile写重排序;StoreLoad屏障防止上面的volatile写与下面可能有的volatile读/写重排序LoadLoad屏障禁止下面所有的普通读操作和上面的volatile读重排序LoadStore屏障禁止下面所有的普通写操作和上面的volatile读重排序
下面以两个示意图进行理解,图片摘自相当好的一本书《java并发编程的艺术》。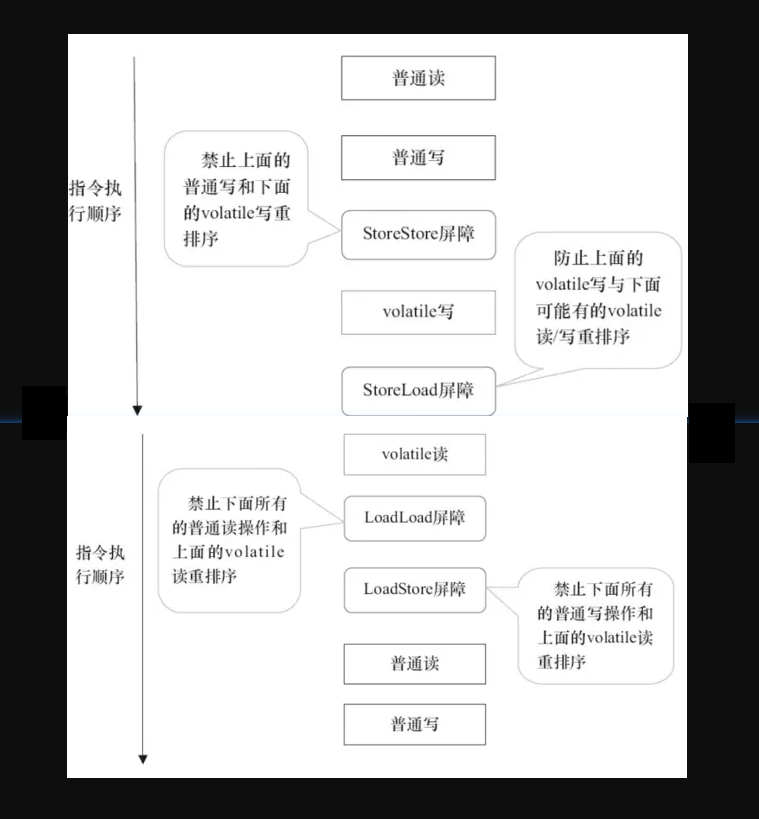
示例理解
示例1,不加volatile关键字
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class VolatileDemo {
private static boolean isOver = false;
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
public void run() {
System.out.println("测试1---"+isOver);
while (!isOver);
System.out.println("测试2---"+isOver);
}
});
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isOver = true;
}
}执行结果
立即打印测试1---false,然后程序一直卡着,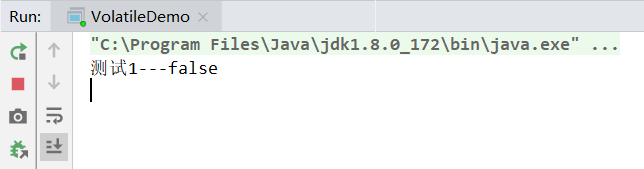
分析
在main线程中将isOver改为了true后,thread的工作内存该变量值仍有效,所以会一直循环
示例2,加volatile关键字
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class VolatileDemo {
private static boolean isOver = false;
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
public void run() {
System.out.println("测试1---"+isOver);
while (!isOver);
System.out.println("测试2---"+isOver);
}
});
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isOver = true;
}
}执行结果
立即打印测试1---false,再过1秒打印测试2---true,然后结束进程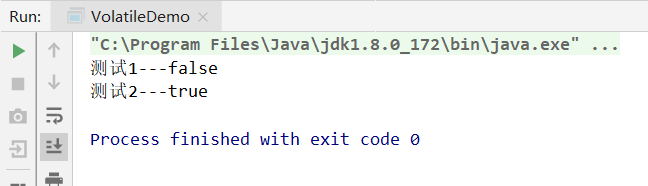
分析
注意不同点,现在已经将isOver设置成了volatile变量,这样在main线程中将isOver改为了true后,thread的工作内存该变量值就会失效,从而需要再次从主内存中读取该值,
现在能够读出isOver最新值为true从而能够结束在thread里的死循环,从而能够顺利停止掉thread线程。
示例3,不加volatile关键字,循环打印,锁的粗化
示例代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class VolatileDemo {
private static boolean isOver = false;
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
public void run() {
System.out.println("测试1---"+isOver);
while (!isOver)
System.out.println(111);
System.out.println("测试2---"+isOver);
}
});
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
isOver = true;
}
}执行结果
立即打印测试1---false,然后一直循环打印111,循环1秒后打印测试2---true分析System.out.println源码如下1
2
3
4
5
6public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}可以发现是println方法是加了synchronized的
jvm中对锁的优化有一条为锁的粗化如果一系列的连续操作都对同一个对象反复加锁和解锁,
甚至加锁操作是出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗。
如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展(膨胀)到整个操作序列的外部(由多次加锁编程只加锁一次)。1
2
3
4
5synchronized{
while(!isOver){
sout();
}
}所以synchronized会将isOver 的值在锁释放前刷回共享内存(共享内存也称为系统内存,也称为主内存)
volatile是否能保证数组中元素的可见性?
问
一个线程向volatile的数组中设置值,而另一个线程向volatile的数组中读取。
比如seg.setValue(2),随后另一个线程调用seg.getValue(2),前一个线程设置的值对读取的线程是可见的吗?
1 | public class Seg { |
答
volatile的数组只针对数组的引用具有volatile的语义,而不是它的元素
在后面的COW(CopyOnWriteArrayList)中为什么需要复制呢? 如果将array 数组设定为volatile的, 对volatile变量写happens-before读,读线程不是能够感知到volatile变量的变化吗?
就可以使用这个进行回答.
你以为你真的了解final吗?
final的简介
final可以修饰变量 方法 类,用于表示所修饰的内容一旦赋值之后就不会再被改变,
比如String类就是一个final类型的类。
即使能够知道final具体的使用方法,我想对final在多线程中存在的重排序问题也很容易忽略,希望能够一起做下探讨。
final的具体使用场景
final能够修饰变量,方法和类,也就是final使用范围基本涵盖了java每个地方,
下面就分别以锁修饰的位置:变量,方法和类分别来说一说。
变量
在java中变量,可以分为成员变量以及方法局部变量。因此也是按照这种方式依次来说,以避免漏掉任何一个死角。
成员变量
通常每个类中的成员变量可以分为类变量(static修饰的变量)以及实例变量。
针对这两种类型的变量赋初值的时机是不同的,
类变量有两个时机赋初值,而实例变量则可以有三个时机赋初值。类变量
- 声明时赋初值
- 静态代码块中赋初值
实例变量 - 声明时赋初值
- 非静态代码块中赋初值
- 构造器中赋初值
当final变量未初始化时系统不会进行隐式初始化,会出现报错。
这样说起来还是比较抽象,下面用具体的代码来演示。(代码涵盖了final修饰变量所有的可能情况,耐心看下去会有收获的:) )
看上面的图片已经将每种情况整理出来了,这里用截图的方式也是觉得在IDE出现红色出错的标记更能清晰的说明情况。
现在我们来将这几种情况归纳整理一下:
类变量:必须要在静态初始化块中指定初始值或者声明该类变量时指定初始值,而且只能在这两个地方之一进行指定;实例变量:必要要在非静态初始化块,声明该实例变量或者在构造器中指定初始值,而且只能在这三个地方进行指定。
局部变量
final局部变量由程序员进行显式初始化,
- 如果final局部变量已经
进行了初始化则后面就不能再次进行更改, - 如果final变量
未进行初始化,可以进行赋值,当且仅有一次赋值,一旦赋值之后再次赋值就会出错。
下面用具体的代码演示final局部变量的情况: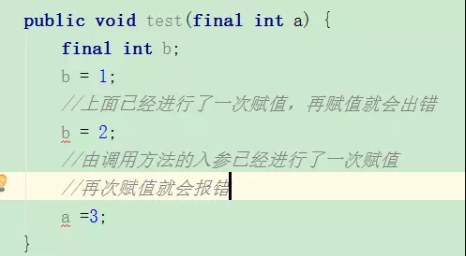
final基本数据类型 VS final引用数据类型
现在我们来换一个角度进行考虑,final修饰的是基本数据类型和引用类型有区别吗?
通过上面的例子我们已经看出来,如果final修饰的是一个基本数据类型的数据,一旦赋值后就不能再次更改,
那么,如果final是引用数据类型了?这个引用的对象能够改变吗?我们同样来看一段代码。
1 | public class FinalExample { |
当我们对final修饰的引用数据类型变量person的属性改成22,是可以成功操作的。
通过这个实验我们就可以看出来:
- 当final修饰基本数据类型变量时,不能对基本数据类型变量重新赋值,因此基本数据类型变量不能被改变。
- 而对于引用类型变量而言,它仅仅保存的是一个引用,final只保证这个引用类型变量所引用的地址不会发生改变,即一直引用这个对象,但这个对象属性是可以改变的。
宏变量
利用final变量的不可更改性,在满足一下三个条件时,该变量就会成为一个“宏变量”,即是一个常量。
- 使用final修饰符修饰;
- 在定义该final变量时就指定了初始值;
- 该初始值在编译时就能够唯一指定。
注意:当程序中其他地方使用该宏变量的地方,编译器会直接替换成该变量的值
方法
重写?
当父类的方法被final修饰的时候,子类不能重写父类的该方法,
比如在Object中,getClass()方法就是final的,我们就不能重写该方法,但是hashCode()方法就不是被final所修饰的,我们就可以重写hashCode()方法。
我们还是来写一个例子来加深一下理解: 先定义一个父类,里面有final修饰的方法test();
1 | public class FinalExampleParent { |
然后FinalExample继承该父类,当重写test()方法时出现报错,如下图:
通过这个现象我们就可以看出来被final修饰的方法不能够被子类所重写。
重载?
1 | public class FinalExampleParent { |
可以看出被final修饰的方法是可以重载的。
经过我们的分析可以得出如下结论:
- 父类的final方法是不能够被子类重写的
- final方法是可以被重载的
类
当一个类被final修饰时,表明该类是不能被子类继承的。
子类继承往往可以重写父类的方法和改变父类属性,会带来一定的安全隐患,因此,当一个类不希望被继承时就可以使用final修饰。
还是来写一个小例子:
1 | public final class FinalExampleParent { |
父类会被final修饰,当子类继承该父类的时候,就会报错,如下图:
final的例子
final经常会被用作不变类上,利用final的不可更改性。我们先来看看什么是不变类。
不变类的意思是创建该类的实例后,该实例的实例变量是不可改变的。
满足以下条件则可以成为不可变类:
- 使用private和final修饰符来修饰该类的成员变量
- 提供带参的构造器用于初始化类的成员变量;
- 仅为该类的成员变量提供getter方法,不提供setter方法,因为普通方法无法修改fina修饰的成员变量;
- 如果有必要就重写Object类 的hashCode()和equals()方法,应该保证用equals()判断相同的两个对象其Hashcode值也是相等的。
JDK中提供的八个包装类和String类都是不可变类,我们来看看String的实现。
1 | /** The value is used for character storage. */ |
可以看出String的value就是final修饰的,上述其他几条性质也是吻合的。
多线程中你真的了解final吗?
上面我们聊的final使用,应该属于Java基础层面的,当理解这些后我们就真的算是掌握了final吗?
有考虑过final在多线程并发的情况吗?
在java内存模型中我们知道java内存模型为了能让处理器和编译器底层发挥他们的最大优势,对底层的约束就很少,也就是说针对底层来说java内存模型就是弱内存数据模型。
同时,处理器和编译为了性能优化会对指令序列有编译器和处理器重排序。
那么,在多线程情况下,final会进行怎样的重排序?会导致线程安全的问题吗?下面,就来看看final的重排序。
final域重排序规则
final域为基本类型重排序规则
假设线程A在执行writer()方法,线程B执行reader()方法。
1 | public class FinalDemo { |
写final域重排序规则
写final域的重排序规则禁止对final域的写重排序到构造函数之外,
这个规则的实现主要包含了两个方面:
- JMM禁止编译器把final域的写重排序到构造函数之外;
- 编译器会在final域写之后,构造函数return之前,插入一个storestore屏障关于内存屏障。这个屏障可以禁止处理器把final域的写重排序到构造函数之外。
我们再来分析writer方法,虽然只有一行代码,但实际上做了两件事情:
- 构造了一个FinalDemo对象;
- 把这个对象赋值给成员变量finalDemo。
我们来画下存在的一种可能执行时序图,如下: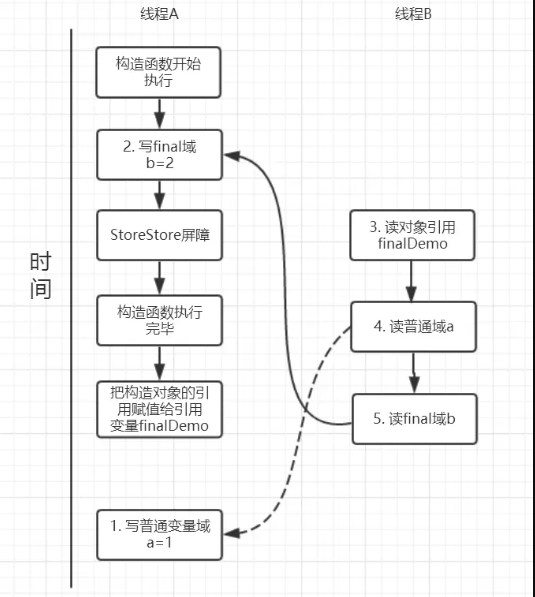
由于a,b之间没有数据依赖性,普通域(普通变量)a可能会被重排序到构造函数之外,线程B就有可能读到的是普通变量a初始化之前的值(零值),这样就可能出现错误。
而final域变量b,根据重排序规则,会禁止final修饰的变量b重排序到构造函数之外,从而b能够正确赋值,线程B就能够读到final变量初始化后的值。
因此,写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域就不具有这个保障。
比如在上例,线程B有可能就是一个未正确初始化的对象finalDemo。
读final域重排序规则
注意,这个规则仅仅是针对处理器
读final域重排序规则为:在一个线程中,初次读对象引用和初次读该对象包含的final域,JMM会禁止这两个操作的重排序。处理器会在读final域操作的前面插入一个LoadLoad屏障。
实际上,读对象的引用和读该对象的final域存在间接依赖性,一般处理器不会重排序这两个操作。但是有一些处理器会重排序,因此,这条禁止重排序规则就是针对这些处理器而设定的。
read()方法主要包含了三个操作:
- 初次读引用变量finalDemo;
- 初次读引用变量finalDemo的普通域a;
- 初次读引用变量finalDemo的final与b;
假设线程A写过程没有重排序,那么线程A和线程B有一种的可能执行时序为下图: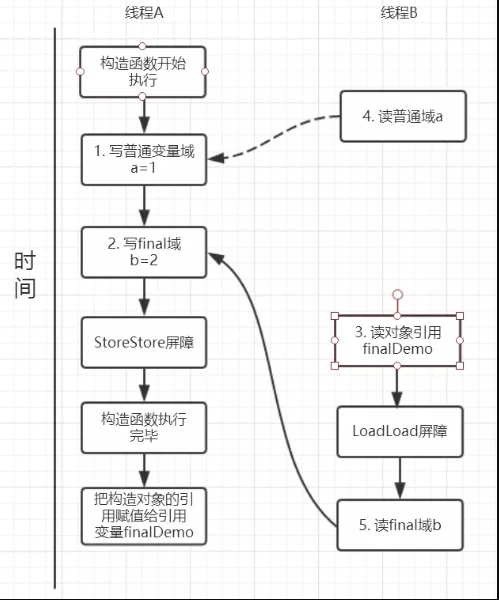
读对象的普通域被重排序到了读对象引用的前面就会出现线程B还未读到对象引用就在读取该对象的普通域变量,这显然是错误的操作。
而final域的读操作就“限定”了在读final域变量前已经读到了该对象的引用,从而就可以避免这种情况。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读这个包含这个final域的对象的引用。
final域为引用类型重排序规则
我们已经知道了final域是基本数据类型的时候重排序规则是怎么的了?如果是引用数据类型了?我们接着继续来探讨。
对final修饰的对象的成员域写操作
针对引用数据类型,final域写针对编译器和处理器重排序增加了这样的约束:在构造函数内对一个final修饰的对象的成员域的写入,与随后在构造函数之外把这个被构造的对象的引用赋给一个引用变量,这两个操作是不能被重排序的。
注意这里的是“增加了这样的约束”也就说前面对final基本数据类型的重排序规则在这里还是使用。
这句话是比较拗口的,下面结合实例来看。
1 | public class FinalReferenceDemo { |
针对上面的实例程序,线程线程A执行wirterOne方法,执行完后线程B执行writerTwo方法,然后线程C执行reader方法。
下图就以这种执行时序出现的一种情况来讨论(耐心看完才有收获)。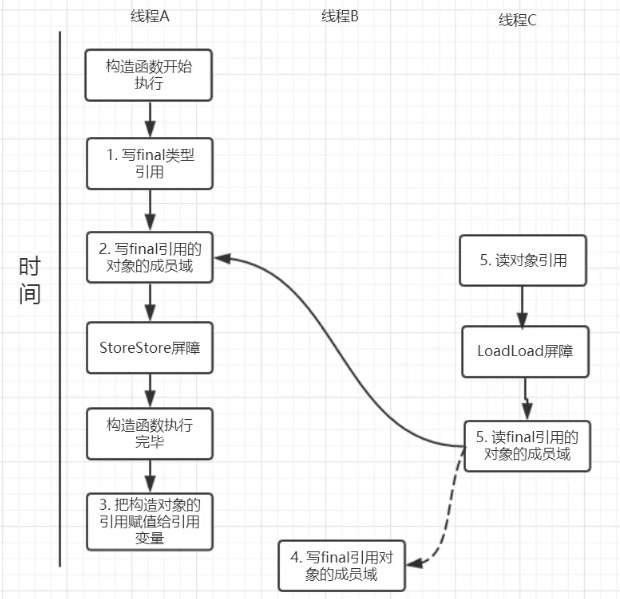
由于对final域的写禁止重排序到构造方法外,因此1和3不能被重排序。
由于一个final域的引用对象的成员域写入不能与随后将这个被构造出来的对象赋给引用变量重排序,因此2和3不能重排序。
对final修饰的对象的成员域读操作
JMM可以确保线程C至少能看到写线程A对final引用的对象的成员域的写入,即能看下arrays[0] = 1,而写线程B对数组元素的写入可能看到可能看不到。
JMM不保证线程B的写入对线程C可见,线程B和线程C之间存在数据竞争,此时的结果是不可预知的。如果可见的,可使用锁或者volatile。
关于final重排序的总结
按照final修饰的数据类型分类:
- 基本数据类型:
- final域写:禁止
final域写与构造方法重排序,即禁止final域写重排序到构造方法之外,从而保证该对象对所有线程可见时,该对象的final域全部已经初始化过。 - final域读:禁止初次
读对象的引用与读该对象包含的final域的重排序。
- final域写:禁止
- 引用数据类型:
- 额外增加约束:禁止在构造函数对
一个final修饰的对象的成员域的写入与随后将这个被构造的对象的引用赋值给引用变量重排序
- 额外增加约束:禁止在构造函数对
final的实现原理
上面我们提到过,写final域会要求编译器在final域写之后,构造函数返回前插入一个StoreStore屏障(内存屏障)。
读final域的重排序规则会要求编译器在读final域的操作前插入一个LoadLoad屏障。
注意:x86=32位 x64=64位
计算机属性可查看
很有意思的是,如果以X86处理为例,X86不会对写-写重排序,所以StoreStore屏障可以省略。
由于不会对有间接依赖性的操作重排序,所以在X86处理器中,读final域需要的LoadLoad屏障也会被省略掉。
也就是说,以X86为例的话,对final域的读/写的内存屏障都会被省略!具体是否插入还是得看是什么处理器
为什么final引用不能从构造函数中“溢出”?
这里还有一个比较有意思的问题:上面对final域写重排序规则可以确保我们在使用一个对象引用的时候该对象的final域已经在构造函数被初始化过了。
但是这里其实是有一个前提条件的,也就是:在构造函数,不能让这个被构造的对象被其他线程可见,也就是说该对象引用不能在构造函数中“逸出”。
以下面的例子来说:
1 | public class FinalReferenceEscapeDemo { |
可能的执行时序如图所示: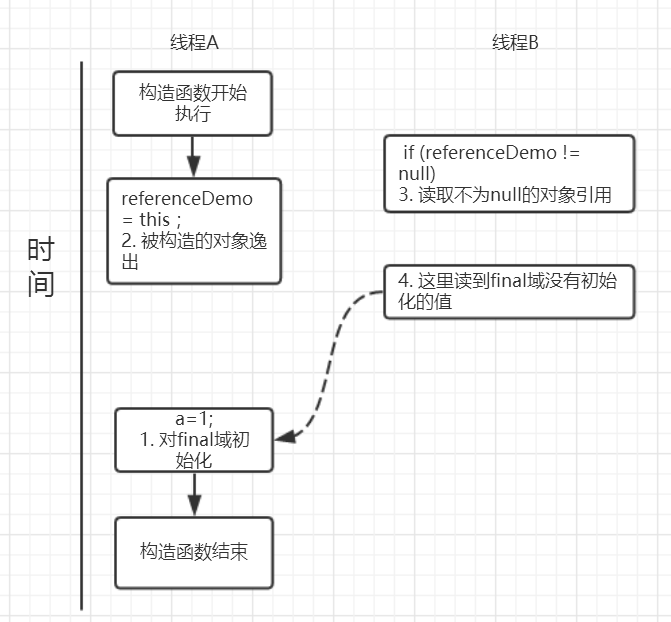
假设一个线程A执行writer方法另一个线程执行reader方法。
因为构造函数中操作1和2之间没有数据依赖性,1和2可以重排序,先执行了2,这个时候引用对象referenceDemo是个没有完全初始化的对象,而当线程B去读取该对象时就会出错。
尽管依然满足了final域写重排序规则:在引用对象对所有线程可见时,其final域已经完全初始化成功。
但是,引用对象“this”逸出,该代码依然存在线程安全的问题。
三大性质总结:原子性、可见性以及有序性
三大性质简介
在并发编程中分析线程安全的问题时往往需要切入点,那就是两个核心,三大性质。
1 | 两个核心 |
关于synchronized和volatile已经讨论过了,就想着将并发编程中这两大神器在原子性 有序性 可见性上做一个比较,
当然这也是面试中的高频考点,值得注意。
synchronized: 具有原子性,有序性和可见性;
volatile:具有有序性和可见性
原子性
原子性是指一个操作是不可中断的,要么全部执行成功要么全部执行失败,有着“同生共死”的感觉。
及时在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程所干扰。
我们先来看看哪些是原子操作,哪些不是原子操作,有一个直观的印象:
1 | int a = 10; //1 |
上面这四个语句中只有第1个语句是原子操作,将10赋值给线程工作内存的变量a,
而语句2(a++),实际上包含了三个操作:1. 读取变量a的值;2:对a进行加一的操作;3.将计算后的值再赋值给变量a,而这三个操作无法构成原子操作。
对语句3,4的分析同理可得这两条语句不具备原子性。
当然,java内存模型中定义了8种操作都是原子的,不可再分的。
- lock(锁定):作用于主内存中的变量,它把一个变量标识为一个线程独占的状态;
- unlock(解锁):作用于主内存中的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
- read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便后面的load动作使用;
- load(载入):作用于工作内存中的变量,它把read操作从主内存中得到的变量值放入工作内存中的变量副本
- use(使用):作用于工作内存中的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作;
- assign(赋值):作用于工作内存中的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作;
- store(存储):作用于工作内存的变量,它把工作内存中一个变量的值传送给主内存中以便随后的write操作使用;
- write(操作):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
上面的这些指令操作是相当底层的,可以作为扩展知识面掌握下。
那么如何理解这些指令了?
比如,把一个变量从主内存中复制到工作内存中就需要执行read,load操作,将工作内存同步到主内存中就需要执行store,write操作。
注意的是:java内存模型只是要求上述两个操作是顺序执行的并不是连续执行的。
也就是说read和load之间可以插入其他指令,store和writer可以插入其他指令。
比如对主内存中的a,b进行访问就可以出现这样的操作顺序:read a,read b, load b,load a。
由原子性变量操作read,load,use,assign,store,write,可以大致认为基本数据类型的访问读写具备原子性(例外就是long和double的非原子性协定)
synchronized
上面一共有八条原子操作,其中六条可以满足基本数据类型的访问读写具备原子性,还剩下lock和unlock两条原子操作。
如果我们需要更大范围的原子性操作就可以使用lock和unlock原子操作。
尽管jvm没有把lock和unlock开放给我们使用,但jvm以更高层次的指令monitorenter和monitorexit指令开放给我们使用,反应到java代码中就是synchronized关键字,也就是说synchronized满足原子性。
volatile
我们先来看这样一个例子:
1 | public class VolatileExample { |
开启10个线程,每个线程都自加10,000次,如果不出现线程安全的问题最终的结果应该就是:10*10,000 = 100,000;
可是运行多次都是小于100,000的结果,问题在于volatile并不能保证原子性
在前面说过counter++这并不是一个原子操作,包含了三个步骤:1.读取变量counter的值;2.对counter加一;3.将新值赋值给变量counter。
如果线程A读取counter到工作内存后,其他线程对这个值已经做了自增操作后,那么线程A的这个值自然而然就是一个过期的值,因此,总结果必然会是小于100,000的。
如果让volatile保证原子性,必须符合以下两条规则:
1.运算结果并不依赖于变量的当前值,或者能够确保只有一个线程修改变量的值;
2.变量不需要与其他的状态变量共同参与不变约束
有序性
synchronized
synchronized语义表示锁在同一时刻只能由一个线程进行获取,当锁被占用后,其他线程只能等待。
因此,synchronized语义就要求线程在访问读写共享变量时只能“串行”执行,因此synchronized具有有序性。
volatile
在java内存模型中说过,为了性能优化,编译器和处理器会进行指令重排序;
也就是说java程序天然的有序性可以总结为:如果在本线程内观察,所有的操作都是有序的;如果在一个线程观察另一个线程,所有的操作都是无序的。
在单例模式的实现上有一种双重检验锁(DCL)(Double-checked Locking)的方式。代码如下:
1 | public class Singleton { |
这里为什么要加volatile了?我们先来分析一下不加volatile的情况,有问题的语句是这条:
1 | instance = new Singleton(); |
这条语句实际上包含了三个操作:1.分配对象的内存空间;2.初始化对象;3.设置instance指向刚分配的内存地址。
但由于存在重排序的问题,可能有以下的执行顺序: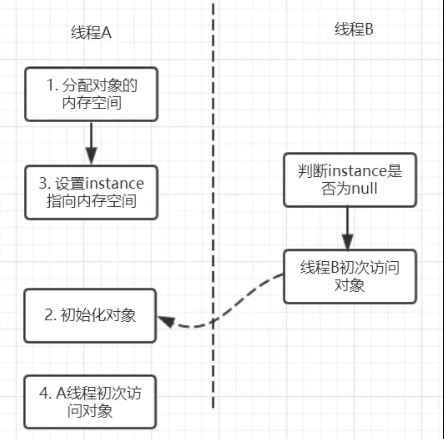
如果2和3进行了重排序的话,线程B进行判断if(instance==null)时就会为true,而实际上这个instance并没有初始化成功,显而易见对线程B来说之后的操作就会是错得。
而用volatile修饰的话就可以禁止2和3操作重排序,从而避免这种情况。
所以,volatile包含禁止指令重排序的语义,其具有有序性。
可见性
可见性是指当一个线程修改了共享变量后,其他线程能够立即得知这个修改。
- 通过之前对synchronzed内存语义进行了分析,当线程获取锁时会从主内存中获取共享变量的最新值,释放锁的时候会将共享变量同步到主内存中。从而,synchronized具有可见性。
- 同样的在volatile分析中,会通过在指令中添加lock指令,以实现内存可见性。因此, volatile具有可见性
总结
通过这篇文章,主要是比较了synchronized和volatile在三条性质:原子性 可见性 有序性的情况,归纳如下:
synchronized: 具有原子性,有序性和可见性;
volatile:具有有序性和可见性
初识Lock与AbstractQueuedSynchronizer(AQS)
concurrent包的结构层次
在针对并发编程中,Doug Lea大师为我们提供了大量实用,高性能的工具类,针对这些代码进行研究会让我们队并发编程的掌握更加透彻也会大大提升我们队并发编程技术的热爱。
这些代码在java.util.concurrent包下。如下图,即为concurrent包的目录结构图。
其中包含了两个子包:atomic以及lock,另外在concurrent下的阻塞队列以及executors,这些就是concurrent包中的精华,之后会慢慢进行学习。
而这些类的实现主要是依赖于volatile以及CAS(在之前我们已经提到),从整体上来看concurrent包的整体实现图如下图所示: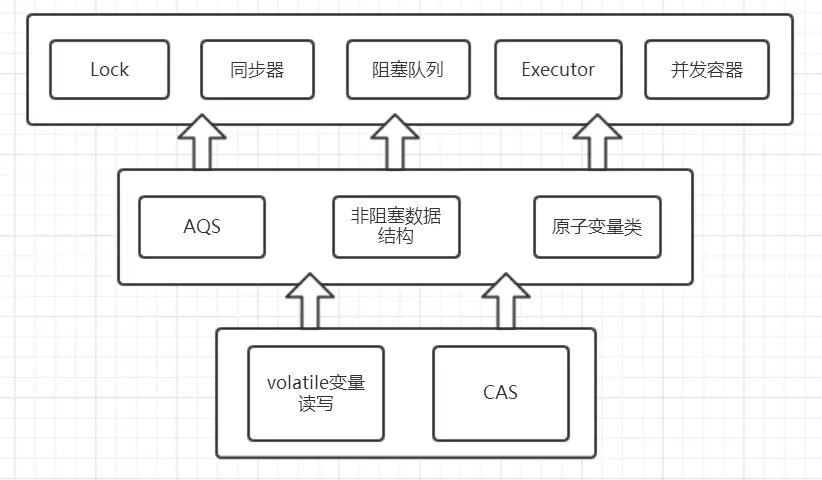
lock简介
我们下面来看concurent包下的lock子包。
锁是用来控制多个线程访问共享资源的方式,一般来说,一个锁能够防止多个线程同时访问共享资源。
在Lock接口出现之前,java程序主要是靠synchronized关键字实现锁功能的,而java SE5之后,并发包中增加了lock接口,它提供了与synchronized一样的锁功能。
虽然它失去了像synchronize关键字隐式加锁解锁的便捷性,但是却拥有了锁获取和释放的可操作性,可中断的获取锁以及超时获取锁等多种synchronized关键字所不具备的同步特性。
通常使用显示使用lock的形式如下:
1 | Lock lock = new ReentrantLock(); |
需要注意的是synchronized同步块执行完成或者遇到异常是锁会自动释放,而lock必须调用unlock()方法释放锁,因此在finally块中释放锁。
Lock接口API
我们现在就来看看lock接口定义了哪些方法:
void lock();//获取锁void lockInterruptibly() throws InterruptedException;//获取锁的过程能够响应中断boolean tryLock();//非阻塞式响应中断能立即返回,获取锁返回true反之返回fasleboolean tryLock(long time, TimeUnit unit) throws InterruptedException;//超时获取锁,在超时内或者未中断的情况下能够获取锁Condition newCondition();//获取与lock绑定的等待通知组件,当前线程必须获得了锁才能进行等待,进行等待时会先释放锁,当再次获取锁时才能从等待中返回
那么在locks包下有哪些类实现了该接口了?先从最熟悉的ReentrantLock说起。
1 | public class ReentrantLock implements Lock, java.io.Serializable |
很显然ReentrantLock实现了lock接口,接下来我们来仔细研究一下它是怎样实现的。
当你查看源码时你会惊讶的发现ReentrantLock并没有多少代码,另外有一个很明显的特点是:
基本上所有的方法的实现实际上都是调用了其静态内存类Sync中的方法,而Sync类继承了AbstractQueuedSynchronizer(AQS)。
可以看出要想理解ReentrantLock关键核心在于对队列同步器AbstractQueuedSynchronizer(AQS)(简称同步器)的理解。
初识AQS
同步器是用来构建锁和其他同步组件的基础框架,它的实现主要依赖一个int成员变量(state)来表示同步状态以及通过一个FIFO队列构成等待队列。
它的子类必须重写AQS的几个protected修饰的用来改变同步状态的方法,其他方法主要是实现了排队和阻塞机制。
状态的更新使用getState,setState以及compareAndSetState这三个方法。
子类被推荐定义为自定义同步组件的静态内部类,同步器自身没有实现任何同步接口,它仅仅是定义了若干同步状态的获取和释放方法来供自定义同步组件的使用,
同步器既支持独占式获取同步状态,也可以支持共享式获取同步状态,这样就可以方便的实现不同类型的同步组件。
同步器是实现锁(也可以是任意同步组件)的关键,在锁的实现中聚合同步器,利用同步器实现锁的语义。
可以这样理解二者的关系:
锁Lock是面向使用者,它定义了使用者与锁交互的接口,隐藏了实现细节;同步器AQS是面向锁的实现者,它简化了锁的实现方式,屏蔽了同步状态的管理,线程的排队,等待和唤醒等底层操作。
锁和同步器很好的隔离了使用者和实现者所需关注的领域。
AQS的模板方法设计模式
AQS的设计是使用模板方法设计模式,它将一些方法开放给子类进行重写,而同步器给同步组件所提供模板方法又会重新调用被子类所重写的方法。
举个例子,AQS中需要重写的方法tryAcquire:
1 | protected boolean tryAcquire(int arg) { |
ReentrantLock中NonfairSync(继承AQS)会重写该方法为:
1 | protected final boolean tryAcquire(int acquires) { |
而AQS中的模板方法acquire():
1 | public final void acquire(int arg) { |
此时当继承AQS的NonfairSync调用模板方法acquire时就会调用已经被NonfairSync重写的tryAcquire方法。
这就是使用AQS的方式,在弄懂这点后会lock的实现理解有很大的提升。
可以归纳总结为这么几点:
- 同步组件(这里不仅仅指锁,还包括CountDownLatch等)的实现依赖于同步器AQS,在同步组件实现中,使用AQS的方式被推荐定义继承AQS的静态内存类;
- AQS采用模板方法进行设计,AQS的protected修饰的方法需要由继承AQS的子类进行重写实现,当调用方法时就会调用被重写的方法;
- AQS负责同步状态的管理,线程的排队,等待和唤醒这些底层操作,而Lock等同步组件主要专注于实现同步语义;
- 在重写AQS的方式时,使用AQS提供的getState(),setState(),compareAndSetState()方法进行修改同步状态
AQS可重写的方法如下图(摘自《java并发编程的艺术》一书):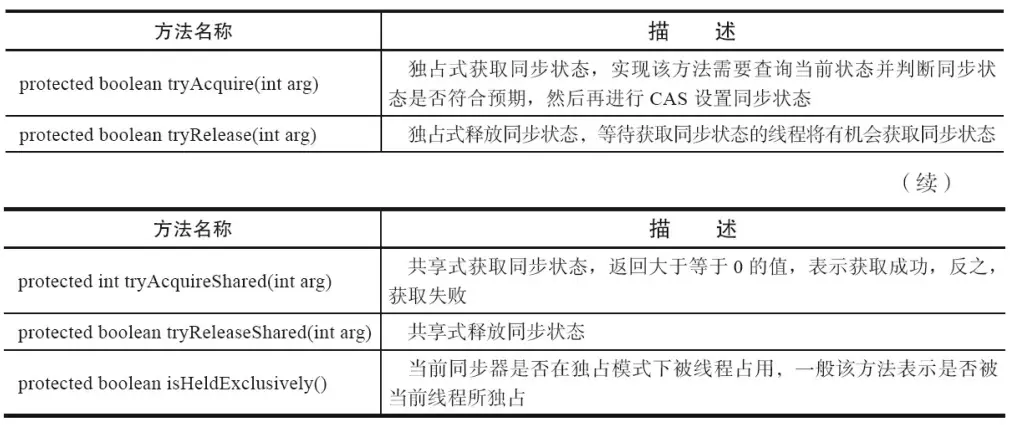
在实现同步组件时AQS提供的模板方法如下图: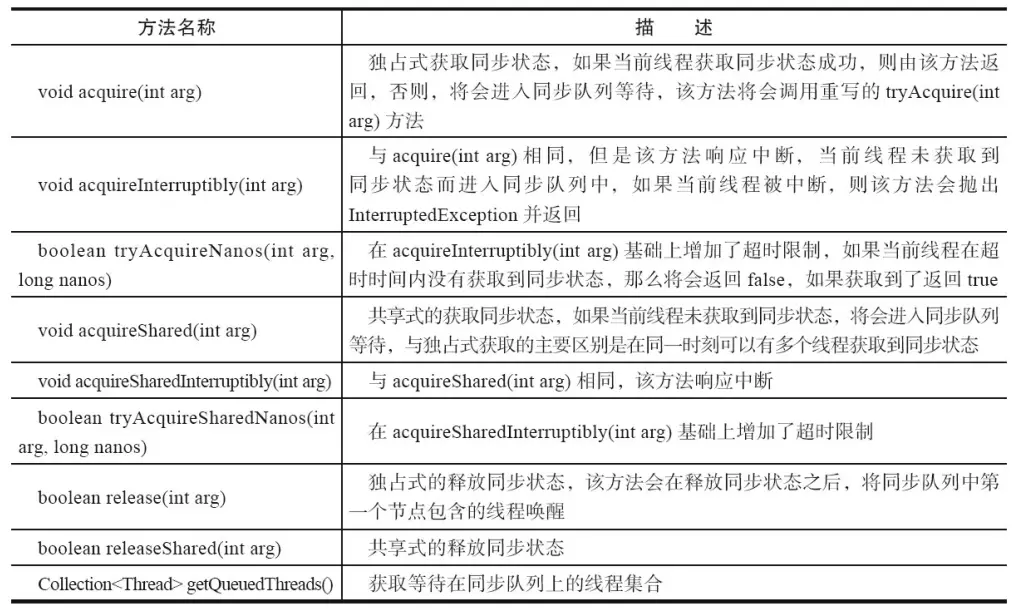
AQS提供的模板方法可以分为3类:
- 独占式获取与释放同步状态;
- 共享式获取与释放同步状态;
- 查询同步队列中等待线程情况;
同步组件通过AQS提供的模板方法实现自己的同步语义。
一个例子
下面使用一个例子来进一步理解下AQS的使用。这个例子也是来源于AQS源码中的example。
1 | class Mutex implements Lock, java.io.Serializable { |
1 | public class MutextDemo { |
- 执行情况:
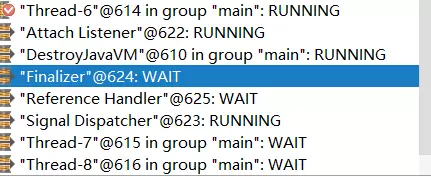
上面的这个例子实现了独占锁的语义,在同一个时刻只允许一个线程占有锁。
MutexDemo新建了10个线程,分别睡眠3s。
从执行情况也可以看出来当前Thread-6正在执行占有锁而其他Thread-7,Thread-8等线程处于WAIT状态。
按照推荐的方式,Mutex定义了一个继承AQS的静态内部类Sync,并且重写了AQS的tryAcquire等等方法,而对state的更新也是利用了setState(),getState(),compareAndSetState()这三个方法。
在实现实现lock接口中的方法也只是调用了AQS提供的模板方法(因为Sync继承AQS)。
从这个例子就可以很清楚的看出来,在同步组件的实现上主要是利用了AQS,而AQS封装了同步状态的修改,线程排队等底层实现,通过AQS的模板方法可以很方便的给同步组件的实现者进行调用。
而针对用户来说,只需要调用同步组件提供的方法来实现并发编程即可。
同时在新建一个同步组件时需要把握的两个关键点是:
- 实现同步组件时推荐定义继承AQS的静态内存类,并重写需要的protected修饰的方法;
- 同步组件语义的实现依赖于AQS的模板方法,而AQS模板方法又依赖于被AQS的子类所重写的方法(调用方法实际调用的是重写方法)。
通俗点说,因为AQS整体设计思路采用模板方法设计模式,同步组件以及AQS的功能实际上划分成各自的两部分:
AQS实现者的角度
通过可重写的方法:独占式: tryAcquire()(独占式获取同步状态),tryRelease()(独占式释放同步状态);
共享式 :tryAcquireShared()(共享式获取同步状态),tryReleaseShared()(共享式释放同步状态);
告诉AQS怎样判断当前同步状态是否成功获取或者是否成功释放。
同步组件专注于对当前同步状态的逻辑判断,从而实现自己的同步语义。
这句话比较抽象,举例来说,上面的Mutex例子中通过tryAcquire方法实现自己的同步语义,在该方法中如果当前同步状态为0(即该同步组件没被任何线程获取),当前线程可以获取同时将状态更改为1返回true,否则,该组件已经被线程占用返回false。
很显然,该同步组件只能在同一时刻被线程占用,Mutex专注于获取释放的逻辑来实现自己想要表达的同步语义。
AQS的角度
而对AQS来说,只需要同步组件返回的true和false即可,因为AQS会对true和false会有不同的操作,true会认为当前线程获取同步组件成功直接返回,而false的话就AQS也会将当前线程插入同步队列等一系列的方法。
总的来说,同步组件通过重写AQS的方法实现自己想要表达的同步语义,而AQS只需要同步组件表达的true和false即可,AQS会针对true和false不同的情况做不同的处理,至于底层实现,可以看下面介绍。
深入理解AbstractQueuedSynchronizer(AQS)
AQS简介
在上面文章中我们对lock和AbstractQueuedSynchronizer(AQS)有了初步的认识。
在同步组件的实现中,AQS是核心部分,同步组件的实现者通过使用AQS提供的模板方法实现同步组件语义,AQS则实现了对同步状态的管理,以及对阻塞线程进行排队,等待通知等等一些底层的实现处理。
AQS的核心也包括了这些方面:同步队列 独占式锁的获取和释放 共享锁的获取和释放以及可中断锁 超时等待锁获取这些特性的实现,而这些实际上则是AQS提供出来的模板方法
归纳整理如下:独占式锁
void acquire(int arg);独占式获取同步状态,如果获取失败则插入同步队列进行等待;void acquireInterruptibly(int arg);与acquire方法相同,但在同步队列中进行等待的时候可以检测中断;boolean tryAcquireNanos(int arg, long nanosTimeout);在acquireInterruptibly基础上增加了超时等待功能,在超时时间内没有获得同步状态返回false;boolean release(int arg);释放同步状态,该方法会唤醒在同步队列中的下一个节点
共享式锁
void acquireShared(int arg);共享式获取同步状态,与独占式的区别在于同一时刻有多个线程获取同步状态;void acquireSharedInterruptibly(int arg);在acquireShared方法基础上增加了能响应中断的功能;boolean tryAcquireSharedNanos(int arg, long nanosTimeout);在acquireSharedInterruptibly基础上增加了超时等待的功能;boolean releaseShared(int arg);共享式释放同步状态
要想掌握AQS的底层实现,其实也就是对这些模板方法的逻辑进行学习。
在学习这些模板方法之前,我们得首先了解下AQS中的同步队列是一种什么样的数据结构,因为同步队列是AQS对同步状态的管理的基石。
同步队列
当共享资源被某个线程占有,其他请求该资源的线程将会阻塞,从而进入同步队列。
就数据结构而言,队列的实现方式无外乎两者一是通过数组的形式,另外一种则是链表的形式。AQS中的同步队列则是通过链式方式进行实现。
接下来,很显然我们至少会抱有这样的疑问:
1. 节点的数据结构是什么样的?2. 是单向还是双向?3. 是带头节点的还是不带头节点的?
我们依旧先是通过看源码的方式。
在AQS有一个静态内部类Node,其中有这样一些属性:
1 | volatile int waitStatus //节点状态 |
waitStatus节点状态:
1 | 状态字段,只接受值: |
现在我们知道了节点的数据结构类型,并且每个节点拥有其上一个和下一个节点,很显然这是一个双向队列。
同样的我们可以用一段demo看一下。
1 | public class LockDemo { |
实例代码中开启了5个线程,先获取锁之后再睡眠10S中,实际上这里让线程睡眠是想模拟出当线程无法获取锁时进入同步队列的情况。
通过debug,当Thread-4(在本例中最后一个线程)获取锁失败后进入同步时,AQS时现在的同步队列如图所示: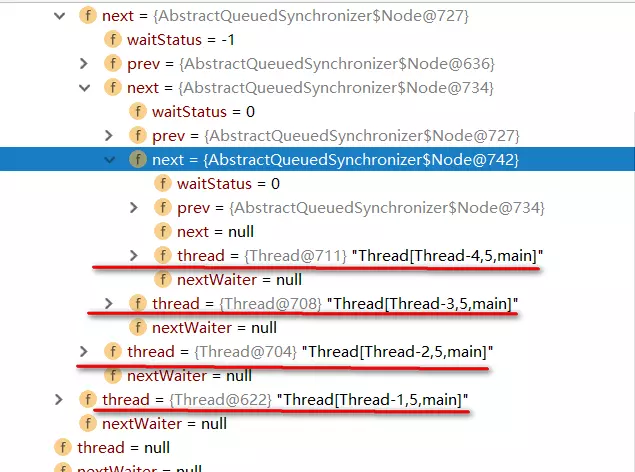
Thread-0先获得锁后进行睡眠,其他线程(Thread-1,Thread-2,Thread-3,Thread-4)获取锁失败进入同步队列,同时也可以很清楚的看出来每个节点有两个域:prev(上一个)和next(下一个),并且每个节点用来保存获取同步状态失败的线程引用以及等待状态等信息。
另外AQS中有两个重要的成员变量:
1 | private transient volatile Node head; |
也就是说AQS实际上通过头尾指针来管理同步队列,同时实现包括获取锁失败的线程进行入队,释放锁时对同步队列中的线程进行通知等核心方法。
其示意图如下: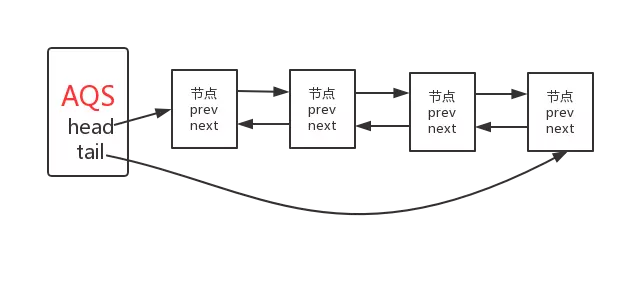
通过对源码的理解以及做实验的方式,现在我们可以清楚的知道这样几点:
- 节点的数据结构,即AQS的静态内部类Node,节点的等待状态等信息
- 同步队列是一个双向队列,AQS通过持有头尾指针管理同步队列
那么,节点如何进行入队和出队是怎样做的了?
实际上这对应着锁的获取和释放两个操作:
- 获取锁成功进行出队操作。
- 获取锁失败进行入队操作
独占锁
独占锁的获取(acquire方法)
我们继续通过看源码和debug的方式来看,还是以上面的demo为例,调用lock()方法是获取独占式锁,获取失败就将当前线程加入同步队列,成功则线程执行。
而lock()方法实际上会调用AQS的acquire()方法,源码如下
1 | public final void acquire(int arg) { |
关键信息请看注释,acquire根据当前获得同步状态成功与否做了两件事情:
- 成功,则方法结束返回
- 失败,则先调用addWaiter()然后在调用acquireQueued()方法。
获取同步状态失败,入队操作
当线程获取独占式锁失败后就会将当前线程加入同步队列,那么加入队列的方式是怎样的了?
我们接下来就应该去研究一下addWaiter()和acquireQueued()。
addWaiter()源码如下:
1 | private Node addWaiter(Node mode) { |
分析可以看上面的注释。程序的逻辑主要分为两个部分:
- 当前同步队列的尾节点为null,调用方法enq()插入;
- 当前队列的尾节点不为null,则采用尾插入(compareAndSetTail()方法)的方式入队。
另外还会有另外一个问题:如果if (compareAndSetTail(pred, node))为false怎么办?
会继续执行到enq()方法,同时很明显compareAndSetTail是一个CAS操作,通常来说如果CAS操作失败会继续自旋(死循环)进行重试。
因此,经过我们这样的分析,enq()方法可能承担两个任务:
- 处理当前同步队列尾节点为null时进行入队操作;
- 如果CAS尾插入节点失败后负责自旋进行尝试。
那么是不是真的就像我们分析的一样了?只有源码会告诉我们答案:)
enq()源码如下:
1 | private Node enq(final Node node) { |
在上面的分析中我们可以看出在第1步中会先创建头节点,说明同步队列是带头节点的链式存储结构。问1:为什么选择带头节点的链式存储结构?
因为带头节点与不带头节点相比,会在入队和出队的操作中获得更大的便捷性,因此同步队列选择了带头节点的链式存储结构。问2:那么带头节点的队列初始化时机是什么?
自然而然是在tail为null时,即当前线程是第一次插入同步队列。
compareAndSetTail(t, node)方法会利用CAS操作设置尾节点,如果CAS操作失败会在for (;;)for死循环中不断尝试,直至成功return返回为止。
因此,对enq()方法可以做这样的总结:
- 在当前线程是第一个加入同步队列时,调用compareAndSetHead(new Node())方法,完成链式队列的头节点的初始化;
- 自旋不断尝试CAS插入尾节点直至成功为止。
现在我们已经很清楚获取独占式锁失败的线程包装成Node然后插入同步队列的过程了?那么紧接着会有下一个问题?在同步队列中的节点(线程)会做什么事情了来保证自己能够有机会获得独占式锁了?
带着这样的问题我们就来看看acquireQueued()方法,从方法名就可以很清楚,这个方法的作用就是排队获取锁的过程,源码如下:
1 | final boolean acquireQueued(final Node node, int arg) { |
程序逻辑通过注释已经标出,整体来看这是一个这又是一个自旋的过程for (;;),
代码首先获取当前节点的先驱节点,如果先驱节点是头节点的并且成功获得同步状态的时候if (p == head && tryAcquire(arg)),当前节点所指向的线程能够获取锁。反之,获取锁失败设置阻塞状态。
整体示意图为下图: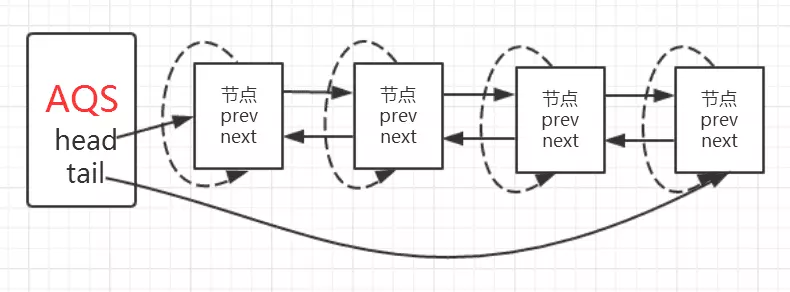
获取锁成功,出队操作
获取锁的节点出队的逻辑是:
1 | setHead(node);// 设置当前节点为头节点 |
setHead()方法为:
1 | private void setHead(Node node) { |
将当前节点通过setHead()方法设置为队列的头节点,然后将之前的头节点的next域设置为null并且pre域也为null,即与队列断开,无任何引用方便GC时能够将内存进行回收。
(设置的第一个节点为null,方便GC回收,设置当前节点为头节点,所以当前节点从第二个节点变为第一个节点,这时前面就没有节点了,所以设置prev为null)
示意图如下:
那么当获取锁失败的时候会调用shouldParkAfterFailedAcquire()方法和parkAndCheckInterrupt()方法,看看他们做了什么事情。
shouldParkAfterFailedAcquire()方法源码为:
1 | private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { |
waitStatus节点状态
waitStatus节点状态:
1 | 状态字段,只接受值: |
shouldParkAfterFailedAcquire()方法主要逻辑是使用compareAndSetWaitStatus(pred, ws, Node.SIGNAL)使用CAS将节点状态设置成SIGNAL,表示当前线程阻塞。
当compareAndSetWaitStatus设置失败,则说明shouldParkAfterFailedAcquire方法返回false,
然后会在acquireQueued()方法中for (;;)死循环中会继续重试,
直至compareAndSetWaitStatus设置节点状态为SIGNAL时并且shouldParkAfterFailedAcquire返回true时才会执行parkAndCheckInterrupt()方法,
parkAndCheckInterrupt()方法的源码为:
1 | private final boolean parkAndCheckInterrupt() { |
该方法的关键是会调用LookSupport.park()方法(关于LookSupport会在以后的文章进行讨论),该方法是用来阻塞当前线程的。
因此到这里就应该清楚了,acquireQueued()在自旋过程中主要完成了两件事情:
- 如果当前节点的上一个节点是头节点,并且能够获得同步状态的话,方法返回false,就不执行
selfInterrupt();,设置当前节点为头节点(获得锁,线程出队) - 获取锁失败的话,先将节点状态设置成SIGNAL,然后调用LookSupport.park方法使得当前线程阻塞
经过上面的分析,独占式锁的获取过程也就是acquire()方法的执行流程如下图所示: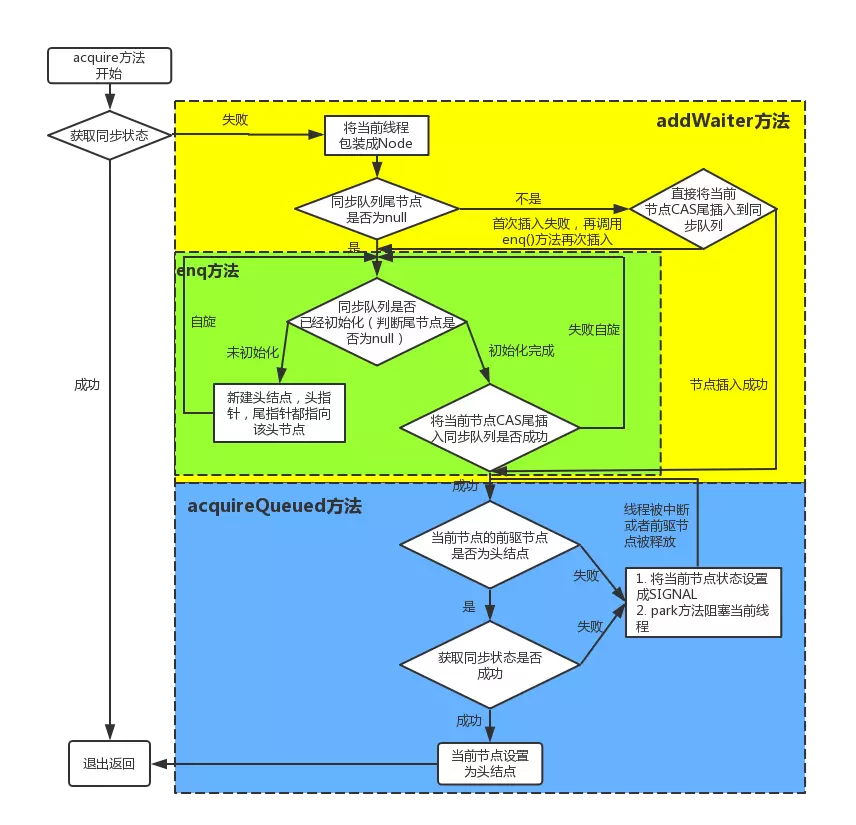
独占锁的释放(release()方法)
独占锁的释放就相对来说比较容易理解了,废话不多说先来看下源码:
1 | public final boolean release(int arg) { |
这段代码逻辑就比较容易理解了,如果同步状态释放成功(tryRelease返回true)则会执行if块中的代码,
当head指向的头节点不为null,并且该节点的状态值不为0的话才会执行unparkSuccessor()方法。
- unparkSuccessor方法源码:源码的关键信息请看注释,首先获取头节点的下一个节点,当下一个节点的时候会调用LookSupport.unpark()方法,该方法会唤醒线程(唤醒第二个节点所引用的线程)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/**
* 唤醒node(头节点)的下一个节点(如果存在的话)。
*
* @param node 节点(传入头节点)
*/
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;//获取头节点等待状态
if (ws < 0)//如果等待状态小于0,(SIGNAL(-1) CONDITION(-2) PROPAGATE(-3))
compareAndSetWaitStatus(node, ws, 0);//设置头节点等待状态为0
/*
* Thread to unpark is held in successor, which is normally just the next node. But if cancelled or apparently null, traverse backwards from tail to find the actual non-cancelled successor.
* 取消停靠的线程被保存在后续节点中,它通常只是下一个节点。但是,如果取消或显然为空,则从tail向后遍历,以找到实际的未取消后继。
*/
Node s = node.next;//获取头节点的下一个节点
if (s == null || s.waitStatus > 0) {//如果下一个节点为null,或下一个节点等待状态大于0(CANCELLED(1))
s = null;
//从尾结点向前遍历,遍历到头节点结束,s获取头节点的上一个节点,并且等待状态<=0((0) SIGNAL(-1) CONDITION(-2) PROPAGATE(-3))
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
//头节点的下一个节点不为null,唤醒这个线程
if (s != null)
LockSupport.unpark(s.thread);
}
因此,每一次锁释放后就会唤醒队列中该节点的下一个节点所引用的线程,从而可以知道获得锁的过程是一个FIFO(先进先出)的过程。
到现在我们终于啃下了一块硬骨头了,通过学习源码的方式非常深刻的学习到了独占式锁的获取和释放的过程以及同步队列。
可以做一下总结:
- 线程获取锁失败,线程被封装成Node进行入队操作,核心方法在于addWaiter()和enq(),同时enq()完成对同步队列的头节点初始化工作以及CAS操作失败的重试;
- 线程获取锁是一个自旋的过程,当且仅当 当前节点的上一个节点是头节点并且成功获得同步状态时,节点出队即该节点引用的线程获得锁,否则,当不满足条件时就会调用LookSupport.park()方法使得线程阻塞;
- 释放锁的时候会唤醒下一个节点;
总体来说:
在获取同步状态时,AQS维护一个同步队列,获取同步状态失败的线程会加入到队列中进行自旋;
移除队列(或停止自旋)的条件是上一个节点是头节点并且成功获得了同步状态。(这时就会把当前节点设置为头节点,当前线程出队)
在释放同步状态时,同步器会调用unparkSuccessor()方法唤醒下一个节点。
可中断式获取锁(acquireInterruptibly方法)
独占锁特性学习
我们知道lock相较于synchronized有一些更方便的特性,比如能响应中断以及超时等待等特性,现在我们依旧采用通过学习源码的方式来看看能够响应中断是怎么实现的。
可响应中断式锁可调用方法lock.lockInterruptibly();而该方法其底层会调用AQS的acquireInterruptibly方法,源码为:
1 | public final void acquireInterruptibly(int arg) |
在获取同步状态失败后就会调用doAcquireInterruptibly方法:
1 | private void doAcquireInterruptibly(int arg) |
关键信息请看注释,现在看这段代码就很轻松了吧:),与acquire方法逻辑几乎一致,
唯一的区别是当parkAndCheckInterrupt返回true时即线程阻塞时该线程被中断,代码抛出被中断异常。
超时等待式获取锁(tryAcquireNanos()方法)
独占锁特性学习
通过调用lock.tryLock(timeout,TimeUnit)方式达到超时等待获取锁的效果,该方法会在三种情况下才会返回:
- 在超时时间内,当前线程成功获取了锁;
- 当前线程在超时时间内被中断;
- 超时时间结束,仍未获得锁返回false。
我们仍然通过采取阅读源码的方式来学习底层具体是怎么实现的,该方法会调用AQS的方法tryAcquireNanos(),源码为:
1 | public final boolean tryAcquireNanos(int arg, long nanosTimeout) |
很显然这段源码最终是靠doAcquireNanos方法实现超时等待的效果,该方法源码如下:
1 | private boolean doAcquireNanos(int arg, long nanosTimeout) |
程序逻辑如图所示: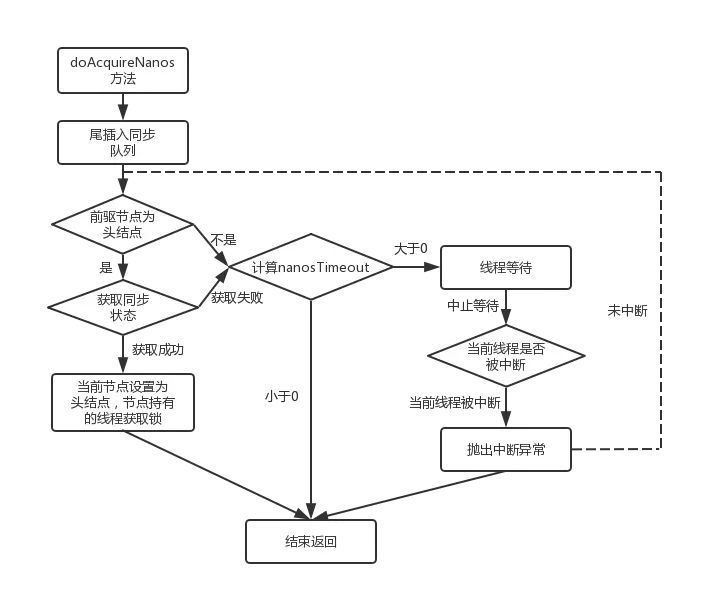
程序逻辑同独占锁可响应中断式获取基本一致,唯一的不同在于获取锁失败后,对超时时间的处理上
根据deadline = System.nanoTime() + nanosTimeout算出到期时间,然后根据deadline - System.nanoTime()判断是否超时,计算出来是一个负数,自然而然会在3.2步中的If判断之间返回false。
如果还没有超时即3.2步中的if判断为true时就会继续执行3.3步通过LockSupport.parkNanos使得当前线程阻塞,同时在3.4步增加了对中断的检测,若检测出被中断直接抛出被中断异常。
共享锁
共享锁的获取(acquireShared()方法)
在聊完AQS对独占锁的实现后,我们继续一鼓作气的来看看共享锁是怎样实现的?
共享锁的获取方法为acquireShared,源码为:
1 | public final void acquireShared(int arg) { |
这段源码的逻辑很容易理解,在该方法中会首先调用tryAcquireShared方法,tryAcquireShared返回值是一个int类型,
当返回值为大于等于0的时候方法结束说明获得成功获取锁,否则,表明获取同步状态失败即所引用的线程获取锁失败,会执行doAcquireShared方法,该方法的源码为:
1 | private void doAcquireShared(int arg) { |
现在来看这段代码会不会很容易了?逻辑几乎和独占式锁的获取一模一样,
这里的自旋过程中能够退出的条件是当前节点的上一个节点是头节点并且tryAcquireShared(arg)返回值大于等于0即能成功获得同步状态。
共享锁的释放(releaseShared()方法)
共享锁的释放在AQS中会调用方法releaseShared:
1 | public final boolean releaseShared(int arg) { |
当成功释放同步状态之后即tryReleaseShared会继续执行doReleaseShared方法:
1 | private void doReleaseShared() { |
这段方法跟独占式锁释放过程有点点不同,在共享式锁的释放过程中,对于能够支持多个线程同时访问的并发组件,必须保证多个线程能够安全的释放同步状态,
这里采用的CAS保证,当CAS操作失败continue(结束本次,执行下一次),在下一次循环中进行重试。
可中断(acquireSharedInterruptibly()方法),超时等待(tryAcquireSharedNanos()方法)
关于可中断锁以及超时等待的特性其实现和独占式锁可中断获取锁以及超时等待的实现几乎一致,具体的就不再说了,如果理解了上面的内容对这部分的理解也是水到渠成的。
通过这篇,加深了对AQS的底层实现更加清楚了,也对了解并发组件的实现原理打下了基础。
彻底理解ReentrantLock
ReentrantLock的介绍
ReentrantLock重入锁,是实现Lock接口的一个类,也是在实际编程中使用频率很高的一个锁,支持重入性,表示能够对共享资源能够重复加锁,即当前线程获取该锁再次获取不会被阻塞。
在java关键字synchronized隐式支持重入性(关于synchronized可以看这篇文章),synchronized通过获取自增,释放自减的方式实现重入。(每个对象拥有一个计数器,当线程获取该对象锁后,计数器就会加一,释放锁后就会将计数器减一)
并且,ReentrantLock还支持公平锁和非公平锁两种方式。
那么,要想完完全全的弄懂ReentrantLock的话,主要也就是ReentrantLock同步语义的学习:
- 重入性的实现原理
- 公平锁和非公平锁
重入性的实现原理
要想支持重入性,就要解决两个问题:
获取在线程获取锁的时候,如果已经获取锁的线程是当前线程的话则直接再次获取成功释放由于锁会被获取n次,那么只有锁在被释放同样的n次之后,该锁才算是完全释放成功。
通过这篇文章我们知道,同步组件主要是通过重写AQS的几个protected方法来表达自己的同步语义。
针对第一个问题获取,我们来看看ReentrantLock是怎样实现的,以非公平锁为例,判断当前线程能否获得锁为例,核心方法为nonfairTryAcquire:
1 | final boolean nonfairTryAcquire(int acquires) { |
这段代码的逻辑也很简单,具体请看注释。
为了支持重入性,在第二步增加了处理逻辑,如果该锁已经被线程所占有了,会继续检查占有线程是否为当前线程,如果是的话,同步状态加1返回true,表示可以再次获取成功。
每次重新获取都会对同步状态进行加一的操作,那么释放的时候处理思路是怎样的了?
依然还是以非公平锁为例,核心方法为tryRelease:
1 | protected final boolean tryRelease(int releases) { |
代码的逻辑请看注释,需要注意的是,重入锁的释放必须得等到同步状态为0时锁才算成功释放,否则锁仍未释放。
也就是说,如果锁被获取n次,释放了n-1次,该锁未完全释放返回false,只有被释放n次才算成功释放,返回true。
到现在我们可以理清ReentrantLock重入性的实现了,也就是理解了同步语义的第一条。
公平锁与非公平锁
ReentrantLock支持两种锁:公平锁和非公平锁。
所谓公平性,是针对获取锁来说的,如果一个锁是公平的,那么锁的获取顺序就应该符合请求上的绝对时间顺序,满足FIFO(First In First Out先进先出)。
ReentrantLock的构造方法无参时是构造非公平锁,源码为:
1 | /** |
另外还提供了另外一种方式,可传入一个boolean值,true时为公平锁,false时为非公平锁,源码为:
1 | /** |
在上面非公平锁获取时(nonfairTryAcquire方法)只是简单的获取了一下当前状态做了一些逻辑处理,并没有考虑到当前同步队列中线程等待的情况。
我们来看看公平锁的处理逻辑是怎样的,核心方法为:
1 | /** |
1 | public final boolean hasQueuedPredecessors() { |
这段代码的逻辑与nonfairTryAcquire基本上一致,唯一的不同在于增加了hasQueuedPredecessors的逻辑判断,方法名就可知道该方法用来判断当前节点在同步队列中是否有上一个节点,
如果有上一个节点说明有线程比当前线程更早的请求资源(比当前线程先执行),根据公平性,当前线程请求资源(获取锁)失败。
如果当前节点没有上一个节点的话,再才有做后面的逻辑判断的必要性。
公平锁每次都是从同步队列中的第一个节点获取到锁,而非公平性锁则不一定,有可能刚释放锁的线程能再次获取到锁。
公平锁 VS 非公平锁
- 公平锁每次获取到锁为同步队列中的第一个节点,保证请求资源时间上的绝对顺序(保证获取锁的绝对顺序),
而非公平锁有可能刚释放锁的线程下次继续获取该锁,则有可能导致其他线程永远无法获取到锁,造成“饥饿”现象。 - 公平锁为了保证时间上的绝对顺序(公平锁为了保证获取锁的绝对顺序),需要频繁的上下文切换,而非公平锁会降低一定的上下文切换,降低性能开销。
因此,ReentrantLock默认选择的是非公平锁,则是为了减少一部分上下文切换,保证了系统更大的吞吐量。
JUC AQS ReentrantLock源码分析
https://www.bilibili.com/read/cv4020427这时我看的写得非常好的文章了
Java的内置锁一直都是备受争议的,在JDK1.6之前,synchronized这个重量级锁其性能一直都是较为低下,
虽然在1.6后,进行大量的锁优化策略,但是与Lock相比synchronized还是存在一些缺陷的:虽然synchronized提供了便捷性的隐式获取锁释放锁机制(基于JVM机制),但是它却缺少了获取锁与释放锁的可操作性,可中断、超时获取锁,且它为独占式在高并发场景下性能大打折扣。
如何自己来实现一个同步
自旋实现一个同步
- 缺点:耗费cpu资源。没有竞争到锁的线程会一直占用cpu资源进行cas操作,假如一个线程获得锁后要花费Ns处理业务逻辑,那另外一个线程就会白白的花费Ns的cpu资源
- 解决思路:让得不到锁的线程让出CPU
yield+自旋实现同步

要解决自旋锁的性能问题必须让竞争锁失败的线程不空转,而是在获取不到锁的时候能把cpu资源给让出来,
yield()方法就能让出cpu资源,当线程竞争锁失败时,会调用yield方法让出cpu。
自旋+yield的方式并没有完全解决问题,当系统只有两个线程竞争锁时,yield是有效的。
需要注意的是该方法只是当前让出cpu,有可能操作系统下次还是选择运行该线程,比如里面有2000个线程,想想会有什么问题?
sleep+自旋方式实现同步

- 缺点:sleep的时间为什么是10?怎么控制呢?很多时候就算你是调用者本身其实你也不知道这个时间是多少
park+自旋方式实现同步
这种方法就比较完美,当然我写的都伪代码,我看看大师是如何利用这种机制来实现同步的;JDK的JUC包下面ReentrantLock类的原理就是利用了这种机制;
ReentrantLock源码分析之上锁过程
AQS(AbstractQueuedSynchronizer)类的设计主要代码(具体参考源码)

- AQS当中的队列示意图
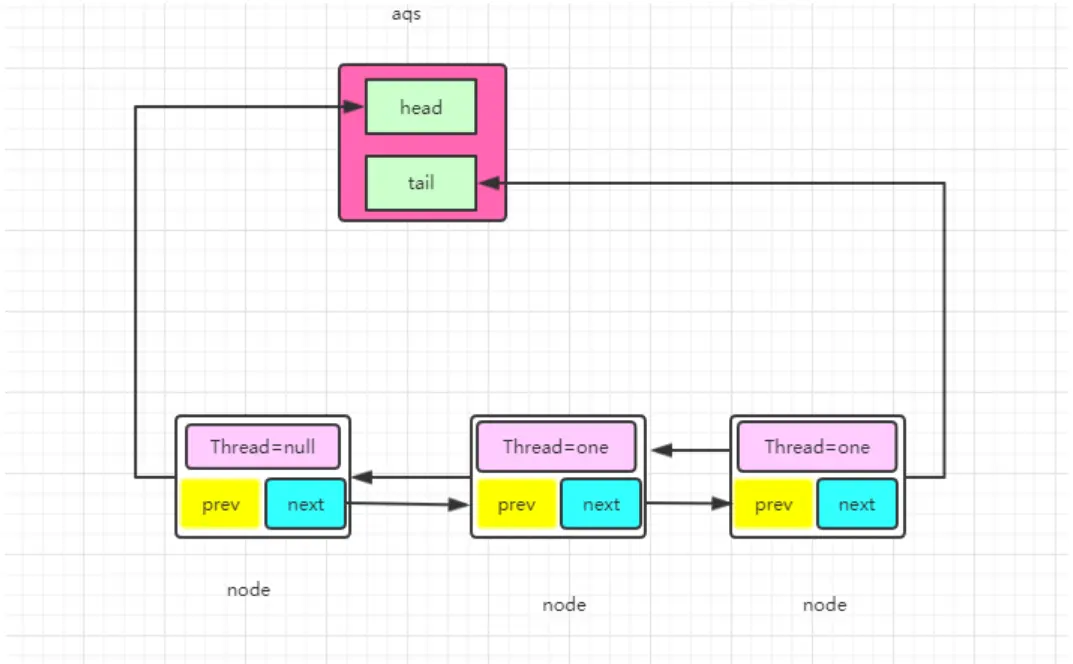
Node类的设计

上锁过程重点
- 锁对象:其实就是ReentrantLock的实例对象,下文应用代码第一行中的lock对象就是所谓的锁
- 自由状态:自由状态表示锁对象没有被别的线程持有,计数器为0
- 计数器:再lock对象中有一个字段state用来记录上锁次数,比如lock对象是自由状态则state为0,如果大于零则表示被线程持有了,当然也有重入那么state则>1
- 节点:就是上面的Node类的对象,里面封装了线程,所以某种意义上node就等于一个线程
- waitStatus:仅仅是一个状态而已;ws是一个过渡状态,在不同方法里面判断ws的状态做不同的处理,所以ws=0有其存在的必要性
- tail:队列的队尾
- head:队列的对首
- ts:第二个给lock加锁的线程
- tf:第一个给lock加锁的线程
- tc:当前给线程加锁的线程
- tl:最后一个加锁的线程
- tn:随便某个线程
当然这些线程有可能重复,比如第一次加锁的时候tf=tc=tl=tn
首先一个简单的应用
公平锁lock方法的源码分析

非公平锁的looc方法

- 下面给出他们的代码执行逻辑的区别图
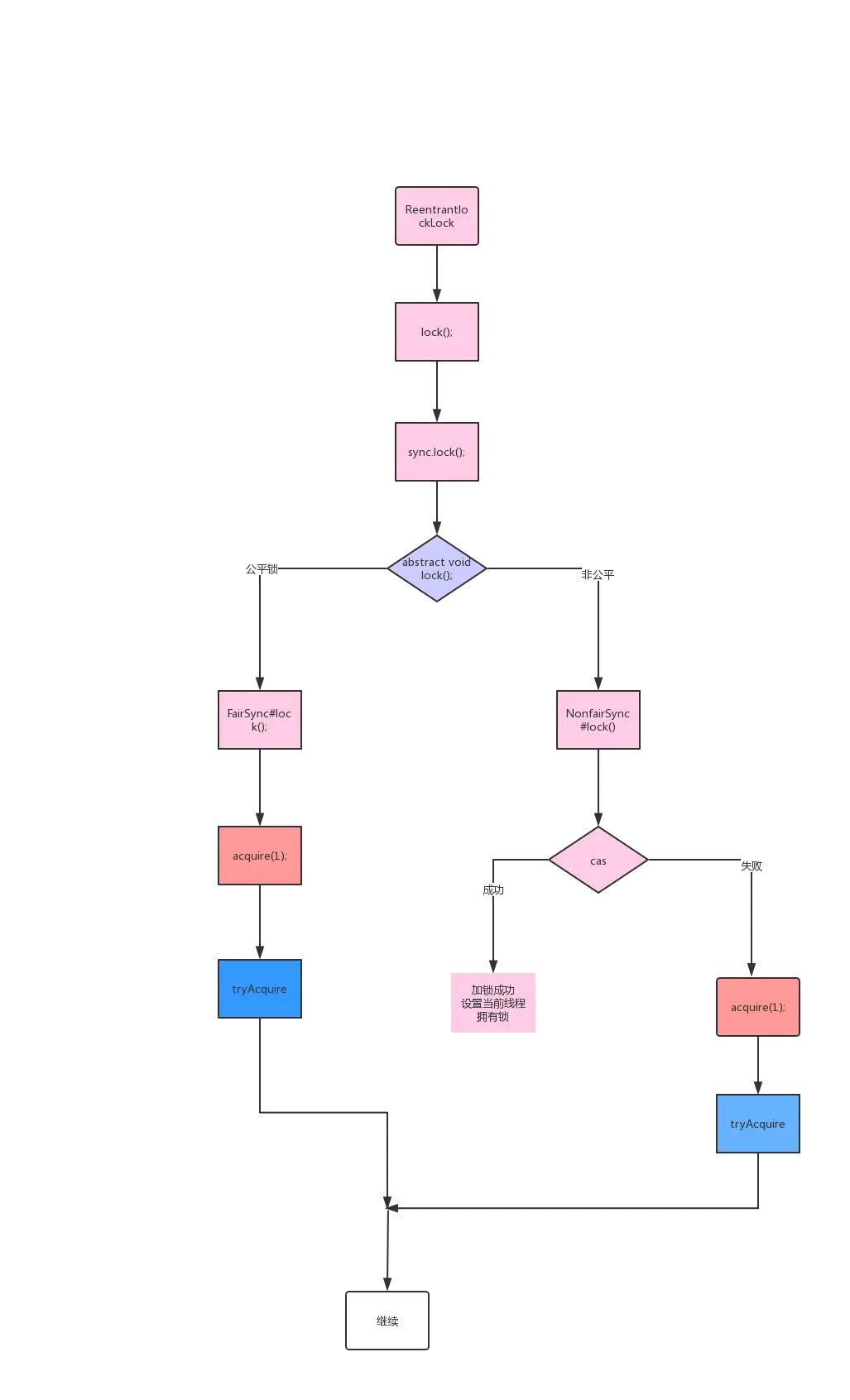
公平锁的上锁是必须判断自己是不是需要排队;而非公平锁是直接进行CAS修改计数器看能不能加锁成功;
如果加锁不成功则乖乖排队(调用acquire);所以不管公平还是不公平;只要进到了AQS队列当中那么他就会排队;一朝排队;永远排队记住这点
acquire方法方法源码分析
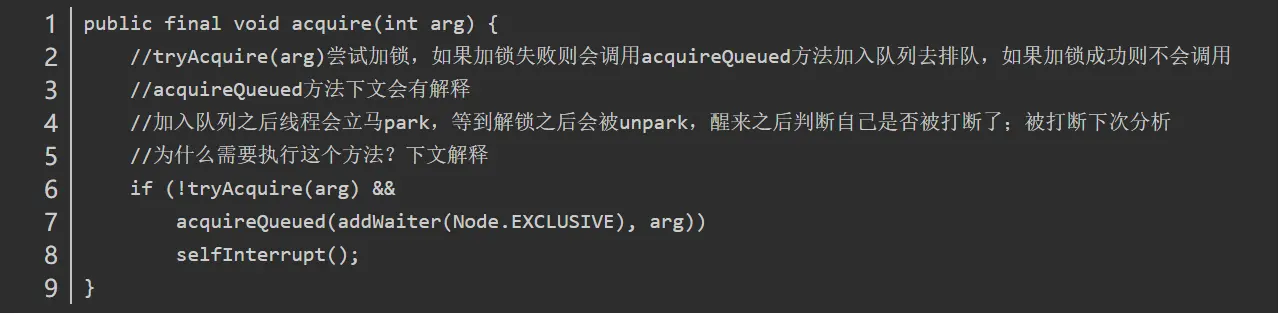
acquire方法首先会调用tryAcquire方法,注意tryAcquire的结果做了取反
tryAcquire方法源码分析
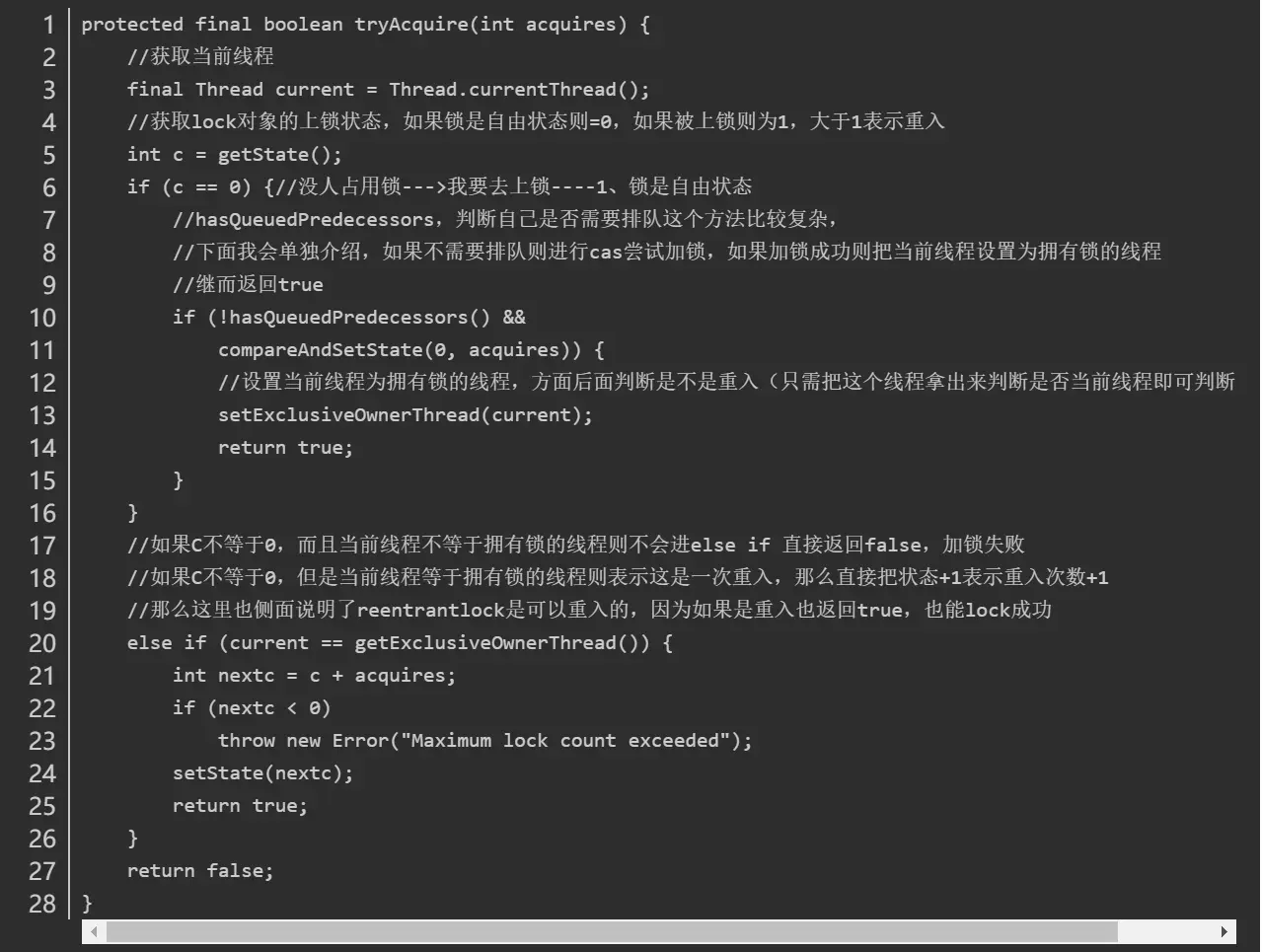
hasQueuedPredecessors判断是否需要排队的源码分析
这里需要记住一点,整个方法如果最后返回false,则去加锁,如果返回true则不加锁,因为这个方法被取反了

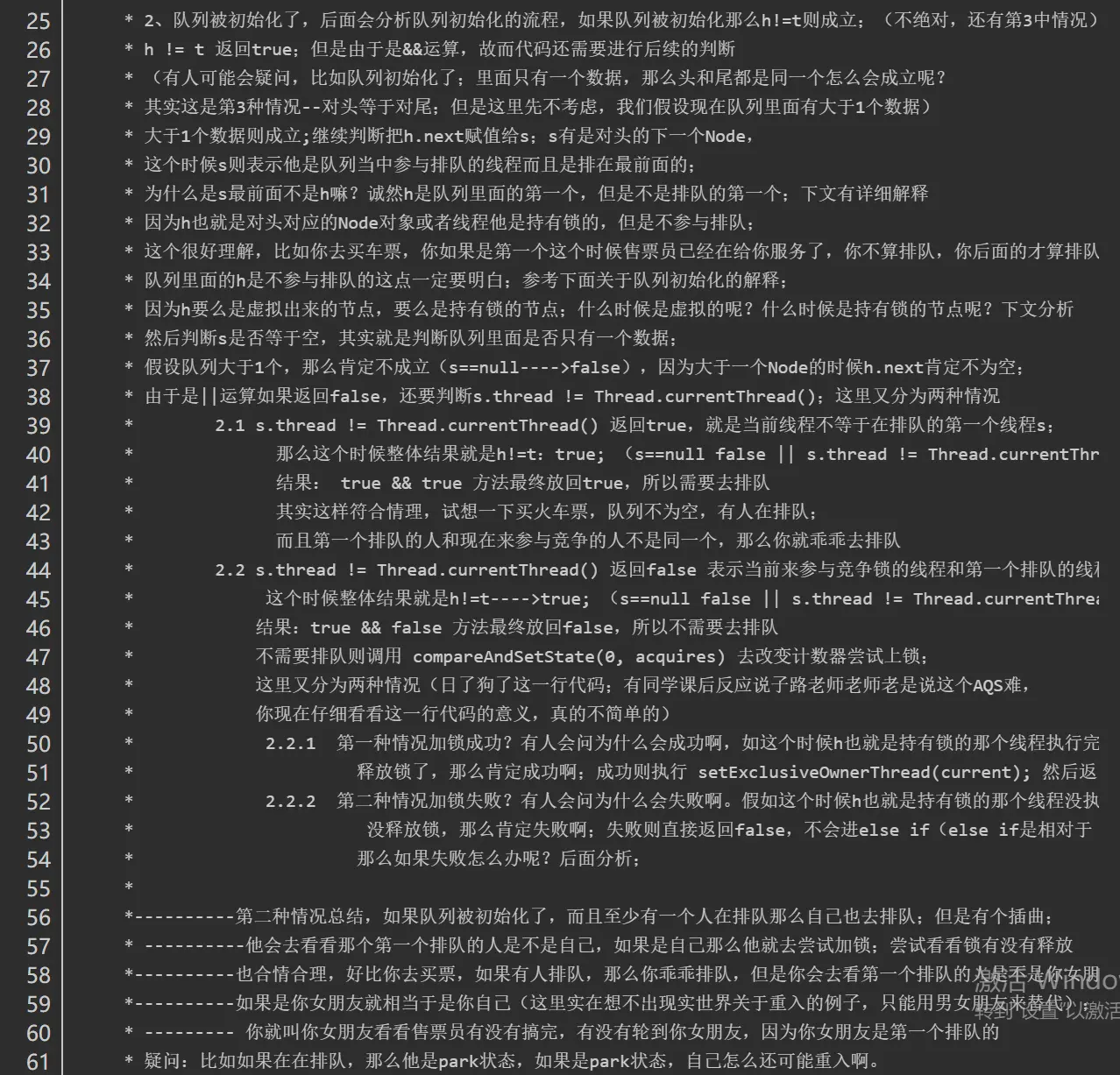
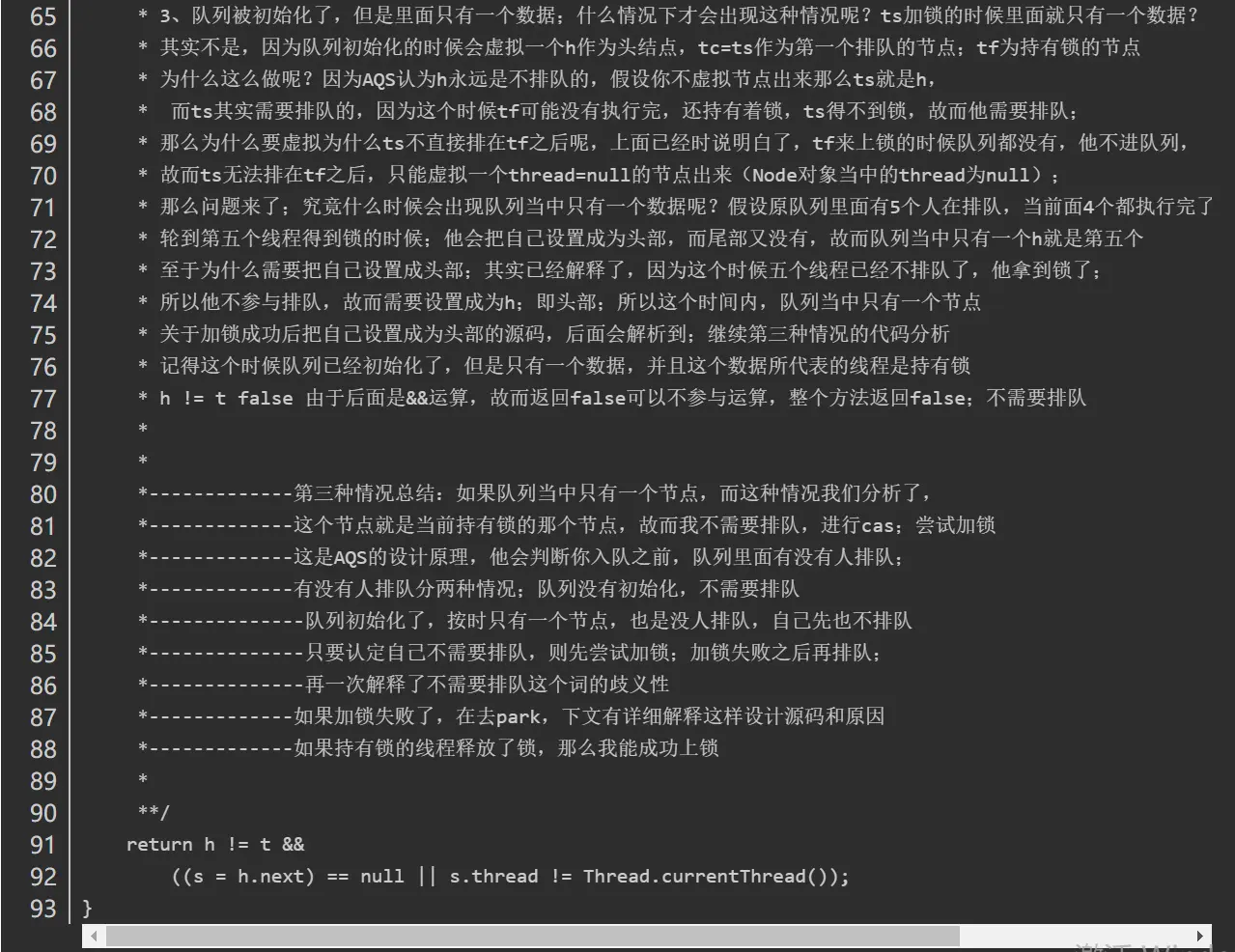
我理解为那个方法直接返回
{(头!=尾)and(头.下一个节点==null or 头.下一个节点的线程!=当前线程)}
这个大括号的意义上也很简单,也就是当前队列是不是有两个节点(除了自己),如果=2就返回true,否则false`
到此我们已经解释完了!tryAcquire(arg)方法,为了方便我再次贴一下代码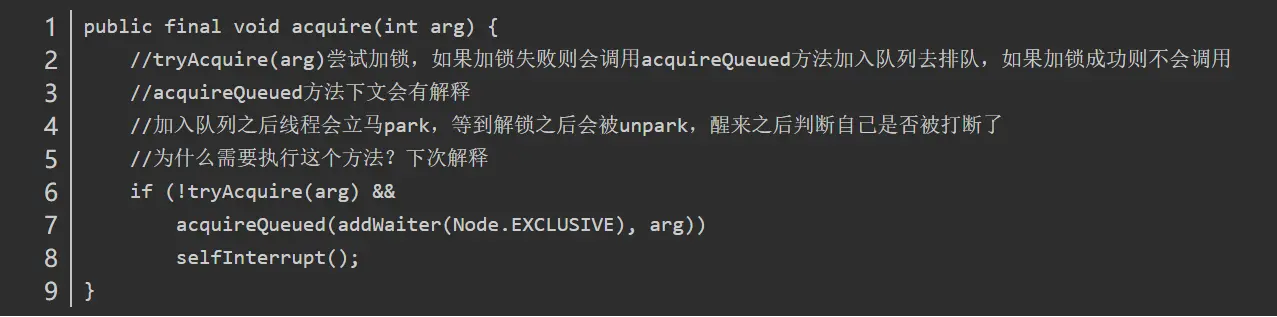
acquireQueued(addWaiter(Node.exclusive),arg))方法解析
如果代码能执行到这里说tc需要排队
需要排队有两种情况—换言之代码能够执行到这里有两种情况:
- tf持有了锁,并没有释放,所以tc来加锁的时候需要排队,但这个时候—队列并没有初始化
- tn(无所谓哪个线程,反正就是一个线程)持有了锁,那么由于加锁tn!=tf(tf是属于第一种情况,我们现在不考虑tf了),所以队列是一定被初始化了的,tc来加锁,那么队列当中有人在排队,故而他也去排队
加锁过程总结
如果是第一个线程tf,那么和队列无关,线程直接持有锁。并且也不会初始化队列,如果接下来的线程都是交替执行,那么永远和AQS队列无关,都是直接线程持有锁,
如果发生了竞争,比如tf持有锁的过程中T2来lock,那么这个时候就会初始化AQS,初始化AQS的时候会在队列的头部虚拟一个Thread为NULL的Node,
因为队列当中的head永远是持有锁的那个node(除了第一次会虚拟一个,其他时候都是持有锁的那个线程锁封装的node),现在第一次的时候持有锁的是tf而tf不在队列当中所以虚拟了一个node节点,
队列当中的除了head之外的所有的node都在park,当tf释放锁之后unpark某个(基本是队列当中的第二个,为什么是第二个呢?前面说过head永远是持有锁的那个node,当有时候也不会是第二个,比如第二个被cancel之后,至于为什么会被cancel,不在我们讨论范围之内,cancel的条件很苛刻,基本不会发生)node之后,node被唤醒,假设node是t2,那么这个时候会首先把t2变成head(sethead),在sethead方法里面会把t2代表的node设置为head,并且把node的Thread设置为null,
为什么需要设置null?其实原因很简单,现在t2已经拿到锁了,node就不要排队了,那么node对Thread的引用就没有意义了。所以队列的head里面的Thread永远为null
深入理解读写锁ReentrantReadWriteLock
在并发场景中用于解决线程安全的问题,我们几乎会高频率的使用到独占式锁,
通常使用java提供的关键字synchronized或concurrents包中实现了Lock接口ReentrantLock。
它们都是独占式获取锁,也就是在同一时刻只有一个线程能够获取锁。
而在一些业务场景中,大部分只是读数据,写数据很少,如果仅仅是读数据的话并不会影响数据正确性(出现脏读),而如果在这种业务场景下,依然使用独占锁的话,很显然这将是出现性能瓶颈的地方。
针对这种读多写少的情况,java还提供了另外一个实现Lock接口的ReentrantReadWriteLock(读写锁)。
读写所允许同一时刻被多个读线程访问; 但是在写线程访问时,所有的读线程和其他的写线程都会被阻塞。
在分析WirteLock和ReadLock的互斥性时可以按照WriteLock与WriteLock之间,WriteLock与ReadLock之间以及ReadLock与ReadLock之间进行分析。
更多关于读写锁特性介绍大家可以看源码上的介绍(阅读源码时最好的一种学习方式,我也正在学习中,与大家共勉),这里做一个归纳总结:
公平性选择:支持非公平性(默认)和公平的锁获取方式,吞吐量还是非公平优于公平;重入性:支持重入,读锁获取后能再次获取; 写锁获取之后能够再次获取写锁,同时也能够获取读锁;锁降级:遵循获取写锁,获取读锁再释放写锁的次序,写锁能够降级成为读锁
要想能够彻底的理解读写锁必须能够理解这样几个问题:
- 读写锁是怎样实现分别记录读写状态的?
- 写锁是怎样获取和释放的?
- 读锁是怎样获取和释放的?
我们带着这样的三个问题,再去了解下读写锁。
三步分析
1)、ReadWriteLock readWriteLock=new ReentrantReadWriteLock();
其内部还是由AQS的共享锁和独占锁进行维护
1 | public ReentrantReadWriteLock() { |
2)、读锁 -> 共享锁
获取读锁readWriteLock.readLock().lock();
释放读锁readWriteLock.readLock().unlock();
1 | public void lock() { |
3)、写锁 -> 独占锁
获取写锁readWriteLock.writeLock().lock();
释放写锁readWriteLock.writeLock().unlock();
1 | public void lock() { |
问题演示&解决
1 |
写锁
写锁的获取
例如ReentrantLock就是一个同步组件
同步组件的实现聚合了同步器(AQS),并通过重写重写同步器(AQS)中的方法实现同步组件的同步语义(关于同步组件的实现层级结构可以看初识Lock与AbstractQueuedSynchronizer(AQS),AQS的底层实现分析可以看深入理解AbstractQueuedSynchronizer(AQS))。
因此,写锁的实现依然也是采用这种方式。
在同一时刻写锁是不能被多个线程所获取,很显然写锁是独占式锁,而实现写锁的同步语义是通过重写AQS中的tryAcquire方法实现的。
- 源码为:这段代码的逻辑请看注释,这里有一个地方需要重点关注,exclusiveCount(c)方法,该方法源码为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
Thread current = Thread.currentThread();
//1. 获取写锁当前的同步状态
int c = getState();
//2. 获取写锁获取的次数
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
//3.1 当读锁已被读线程获取,或当前线程不是已经获取写锁的线程的话
// 当前线程获取写锁失败
if (w == 0 || current != getExclusiveOwnerThread())
return false;
// 大于最大上锁次数,抛异常
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
//3.2 当前线程获取写锁,支持可重复加锁
setState(c + acquires);
return true;
}
//3.3 写锁未被任何线程获取,当前线程可获取写锁
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
// 设置独占模式的执行线程为当前线程
setExclusiveOwnerThread(current);
return true;
}根据上面可知,同步状态的低16位用来表示写锁的获取次数,1
2
3
4
5
6static final int SHARED_SHIFT = 16;
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;//1右移16位再减1的二进制:00000000 00000000 11111111 11111111=2^16-1=65535
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;//与MAX_COUNT相同
/** Returns the number of exclusive holds represented in count */
/** 返回值表示的独占式获取锁(写锁)的次数 */
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK; }//如果c<=65535,即小于MAX_COUNT,就返回本身该方法是获取读锁被获取的次数,是将同步状态(int c)右移16次,即取同步状态的高16位,1
2
3static final int SHARED_UNIT = (1 << SHARED_SHIFT);//读锁,转换为二进制:00000000 00000001 00000000 00000000=2^16=65536
/** 返回值表示的共享式获取锁(读锁)的次数 */
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
现在我们可以得出另外一个结论同步状态的高16位用来表示读锁的获取次数。
现在还记得我们开篇说的需要弄懂的第一个问题吗?读写锁是怎样实现分别记录读锁和写锁的状态的,现在这个问题的答案就已经被我们弄清楚了,其示意图如下图所示: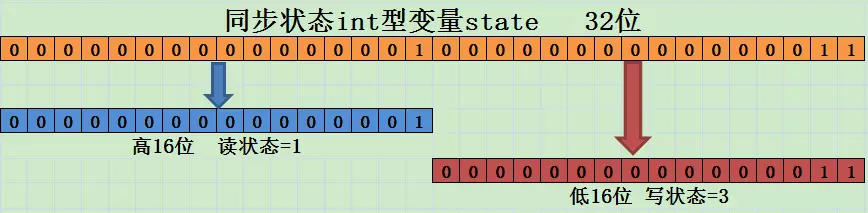
现在我们回过头来看写锁获取方法tryAcquire,其主要逻辑为:
当读锁已经被读线程获取或者写锁已经被其他写线程获取,则写锁获取失败;否则,获取成功并支持重入,增加写状态。
写锁的释放
1 | /* |
1 | protected final boolean isHeldExclusively() { |
源码的实现逻辑请看注释,不难理解与ReentrantLock基本一致,
这里需要注意的是,减少写状态int nextc = getState() - releases;只需要用当前同步状态直接减去写状态的原因正是我们刚才所说的写状态是由同步状态的低16位表示的。
读锁
读锁的获取
看完了写锁,现在来看看读锁,读锁不是独占式锁,即同一时刻该锁可以被多个读线程获取也就是一种共享式锁。
按照之前对AQS介绍,实现共享式同步组件的同步语义需要通过重写AQS的tryAcquireShared方法和tryReleaseShared方法。
读锁的获取实现方法为:
1 | protected final int tryAcquireShared(int unused) { |
1 | final int getReadHoldCount() { |
代码的逻辑请看注释,需要注意的是当写锁被其他线程获取后,读锁获取失败,否则获取成功利用CAS更新同步状态。
另外,当前同步状态需要加上SHARED_UNIT(最高16位,读锁被获取的次数)
如果CAS失败或者已经获取读锁的线程再次获取读锁时,是靠fullTryAcquireShared方法实现的,这段代码就不展开说了,有兴趣可以看看。
读锁的释放
1 | protected final boolean tryReleaseShared(int unused) { |
锁降级
读写锁支持锁降级,遵循按照获取写锁,获取读锁再释放写锁的次序,写锁能够降级成为读锁,
不支持锁升级,关于锁降级下面的示例代码摘自ReentrantWriteReadLock源码中:
1 | void processCachedData() { |
详解Condition的await等待和signal通知机制
Condition简介
任何一个java对象都天然继承于Object类,在线程间实现通信的往往会应用到Object的几个方法,
比如wait(),wait(long timeout),wait(long timeout, int nanos)与notify(),notifyAll()几个方法实现等待/通知机制
同样的, 在java Lock体系下依然会有同样的方法实现等待/通知机制。
从整体上来看
Object的wait和notify/notify是与对象监视器配合完成线程间的等待/通知机制,是java底层级别的,
而Condition与Lock配合完成等待通知机制,是语言级别的,具有更高的可控制性和扩展性。
两者除了在使用方式上不同外,在功能特性上还是有很多的不同:
- Condition能够支持不响应中断,而通过使用Object方式不支持;
- Condition能够支持多个等待队列(new 多个Condition对象),而Object方式只能支持一个;
- Condition能够支持超时时间的设置,而Object不支持
参照Object的wait和notify/notifyAll方法,Condition也提供了同样的方法:
针对Object的wait方法
void await() throws InterruptedException当前线程进入等待状态,如果其他线程调用condition的signal或者signalAll方法并且当前线程获取Lock从await方法返回,如果在等待状态中被中断会抛出被中断异常;long awaitNanos(long nanosTimeout)当前线程进入等待状态直到被通知,中断或者超时;boolean await(long time, TimeUnit unit)throws InterruptedException同第二种,支持自定义时间单位boolean awaitUntil(Date deadline) throws InterruptedException当前线程进入等待状态直到被通知,中断或者到了某个时间
针对Object的notify/notifyAll方法
void signal()唤醒一个等待在condition上的线程,将该线程从等待队列中转移到同步队列中,如果在同步队列中能够竞争到Lock则可以从等待方法中返回。void signalAll()与1的区别在于能够唤醒所有等待在condition上的线程
Condition实现原理分析
等待队列
要想能够深入的掌握condition还是应该知道它的实现原理,现在我们一起来看看condiiton的源码。
创建一个condition对象是通过lock.newCondition(),而这个方法实际上是会new出一个ConditionObject对象,该类是AQS的一个内部类深入理解AQS,有兴趣可以去看看。
前面我们说过,condition是要和lock配合使用的也就是condition和Lock是绑定在一起的,而lock的实现原理又依赖于AQS,自然而然ConditionObject作为AQS的一个内部类无可厚非。
我们知道在锁机制的实现上,AQS内部维护了一个同步队列,如果是独占式锁的话,所有获取锁失败的线程的尾插入到同步队列,
同样的,condition内部也是使用同样的方式,内部维护了一个等待队列,所有调用condition.await方法的线程会加入到等待队列中,并且线程状态转换为等待状态。
另外注意到ConditionObject中有两个成员变量:
1 | /** First node of condition queue. */ |
这样我们就可以看出来ConditionObject通过持有等待队列的头尾指针来管理等待队列。
主要注意的是Node类复用了在AQS中的Node类,其节点状态和相关属性可以去看AQS的实现原理深入理解AQS,
如果您仔细看完这篇文章对condition的理解易如反掌,对lock体系的实现也会有一个质的提升。
Node类有这样一个属性:
1 | // 下一个等待节点 |
进一步说明,等待队列是一个单向队列(只有下一个等待节点nextWaiter),而在之前说AQS时知道同步队列是一个双向队列(有prev和next两个节点属性)。
接下来我们用一个demo,通过debug进去看是不是符合我们的猜想:
1 | public static void main(String[] args) { |
这段代码没有任何实际意义,只是想说明下我们刚才所想的。
新建了10个线程,没有线程先获取锁,然后调用condition.await方法释放锁将当前线程加入到等待队列中,
通过debug控制当走到第10个线程的时候查看firstWaiter即等待队列中的头结点,debug模式下情景图如下: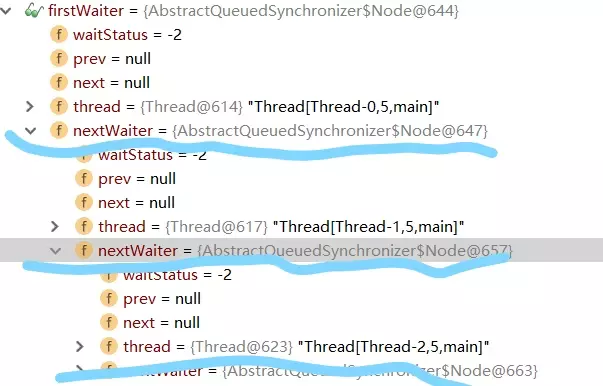
从这个图我们可以很清楚的看到这样几点:
- 调用condition.await方法后线程依次尾插入到等待队列中,如图队列中的线程引用依次为Thread-0,Thread-1,Thread-2….Thread-8;
- 等待队列是一个单向队列。
通过我们的猜想然后进行实验验证,我们可以得出等待队列的示意图如下图所示:
同时还有一点需要注意的是:我们可以多次调用lock.newCondition()方法创建多个condition对象,也就是一个lock可以持有多个等待队列。
而在之前利用Object的方式实际上是指在对象Object对象监视器上只能拥有一个同步队列和一个等待队列,而并发包中的Lock拥有一个同步队列和多个等待队列。
示意图如下:
如图所示,ConditionObject是AQS的内部类,因此每个ConditionObject能够访问到AQS提供的方法,相当于每个Condition都拥有所属同步器的引用。
await实现原理
当调用condition.await()方法后会使得当前获取lock的线程进入到等待队列,如果该线程能够从await()方法返回的话一定是该线程获取了与condition相关联的lock。
接下来,我们还是从源码的角度去看,只有熟悉了源码的逻辑我们的理解才是最深的。
await()方法源码为:
1 | public final void await() throws InterruptedException { |
这个方法里面还使用了其他方法,我们下面会慢慢道来.
代码的主要逻辑请看注释,我们都知道当当前线程调用condition.await()方法后,会使得当前线程释放lock然后加入到等待队列中,直至被signal/signalAll后会使得当前线程从等待队列中移至到同步队列中去,直到获得了lock后才会从await方法返回,或者在等待时被中断会做中断处理。
那么关于这个实现过程我们会有这样几个问题:
- 是怎样将当前线程添加到等待队列中去的?
- 释放锁的过程?
- 怎样才能从await方法退出?
而这段代码的逻辑就是告诉我们这三个问题的答案。
具体请看注释,在第1步中调用addConditionWaiter方法将当前线程添加到等待队列中,该方法源码为:
1 | private Node addConditionWaiter() { |
这段代码就很容易理解了,将当前节点包装成Node,如果等待队列的lastWaiter为null的话(等待队列为空队列),则将firstWaiter指向当前的Node,
如果lastWaiter不为null,在尾插入当前Node,最后把lastWaiter(尾结点)指向当前Node.
就是通过尾插入的方式将当前线程封装的Node插入到等待队列中即可,同时可以看出等待队列是一个不带头结点的链式队列,
之前我们学习AQS时知道同步队列是一个带头结点的链式队列,这是两者的一个区别。
将当前节点插入到等待对列之后,会使当前线程释放lock,由fullyRelease方法实现,fullyRelease源码为:
1 | final int fullyRelease(Node node) { |
这段代码调用AQS的模板方法release方法释放AQS的同步状态并且唤醒在同步队列中头结点的后继节点引用的线程,
如果释放成功则正常返回,并设置等待状态为CANCELLED,表示从等待队列中移除,若失败的话就抛出异常。
到目前为止,addConditionWaiter方法与fullyRelease方法已经解决了前面的两个问题的答案了,还剩下第三个问题,怎样从await方法退出?
现在回过头再来看await方法有这样一段逻辑:
1 | while (!isOnSyncQueue(node)) { |
很显然,当线程第一次调用condition.await()方法时,会进入到这个while()循环中,
然后通过LockSupport.park(this)方法使得当前线程进入等待状态,
那么要想退出这个await方法第一个前提条件自然而然的是要先退出这个while循环,出口就只剩下两个地方:
- 逻辑走到break退出while循环;
- 当前等待的线程被中断后代码会走到break退出
- while循环中的逻辑判断为false。
- 当前节点被移动到了同步队列中(即其他线程调用的condition的signal或者signalAll方法),while中逻辑判断为false后结束while循环
总结下,就是当前线程被中断或者调用condition.signal/condition.signalAll方法当前节点移动到了同步队列后 ,这是当前线程退出await方法的前提条件。
当退出while循环后就会调用acquireQueued(node, savedState),这个方法在介绍AQS的底层实现时说过了深入理解AQS ,
该方法的作用是在自旋过程中线程不断尝试获取同步状态,直至成功(线程获取到lock)。这样也说明了退出await方法必须是已经获得了condition引用(关联)的lock。
到目前为止,开头的三个问题我们通过阅读源码的方式已经完全找到了答案,也对await方法的理解加深。
await方法示意图如下图: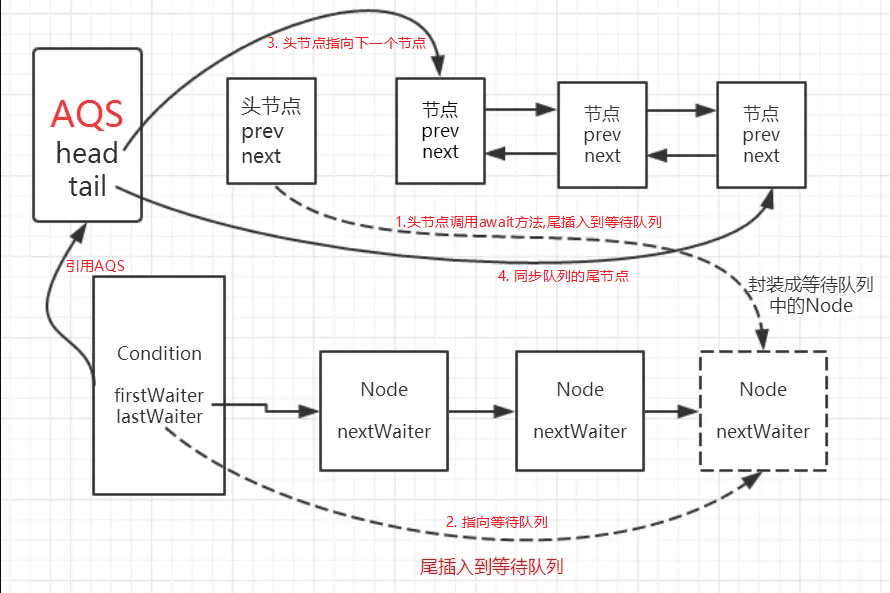
如图,其序号不代表执行顺序,调用condition.await方法的线程必须是已经获得了lock,也就是当前线程是同步队列中的头节点。
调用该方法后会使得当前线程所封装的Node尾插入到等待队列中。
超时机制的支持
condition还额外支持了超时机制,使用者可调用方法awaitNanos,awaitUtil。
这两个方法的实现原理,可以参考超时等待式获取锁
不响应中断的支持
要想不响应中断可以调用condition.awaitUninterruptibly()方法,该方法的源码为:
1 | public final void awaitUninterruptibly() { |
这段方法与上面的await方法基本一致,只不过减少了对中断的处理,并省略了reportInterruptAfterWait方法抛被中断的异常。
signal/signalAll实现原理
调用condition的signal或者signalAll方法可以将等待队列中等待时间最长的节点(头节点)移动到同步队列中,使得该节点能够有机会获得lock。
按照等待队列是FIFO(先进先出)的,所以等待队列的头节点必然会是等待时间最长的节点,也就是每次调用condition的signal方法是将头节点移动到同步队列中。
我们来通过看源码的方式来看这样的猜想是不是对的,signal方法源码为:
1 | public final void signal() { |
signal方法首先会检测当前线程是否已经获取lock,如果没有获取lock会直接抛出异常,
如果获取的话再得到等待队列的头指针引用的节点,之后的操作的doSignal方法也是基于该节点。
下面我们来看看doSignal方法做了些什么事情,doSignal方法源码为:
1 | private void doSignal(Node first) { |
具体逻辑请看注释,真正对头节点做处理的逻辑在transferForSignal方法,该方法源码为:
1 | final boolean transferForSignal(Node node) { |
关键逻辑请看注释,这段代码主要做了两件事情
- 将头结点的状态更改为CONDITION(更新为0失败);
- 调用enq方法,将该节点尾插入到同步队列中,关于enq方法请看获取同步状态 enq方法。
现在我们可以得出结论:
调用condition的signal的前提条件是当前线程已经获取了lock,该方法会使得等待队列中的头节点即等待时间最长的那个节点移入到同步队列,
而移入到同步队列后才有机会使得等待线程被唤醒,即从await方法中的LockSupport.park(this)方法中返回,从而才有机会使得调用await方法的线程成功退出。
signal执行示意图如下图: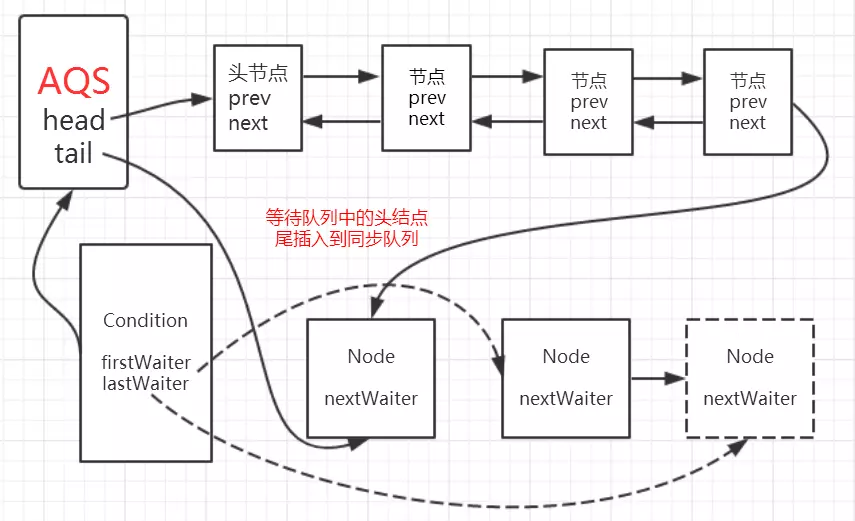
signalAll
sigllAll与sigal方法的区别体现在doSignalAll方法上,
前面我们已经知道doSignal方法只会对等待队列的头节点进行操作,而doSignalAll的源码为:
1 | private void doSignalAll(Node first) { |
该方法只不过时间等待队列中的每一个节点都移入到同步队列中,即“通知”当前调用condition.await()方法的每一个线程。
await与signal/signalAll的结合思考
文章开篇提到等待/通知机制,通过使用condition提供的await和signal/signalAll方法就可以实现这种机制,
而这种机制能够解决最经典的问题就是“生产者与消费者问题”,关于“生产者消费者问题”之后会用单独的一篇文章进行讲解,这也是面试的高频考点。
await和signal和signalAll方法就像一个开关控制着线程A(等待方)和线程B(通知方)。
它们之间的关系可以用下面一个图来表现得更加贴切():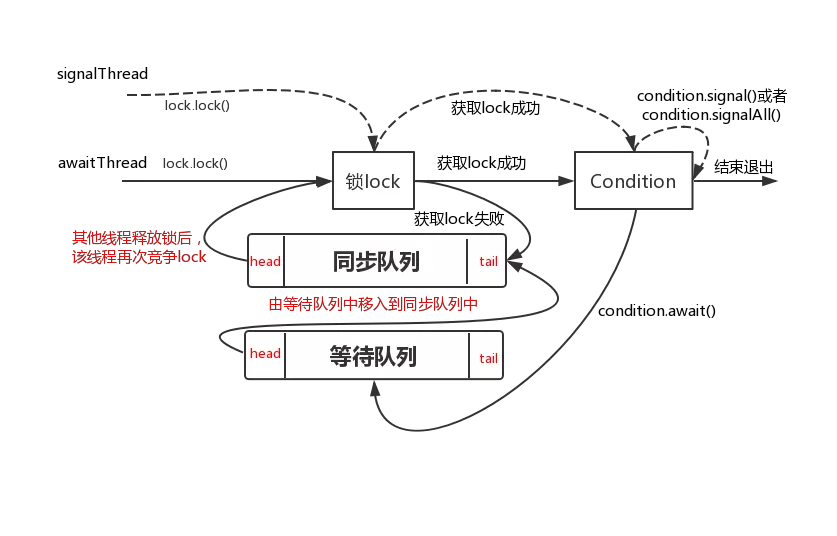
如图,
- 线程awaitThread先通过lock.lock()方法获取锁成功后调用了condition.await方法进入等待队列,
- 而另一个线程signalThread通过lock.lock()方法获取锁成功后调用了condition.signal或者signalAll方法,使得线程awaitThread能够有机会移入到同步队列中,
- 当其他线程释放lock后使得线程awaitThread能够有机会获取lock,从而使得线程awaitThread能够从await方法中退出执行后续操作。
- 如果awaitThread获取lock失败会直接进入到同步队列。
一个例子
我们用一个很简单的例子说说condition的用法:
- 示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class AwaitSignal
{
private static ReentrantLock lock = new ReentrantLock();
private static Condition condition = lock.newCondition();
private static volatile boolean flag = false;
public static void main(String[] args)
{
Thread waiter = new Thread(new waiter());
waiter.start();
Thread signaler = new Thread(new signaler());
signaler.start();
}
static class waiter implements Runnable
{
public void run()
{
lock.lock();
try
{
while (!flag)
{
System.out.println(Thread.currentThread().getName() + "当前条件不满足等待");
try
{
condition.await();
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + "接收到通知条件满足");
} finally
{
lock.unlock();
}
}
}
static class signaler implements Runnable
{
public void run()
{
lock.lock();
try
{
flag = true;
condition.signalAll();
} finally
{
lock.unlock();
}
}
}
} - 输出结果开启了两个线程waiter和signaler,waiter线程开始执行的时候由于条件不满足,执行condition.await方法使该线程进入等待状态同时释放锁,
1
2Thread-0当前条件不满足等待
Thread-0接收到通知,条件满足
signaler线程获取到锁之后更改条件,并通知所有的等待线程后释放锁。
这时(signaler线程已经执行完,也就是放锁),waiter线程获取到锁,并由于signaler线程更改了条件此时相对于waiter来说条件满足,继续执行。
LockSupport工具
LockSupport简介
在之前介绍AQS的底层实现,已经在介绍java中的Lock时,比如ReentrantLock,ReentReadWriteLocks,已经在介绍线程间等待/通知机制使用的Condition时都会调用LockSupport.park()方法和LockSupport.unpark()方法。
而这个在同步组件的实现中被频繁使用的LockSupport到底是何方神圣,现在就来看看。
LockSupport位于java.util.concurrent.locks包下,有兴趣的可以直接去看源码,该类的方法并不是很多。
LockSupport是线程阻塞工具类,用来阻塞线程和唤醒线程。
LockSupport方法介绍
LockSupport中的方法不多,这里将这些方法做一个总结:
阻塞线程
void park()阻塞当前线程。如果调用unpark方法或者当前线程被中断,可以取消当前线程的阻塞。void park(Object blocker)功能同方法1,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;void parkNanos(long nanos)阻塞当前线程,最长不超过nanos纳秒,增加了超时返回的特性;void parkNanos(Object blocker, long nanos)功能同方法3,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;void parkUntil(long deadline)阻塞当前线程,直到deadline时间点;void parkUntil(Object blocker, long deadline)功能同方法5,入参增加一个Object对象,用来记录导致线程阻塞的阻塞对象,方便进行问题排查;
唤醒线程
void unpark(Thread thread)唤醒处于阻塞状态的指定线程
实际上LockSupport阻塞和唤醒线程的功能是依赖于sun.misc.Unsafe,这是一个很底层的类,有兴趣的可以去查阅资料,比如park()方法的功能实现则是靠unsafe.park()方法。
另外在阻塞线程这一系列方法中还有一个很有意思的现象就是,每个方法都会新增一个带有Object的阻塞对象的重载方法。
那么增加了一个Object对象的入参会有什么不同的地方了?示例代码很简单就不说了,直接看dump线程的信息。
调用park()方法dump线程
1 | "main" #1 prio=5 os_prio=0 tid=0x02cdcc00 nid=0x2b48 waiting on condition [0x00d6f000] |
调用park(Object blocker)方法dump线程
1 | "main" #1 prio=5 os_prio=0 tid=0x0069cc00 nid=0x6c0 waiting on condition [0x00dcf000] |
通过分别调用这两个方法然后dump线程信息可以看出,带Object的park方法相较于无参的park方法会增加- parking...的信息,
这种信息就类似于记录“案发现场”,有助于工程人员能够迅速发现问题解决问题。
- 使用区别
1 | synchronized(obj){ |
1 | // 消费者 |
一个例子
- 示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public static void main(String[] args){
Thread threadA = new Thread(() ->
{
System.out.println("start "+LocalDateTime.now());
LockSupport.park();// 阻塞当前线程
//LockSupport.park(Object blocker);// 在Object对象上有序的阻塞线程
System.out.println("end "+LocalDateTime.now());
}, "A");
threadA.start();
Thread threadB = new Thread(() ->
{
try
{
TimeUnit.SECONDS.sleep(3);
LockSupport.unpark(threadA);// 取消unpark的阻塞
//threadA.interrupt();// 中断threadA,也会取消线程的阻塞
} catch (Exception e)
{
e.printStackTrace();
}
}, "B");
threadB.start();
}
//输出结果
// start 2020-06-22T11:20:47.919
// end 2020-06-22T11:20:50.897
并发容器之ConcurrentHashMap(JDK 1.8版本)
也可以参考ConcurrentHashmap JDK1.7与JDK1.8源码区别
ConcurrentHashmap简介
1 | final HashMap<String, String> map = new HashMap<String, String>(2); |
在使用HashMap时在多线程情况下扩容会出现CPU接近100%的情况,因为hashmap并不是线程安全的,
通常我们可以使用在java体系中古老的hashtable类,该类基本上所有的方法都采用synchronized进行线程安全的控制,
可想而知,在高并发的情况下,每次只有一个线程能够获取对象监视器锁,这样的并发性能的确不令人满意。
另外一种方式通过Collections.synchronizedMap(hashMap),将hashmap包装成一个线程安全的map。
比如SynchronzedMap的put方法源码为:
1 | public V put(K key, V value) { |
实际上SynchronizedMap实现依然是采用synchronized独占式锁进行线程安全的并发控制的。同样,这种方案的性能也是令人不太满意的。
针对这种境况,Doug Lea大师不遗余力的为我们创造了一些线程安全的并发容器,让每一个java开发人员倍感幸福。
相对于hashmap来说,ConcurrentHashMap就是线程安全的map,其中利用了锁分段的思想提高了并发度。
ConcurrentHashMap在JDK1.7的版本网上资料很多,有兴趣的可以去看看。 JDK 1.7版本关键要素:
- segment继承了ReentrantLock充当锁的角色,为每一个segment提供了线程安全的保障;
- segment维护了哈希散列表的若干个桶,每个桶由HashEntry构成的链表。
而到了JDK 1.8的ConcurrentHashMap就有了很大的变化,光是代码量就足足增加了很多。
1.8版本舍弃了segment,并且大量使用了synchronized,以及CAS无锁操作以保证ConcurrentHashMap操作的线程安全性。
至于为什么不用ReentrantLock而是Synchronzied呢?
实际上,synchronzied做了很多的优化,包括偏向锁,轻量级锁,重量级锁,可以依次向上升级锁状态,但不能降级(synchronized),因此,使用synchronized相较于ReentrantLock的性能会持平甚至在某些情况更优,
另外,底层数据结构改变为采用数组+链表+红黑树的数据形式。
关键属性及类
在了解ConcurrentHashMap的具体方法实现前,我们需要系统的来看一下几个关键的地方。
ConcurrentHashMap的关键属性
volatile Node<K,V>[] table:
装载Node的数组,作为ConcurrentHashMap的数据容器,采用懒加载的方式,直到第一次插入数据的时候才会进行初始化操作,数组的大小总是为2的幂次方。volatile Node<K,V>[] nextTable;
扩容时使用,平时为null,只有在扩容的时候才为非nullvolatile int sizeCtl;
该属性用来控制table数组的大小,根据是否初始化和是否正在扩容有几种情况:
当值为负数时:如果为-1表示正在初始化,如果为-N则表示当前正有N-1个线程进行扩容操作;
当值为正数时:如果当前数组为null的话表示table在初始化过程中,sizeCtl表示为需要新建数组的长度;
若已经初始化了,表示当前数据容器(table数组)可用容量也可以理解成临界值(插入节点数超过了该临界值就需要扩容),具体指为数组的长度n 乘以 加载因子loadFactor;
当值为0时,即数组长度为默认初始值。
4. sun.misc.Unsafe U
在ConcurrentHashMapde的实现中可以看到大量的U.compareAndSwapXXXX的方法去修改ConcurrentHashMap的一些属性。
这些方法实际上是利用了CAS算法保证了线程安全性,这是一种乐观策略,假设每一次操作都不会产生冲突,当且仅当冲突发生的时候再去尝试。
而CAS操作依赖于现代处理器指令集,通过底层CMPXCHG指令实现。
CAS(V,O,N)核心思想为:若当前变量实际值V与期望的旧值O相同,则表明该变量没被其他线程进行修改,因此可以安全的将新值N赋值给变量;若当前变量实际值V与期望的旧值O不相同,则表明该变量已经被其他线程做了处理,此时将新值N赋给变量操作就是不安全的,再进行重试。
而在大量的同步组件和并发容器的实现中使用CAS是通过sun.misc.Unsafe类实现的,该类提供了一些可以直接操控内存和线程的底层操作,可以理解为java中的“指针”。
该成员变量的获取是在静态代码块中:
1 | static { |
ConcurrentHashMap中关键内部类
NodeNode类实现了Map.Entry接口,主要存放key-value对,并且具有next域1
2
3
4
5
6
7static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
......
}另外可以看出很多属性都是用volatile进行修饰的,也就是为了保证内存可见性。
TreeNode树节点,继承于承载数据的Node类。
而红黑树的操作是针对TreeBin类的,从该类的注释也可以看出,也就是TreeBin会将TreeNode进行再一次封装1
2
3
4
5
6
7
8
9
10
11**
* Nodes for use in TreeBins
*/
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
......
}TreeBin这个类并不负责包装用户的key、value信息,而是包装的很多TreeNode节点。
实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象。1
2
3
4
5
6
7
8
9
10
11static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
......
}ForwardingNode在扩容时才会出现的特殊节点,其key,value,hash全部为null。并拥有nextTable指针引用新的table数组。1
2
3
4
5
6
7
8static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
.....
}
CAS关键操作
在上面我们提及到在ConcurrentHashMap中会大量使用CAS修改它的属性和一些操作。
因此,在理解ConcurrentHashMap的方法前我们需要了解下面几个常用的利用CAS算法来保障线程安全的操作。
tabAt该方法用来获取table数组中索引为i的Node元素。1
2
3static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}casTabAt利用CAS操作设置table数组中索引为 i 的元素1
2
3
4static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}setTabAt该方法用来设置table数组中索引为 i 的元素1
2
3static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
重点方法讲解
在熟悉上面的这核心信息之后,我们接下来就来依次看看几个常用的方法是怎样实现的。
实例构造器方法
在使用ConcurrentHashMap第一件事自然而然就是new 出来一个ConcurrentHashMap对象,一共提供了如下几个构造器方法:
1 | // 1. 构造一个空的map,即table数组还未初始化,初始化放在第一次插入数据时,默认大小为16 |
ConcurrentHashMap一共给我们提供了5中构造器方法,具体使用请看注释,我们来看看第2种构造器,传入指定大小时的情况,该构造器源码为:
1 | public ConcurrentHashMap(int initialCapacity) { |
这段代码的逻辑请看注释,很容易理解,
- 如果小于0就直接抛出异常
- 如果指定值大于了所允许的最大值的话就取最大值,否则,在对指定值做进一步处理。
- 最后将cap赋值给sizeCtl,
关于sizeCtl的说明请看上面的说明,当调用构造器方法之后,sizeCtl的大小应该就代表了ConcurrentHashMap的大小,即table数组长度
tableSizeFor做了哪些事情了?源码为:
1 | /** |
通过注释就很清楚了,该方法会将调用构造器方法时指定的大小转换成一个2的幂次方数,也就是说ConcurrentHashMap的大小一定是2的幂次方,
比如,当指定大小为18时,为了满足2的幂次方特性,实际上concurrentHashMapd的大小为2的5次方(32)。
另外,需要注意的是,调用构造器方法的时候并未构造出table数组(可以理解为ConcurrentHashMap的数据容器),只是算出table数组的长度,当第一次向ConcurrentHashMap插入数据的时候才真正的完成初始化创建table数组的工作。
initTable方法
1 | private final Node<K,V>[] initTable() { |
代码的逻辑请见注释,有可能存在一个情况是多个线程同时走到这个方法中,为了保证能够正确初始化,在第1步中会先通过if进行判断,若当前已经有一个线程正在初始化即sizeCtl值变为-1,这个时候其他线程在If判断为true从而调用Thread.yield()让出CPU时间片。
正在进行初始化的线程会调用U.compareAndSwapInt方法将sizeCtl改为-1即正在初始化的状态。
另外还需要注意的事情是,在第四步中会进一步计算数组中可用的大小即为数组实际大小n乘以加载因子0.75.可以看看这里乘以0.75是怎么算的,0.75为四分之三,这里n - (n >>> 2)是不是刚好是n-(1/4)n=(3/4)n
如果选择是无参的构造器的话,这里在new Node数组的时候会使用默认大小为DEFAULT_CAPACITY(16),然后乘以加载因子0.75为12,也就是说数组的可用大小为12。
put方法
使用ConcurrentHashMap最长用的也应该是put和get方法了吧,我们先来看看put方法是怎样实现的。
调用put方法时实际具体实现是putVal方法,源码如下:
1 | public V put(K key, V value) { |
1 | /** Implementation for put and putIfAbsent */ |
put方法的代码量有点长,我们按照上面的分解的步骤一步步来看。
从整体而言,为了解决线程安全的问题,ConcurrentHashMap使用了synchronzied和CAS的方式。
在之前了解过HashMap以及1.8版本之前的ConcurrenHashMap都应该知道ConcurrentHashMap结构图,为了方面下面的讲解这里先直接给出,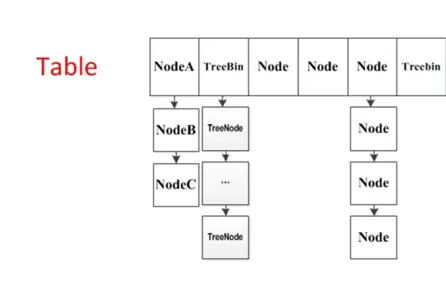
ConcurrentHashMap是一个哈希桶数组,
如果不出现哈希冲突的时候,每个元素均匀的分布在哈希桶数组中;
当出现哈希冲突的时候,是标准的链地址的解决方式,将hash值相同的节点构成链表的形式,称为“拉链法”;
另外,在1.8版本中为了防止拉链过长,当链表的长度大于8的时候会将链表转换成红黑树。table数组中的每个元素实际上是单链表的头结点或者红黑树的根节点。
当插入键值对时首先应该定位到要插入的桶,即插入table数组的索引 i 处。
那么,怎样计算得出索引 i 呢?当然是根据key的hashCode值。
- spread()重哈希,以减小Hash冲突
我们知道对于一个hash表来说,hash值分散的不够均匀的话会大大增加哈希冲突的概率,从而影响到hash表的性能。
因此通过spread方法进行了一次重hash从而大大减小哈希冲突的可能性。
spread方法为:该方法主要是将key的hashCode的低16位于高16位进行异或运算,这样不仅能够使得hash值能够分散能够均匀减小hash冲突的概率,1
2
3static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
另外只用到了异或运算,在性能开销上也能兼顾,做到平衡。 - 初始化table
紧接着到第2步,会判断当前table数组是否初始化了,没有的话就调用initTable进行初始化,该方法在上面已经讲过了。 - 能否直接将新值插入到table数组中
从上面的结构示意图就可以看出存在这样一种情况,如果插入值待插入的位置刚好所在的table数组为null的话就可以直接将值插入即可。
那么怎样根据hash确定在table中待插入的索引 i 呢?很显然可以通过hash值与数组的长度取模操作,从而确定新值插入到数组的哪个位置。
而之前我们提过ConcurrentHashMap的大小总是2的幂次方,(n - 1) & hash运算等价于对长度n取模,也就是hash%n,但是位运算比取模运算的效率要高很多,Doug lea大师在设计并发容器的时候也是将性能优化到了极致,令人钦佩。
确定好数组的索引 i 后,就可以可以tabAt()方法(在上面已经说明了)获取该位置上的元素,如果当前Node f为null的话,就可以直接用casTabAt方法将新值插入即可。
4. 当前是否正在扩容
如果当前节点不为null,且该节点为特殊节点(forwardingNode)的话,就说明当前concurrentHashMap正在进行扩容操作,关于扩容操作,下面会作为一个具体的方法进行讲解。
那么怎样确定当前的这个Node是不是特殊的节点了?是通过判断该节点的hash值是不是等于-1(MOVED),代码为(fh = f.hash) == MOVED,对MOVED的解释在源码上也写的很清楚了:
1 | static final int MOVED = -1; // hash for forwarding nodes |
当table[i]为链表的头结点,在链表中插入新值
在table[i]不为null并且不为forwardingNode时,并且当前Node f的hash值大于0(fh >= 0)的话,说明当前节点f为当前桶的所有的节点组成的链表的头结点。
那么接下来,要想向ConcurrentHashMap插入新值的话就是向这个链表插入新值。通过synchronized (f)的方式进行加锁以实现线程安全性。
往链表中插入节点的部分代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到hash值相同的key,覆盖旧值即可
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
//如果到链表末尾仍未找到,则直接将新值插入到链表末尾即可
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}这部分代码很好理解,就是两种情况:
- 在链表中如果找到了与待插入的键值对的key相同的节点,就直接覆盖即可;
- 如果直到找到了链表的末尾都没有找到的话,就直接将待插入的键值对追加到链表的末尾即可
当table[i]为红黑树的根节点,在红黑树中插入新值
按照之前的数组+链表的设计方案,这里存在一个问题,即使负载因子和Hash算法设计的再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,甚至在极端情况下,查找一个节点会出现时间复杂度为O(logn)的情况,则会严重影响ConcurrentHashMap的性能,
于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高ConcurrentHashMap的性能,其中会用到红黑树的插入、删除、查找等算法。
当table[i]为红黑树的树节点时的操作为:1
2
3
4
5
6
7
8
9
10if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}首先在if中通过
f instanceof TreeBin判断当前table[i]是否是树节点,这下也正好验证了我们在最上面介绍时说的TreeBin会对TreeNode做进一步封装,对红黑树进行操作的时候针对的是TreeBin而不是TreeNode。
这段代码很简单,调用putTreeVal方法完成向红黑树插入新节点,同样的逻辑,如果在红黑树中存在于待插入键值对的Key相同(hash值相等并且equals方法判断为true)的节点的话,就覆盖旧值,否则就向红黑树追加新节点根据当前节点个数进行调整
当完成数据新节点插入之后,会进一步对当前链表大小进行调整,这部分代码为:1
2
3
4
5
6
7if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}很容易理解,如果当前链表节点个数大于等于8(TREEIFY_THRESHOLD)的时候,就会调用treeifyBin方法将
tabel[i](第i个散列桶)拉链转换成红黑树。
至此,关于Put方法的逻辑就基本说的差不多了,现在来做一些总结:
整体流程:
- 首先对于每一个放入的值,首先利用spread方法对key的hashcode进行一次hash计算,由此来确定这个值在 table中的位置;
- 如果当前table数组还未初始化,先将table数组进行初始化操作;
- 如果这个位置是null的,那么使用CAS操作直接放入;
- 如果这个位置存在结点,说明发生了hash碰撞,首先判断这个节点的类型。如果该节点fh==MOVED(代表forwardingNode,数组正在进行扩容)的话,说明正在进行扩容;
- 如果是链表节点(fh>0),则得到的结点就是hash值相同的节点组成的链表的头节点。需要依次向后遍历确定这个新加入的值所在位置。如果遇到key相同的节点,则只需要覆盖该结点的value值即可。否则依次向后遍历,直到链表尾插入这个结点;
- 如果这个节点的类型是TreeBin的话,直接调用红黑树的插入方法进行插入新的节点;
- 插入完节点之后再次检查链表长度,如果长度大于8,就把这个链表转换成红黑树;
- 对当前容量大小进行检查,如果超过了临界值(
实际大小*加载因子)就需要扩容。
get方法
看完了put方法再来看get方法就很容易了,用逆向思维去看就好,这样存的话我反过来这么取就好了。
get方法源码为:
1 | public V get(Object key) { |
代码的逻辑请看注释,
首先先看当前的hash桶数组节点即table[i]是否为查找的节点,若是则直接返回;若不是,则继续再看当前是不是树节点?通过看节点的hash值是否为小于0,
如果小于0则为树节点。如果是树节点在红黑树中查找节点;如果不是树节点,那就只剩下为链表的形式的一种可能性了,就向后遍历查找节点,若查找到则返回节点的value即可,若没有找到就返回null。
transfer方法
当ConcurrentHashMap容量不足的时候,需要对table进行扩容。
这个方法的基本思想跟HashMap是很像的,但是由于它是支持并发扩容的,所以要复杂的多。原因是它支持多线程进行扩容操作,而并没有加锁。
我想这样做的目的不仅仅是为了满足concurrent的要求,而是希望利用并发处理去减少扩容带来的时间影响。
transfer方法源码为:
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
代码逻辑请看注释,整个扩容操作分为两个部分:
- 构建一个nextTable,它的容量是原来的两倍,这个操作是单线程完成的。
新建table数组的代码为:Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1],在原容量大小的基础上右移一位。 - 将原来table中的元素复制到nextTable中,主要是遍历复制的过程。 根据运算得到当前遍历的数组的位置i,然后利用tabAt方法获得i位置的元素再进行判断:
- 如果这个位置为空,就在原table中的i位置放入forwardNode节点,这个也是触发并发扩容的关键点;
- 如果这个位置是Node节点(fh>=0),如果它是一个链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上
- 如果这个位置是TreeBin节点(fh<0),也做一个反序处理,并且判断是否需要untreefi,把处理的结果分别放在nextTable的i和i+n的位置上
- 遍历过所有的节点以后就完成了复制工作,这时让nextTable作为新的table,并且更新sizeCtl为新容量的0.75倍 ,完成扩容。
设置为新容量的0.75倍代码为sizeCtl = (n << 1) - (n >>> 1),仔细体会下是不是很巧妙,n<<1相当于n右移一位表示n的两倍即2n,n>>>1左右一位相当于n除以2即0.5n,然后两者相减为2n-0.5n=1.5n,是不是刚好等于新容量的0.75倍即2n*0.75=1.5n。
最后用一个示意图来进行总结(图片摘自网络):
与size相关的一些方法
对于ConcurrentHashMap来说,这个table里到底装了多少东西其实是个不确定的数量,因为不可能在调用size()方法的时候像GC的“stop the world”一样让其他线程都停下来让你去统计,因此只能说这个数量是个估计值。
对于这个估计值,ConcurrentHashMap也是大费周章才计算出来的。
为了统计元素个数,ConcurrentHashMap定义了一些变量和一个内部类
1 | /** |
mappingCount与size方法
mappingCount与size方法的类似 从给出的注释来看,应该使用mappingCount代替size方法 两个方法都没有直接返回basecount 而是统计一次这个值,而这个值其实也是一个大概的数值,因此可能在统计的时候有其他线程正在执行插入或删除操作。
1 | public int size() { |
addCount方法
在put方法结尾处调用了addCount方法,把当前ConcurrentHashMap的元素个数+1这个方法一共做了两件事,更新baseCount的值,检测是否进行扩容。
1 | private final void addCount(long x, int check) { |
总结
JDK6,7中的ConcurrentHashmap主要使用Segment来实现减小锁粒度,分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性,当要统计全局时(比如size),
首先会尝试多次计算modcount来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回size。如果有,则需要依次锁住所有的Segment来计算。
1.8之前put定位节点时要先定位到具体的segment,然后再在segment中定位到具体的桶。
而在1.8的时候摒弃了segment臃肿的设计,直接针对的是Node[] tale数组中的每一个桶,进一步减小了锁粒度。
并且防止拉链过长导致性能下降,当链表长度大于8的时候采用红黑树的设计。
主要设计上的变化有以下几点:
- 采用segment而采用node,锁住node来实现减小锁粒度。
- 设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
- 使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
- sizeCtl的不同值来代表不同含义,起到了控制的作用。
- 采用synchronized而不是ReentrantLock
并发容器之CopyOnWriteArrayList
CopyOnWriteArrayList的简介
java学习者都清楚ArrayList并不是线程安全的,在读线程在读取ArrayList的时候如果有写线程在写数据的时候,基于fast-fail机制,会抛出ConcurrentModificationException异常,
也就是说ArrayList并不是一个线程安全的容器,当然您可以用Vector,或者使用Collections的静态方法将ArrayList包装成一个线程安全的类,但是这些方式都是采用java关键字synchronzied对方法进行修饰,利用独占式锁来保证线程安全的。
但是,由于独占式锁在同一时刻只有一个线程能够获取到对象监视器,很显然这种方式效率并不是太高。
回到业务场景中,有很多业务往往是读多写少的,比如系统配置的信息,除了在初始进行系统配置的时候需要写入数据,其他大部分时刻其他模块之后对系统信息只需要进行读取,又比如白名单,黑名单等配置,只需要读取名单配置然后检测当前用户是否在该配置范围以内。
类似的还有很多业务场景,它们都是属于读多写少的场景。如果在这种情况用到上述的方法,使用Vector,Collections转换的这些方式是不合理的,因为尽管多个读线程从同一个数据容器中读取数据,但是读线程对数据容器的数据并不会发生发生修改。
很自然而然的我们会联想到ReentrantReadWriteLock, 通过读写分离的思想,使得读读之间不会阻塞,无疑如果一个list能够做到被多个读线程读取的话,性能会大大提升不少。
但是,如果仅仅是将list通过读写锁(ReentrantReadWriteLock)进行再一次封装的话,由于读写锁的特性,当写锁被写线程获取后,读写线程都会被阻塞。
如果仅仅使用读写锁对list进行封装的话,这里仍然存在读线程在读数据的时候被阻塞的情况,如果想list的读效率更高的话,这里就是我们的突破口,如果我们保证读线程无论什么时候都不被阻塞,效率岂不是会更高?
Doug Lea大师就为我们提供CopyOnWriteArrayList容器可以保证线程安全,保证读读之间在任何时候都不会被阻塞,CopyOnWriteArrayList也被广泛应用于很多业务场景之中,CopyOnWriteArrayList值得被我们好好认识一番。
COW的设计思想
回到上面所说的,如果简单的使用读写锁的话,在写锁被获取之后,读写线程被阻塞,只有当写锁被释放后读线程才有机会获取到锁从而读到最新的数据,站在读线程的角度来看,即读线程任何时候都是获取到最新的数据,满足数据实时性。
既然我们说到要进行优化,必然有trade-off(交换),我们就可以牺牲数据实时性满足数据的最终一致性即可。
而CopyOnWriteArrayList就是通过Copy-On-Write(COW),即写时复制的思想来通过延时更新的策略来实现数据的最终一致性,并且能够保证读线程间不阻塞。(这里指最终一致性,而不是实时一致性)
- COW通俗的理解是
当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。对CopyOnWrite容器进行并发的读的时候,不需要加锁,因为当前容器不会添加任何元素。
所以CopyOnWrite容器也是一种读写分离的思想,延时更新的策略是通过在写的时候针对的是不同的数据容器来实现的,放弃数据实时性达到数据的最终一致性。
CopyOnWriteArrayList的实现原理
现在我们来通过看源码的方式来理解CopyOnWriteArrayList,实际上CopyOnWriteArrayList内部维护的就是一个数组
1 | /** The array, accessed only via getArray/setArray. */ |
并且该数组引用是被volatile修饰,注意这里仅仅是修饰的是数组引用,其中另有玄机,稍后揭晓。(也就是说对数组的修改,对读是不可见的,只有修改了引用才可见)
关于volatile很重要的一条性质是它能够够保证可见性
(针对volatile修饰的变量,举例:线程A的缓存,线程B的缓存,主内存:A修改了内容,重新写入主存,因为B一直在监测那个变量,如果不一致,当前失效,重新从主存读取到当前缓存,从而实现可见性,如果是引用类型,因为内存里只放引用的地址,只有改变了引用,才可见)
对list来说,我们自然而然最关心的就是读写的时候,分别为get和add方法的实现。
get方法实现原理
1 | public E get(int index) { |
可以看出来get方法实现非常简单,几乎就是一个“单线程”程序,没有对多线程添加任何的线程安全控制,也没有加锁也没有CAS操作等等,
原因是,所有的读线程只是会读取数据容器中的数据,并不会进行修改。
add方法实现原理
1 | public boolean add(E e) { |
add方法的逻辑也比较容易理解,请看上面的注释。需要注意这么几点:
- 采用ReentrantLock,保证同一时刻只有一个写线程正在进行数组的复制,否则的话内存中会有多份被复制的数据;
- 前面说过
数组引用是volatile修饰的,因此将旧的数组引用指向新的数组,根据volatile的happens-before规则,写线程对数组引用的修改对读线程是可见的。 - 由于在写数据的时候,是在新的数组中插入数据的,从而保证读写实在两个不同的数据容器中进行操作。
总结
COW vs 读写锁
我们知道COW和读写锁都是通过读写分离的思想实现的,但两者还是有些不同,可以进行比较:
相同点:
- 两者都是通过读写分离的思想实现;
- 读线程间是互不阻塞的
不同点:
读写锁依然会出现读线程阻塞等待的情况
(对读线程而言,为了实现数据实时性,在写锁被获取后,读线程会等待或者当读锁被获取后,写线程会等待,从而解决“脏读”等问题。)COW则完全放开了牺牲数据实时性而保证数据最终一致性,即读线程对数据的更新是延时感知的,因此读线程不会存在等待的情况。
对这一点从文字上还是很难理解,我们来通过debug看一下,add方法核心代码为:
1 | 1.Object[] elements = getArray(); |
- 假设COW的变化如下图所示:
数组中已有数据1,2,3,现在写线程想往数组中添加数据4,我们在第5行处打上断点,让写线程暂停。
读线程依然会“不受影响”的能从数组中读取数据,可是还是只能读到1,2,3。如果读线程能够立即读到新添加的数据的话就叫做能保证数据实时性。
当对第5行的断点放开后,读线程才能感知到数据变化,读到完整的数据1,2,3,4,而保证数据最终一致性,尽管有可能中间间隔了好几秒才感知到。
这里还有这样一个问题:
问为什么需要复制呢? 如果将array 数组设定为volatile的, 对volatile变量写happens-before读,读线程不是能够感知到volatile变量的变化。答这里volatile的修饰的仅仅只是数组引用,数组中的元素的修改是不能保证可见性的。
因此COW采用的是新旧两个数据容器,通过第5行代码将数组引用指向新的数组,也就是改变了引用指向。
COW的缺点
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。
所以在开发的时候需要注意一下。
内存占用问题因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对 象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。
如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的minor GC和major GC。数据一致性问题CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
什么是一致性?
一致性(Consistency)是指多线程中数据一致性的问题。可以分为强一致性、顺序一致性与弱一致性。
强一致性也叫原子性,在任意时刻,所有线程中的数据是一样的。
例如,对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。顺序一致性按照程序的执行顺序进行,JMM会进行指令重排序弱一致性,也叫最终一致性,不能实时保证可见,但有可能过几秒后可见,也就是最终可见
并发容器之ConcurrentLinkedQueue
ConcurrentLinkedQueue简介
在单线程编程中我们会经常用到一些集合类,比如ArrayList,HashMap等,但是这些类都不是线程安全的类。
在面试中也经常会有一些考点,比如ArrayList不是线程安全的,Vector是线程安全。
而保障Vector线程安全的方式,是非常粗暴的在方法上用synchronized独占锁,将多线程执行变成串行化。
要想将ArrayList变成线程安全的也可以使用Collections.synchronizedList(List<T> list)方法ArrayList转换成线程安全的,但这种转换方式依然是通过synchronized修饰方法实现的,很显然这不是一种高效的方式,同时,队列也是我们常用的一种数据结构,
为了解决线程安全的问题,Doug Lea大师为我们准备了ConcurrentLinkedQueue这个线程安全的队列。从类名就可以看的出来实现队列的数据结构是链式。
Node
要想先学习ConcurrentLinkedQueue自然而然得先从它的节点类看起,明白它的底层数据结构。
Node类的源码为:
1 | private static class Node<E> { |
Node节点主要包含了两个域:一个是数据域item,另一个是next指针,用于指向下一个节点从而构成链式队列。
并且都是用volatile进行修饰的,为了保证内存可见性。
另外ConcurrentLinkedQueue含有这样两个成员变量:
1 | private transient volatile Node<E> head; |
说明ConcurrentLinkedQueue通过持有头尾指针进行管理队列。
当我们调用无参构造器时,其源码为:
1 | public ConcurrentLinkedQueue() { |
head和tail指针会指向一个item域为null的节点,此时ConcurrentLinkedQueue状态如下图所示:
如图,head和tail指向同一个节点Node0,该节点item域为null,next域为null。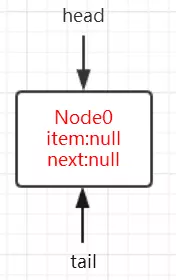
操作Node的几个CAS操作
在队列进行出队入队的时候免不了对节点需要进行操作,在多线程就很容易出现线程安全的问题。
可以看出在处理器指令集能够支持CMPXCHG指令后,在java源码中涉及到并发处理都会使用CAS操作,
那么在ConcurrentLinkedQueue对Node的CAS操作有这样几个:
1 | //更改Node中的数据域item |
可以看出这些方法实际上是通过调用UNSAFE实例的方法,UNSAFE为sun.misc.Unsafe类,
该类是hotspot底层方法,了解即可,知道CAS的操作是由该类提供就好。
offer方法
对一个队列来说,插入满足FIFO(first in first out先进先出)特性,插入元素总是在队列最末尾的地方进行插入,而取(移除)元素总是从队列的队头。
所有要想能够彻底弄懂ConcurrentLinkedQueue自然而然是从offer(插入)方法和poll(取出)方法开始。
那么为了能够理解offer方法,采用debug的方式来一行一行的看代码走。
另外,在看多线程的代码时,可采用这样的思维方式:
一,单个线程offer
二,多个线程offer(部分线程offer,部分线程poll)
offer的速度快于poll
队列长度会越来越长,由于offer节点总是在对队列队尾,而poll节点总是在队列对头,也就是说offer线程和poll线程两者并无“交集”,也就是说两类线程间并不会相互影响,这种情况站在相对速率的角度来看,也就是一个”单线程offer”offer的速度慢于poll
poll的相对速率快于offer,也就是队头删的速度要快于队尾添加节点的速度,导致的结果就是队列长度会越来越短,而offer线程和poll线程就会出现“交集”,
即那一时刻就可以称之为offer线程和poll线程同时操作的节点为临界点 ,且在该节点offer线程和poll线程必定相互影响。
怎么影响呢? 根据在临界点时offer和poll发生的相对顺序又可从两个角度去思考:
offer-->poll-->offer(offer过程中执行poll),即表现为当offer线程在Node1后插入Node2时,此时poll线程已经将Node1删除,这种情况很显然需要在offer方法中考虑;poll-->offer-->poll(poll过程中执行offer),即表现为当poll线程准备删除的节点为null时(队列为空队列),此时offer线程插入一个节点使得队列变为非空队列
先看这么一段代码:
1 | 1. ConcurrentLinkedQueue<Integer> queue = new ConcurrentLinkedQueue<>(); |
创建一个ConcurrentLinkedQueue实例,先offer 1,然后再offer 2。
offer的源码为:
1 | public boolean offer(E e) { |
单线程分析offer
先从单线程执行的角度看起,分析offer 1的过程。
- 第1行代码会对是否为null进行判断,为null的话就直接抛出空指针异常,
- 第2行代码将e包装成一个Node类,
- 第3行为for循环,只有初始化条件没有循环结束条件,这很符合CAS的“套路”,在循环体CAS操作成功会直接return返回,如果CAS操作失败的话就在for循环中不断重试直至成功。
这里实例变量t被初始化为tail,p被初始化为t即tail。(为了方便下面的理解,p被认为队列真正的尾节点,tail不一定指向对象真正的尾节点,因为在ConcurrentLinkedQueue中tail是被延迟更新的,具体原因我们慢慢来看。)
代码走到第3行的时候,t和p都分别指向初始化时创建的item域为null,next域为null的Node0。 - 第4行变量q被赋值为null,
- 第5行if判断为true,
- 在第7行使用casNext将插入的Node设置成当前队列尾节点p的next节点,如果CAS操作失败,此次循环结束在下次循环中进行重试。
- CAS操作成功走到第8行,此时p==t,if判断为false,直接return true返回。
如果成功插入1的话,此时ConcurrentLinkedQueue的状态如下图所示: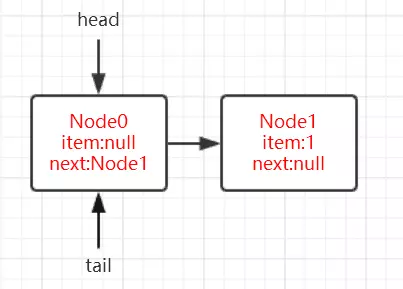
如图,此时队列的尾节点应该为Node1,而tail指向的节点依然还是Node0,因此可以说明tail是延迟更新的。
那么我们继续来看offer 2的时候的情况,
- 很显然此时第4行q指向的节点不为null了,而是指向Node1,
- 第5行if判断为false,
- 第11行if判断为false,
- 代码会走到第13行。(第13行代码就是找出队列真正的尾节点。)
好了,再插入节点的时候我们会问自己这样一个问题?上面已经解释了tail并不是指向队列真正的尾节点,那么在插入节点的时候,我们是不是应该最开始做的就是找到队列当前的尾节点在哪里才能插入?
那么第13行代码就是找出队列真正的尾节点。
定位队列真正的对尾节点
1 | p = (p != t && t != (t = tail)) ? t : q; |
- 我们来分析一下这行代码(第13行),如果这段代码在
单线程环境执行时,很显然由于p==t,此时p会被赋值为q,而q等于Node<E> q = p.next,即Node1,在第一次循环中指针p指向了队列真正的队尾节点Node1 - 那么在下一次循环中第4行q指向的节点为null,
- 那么在第5行中if判断为true,
- 那么在第7行依然通过casNext方法设置p节点的next为当前新增的Node,(当前是正在offer 2)
- 接下来走到第8行,这个时候p!=t,第8行if判断为true,
- 会通过casTail(t, newNode)将当前节点Node设置为队列的队尾节点,
此时的队列状态示意图如下图所示: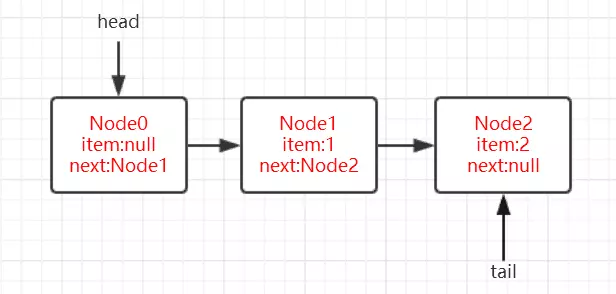
tail指向的节点由Node0改变为Node2,这里的casTail失败不需要重试的原因是,
offer代码中主要是通过q节点,也就是p的next节点Node<E> q = p.next决定后面的逻辑走向的,当casTail失败时状态示意图如下: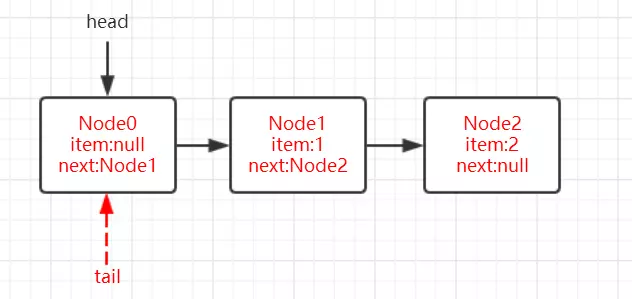
如图,如果这里casTail设置tail失败即tail还是指向Node0节点的话,无非就是多循环几次通过13行代码定位到队尾节点。
通过对单线程执行角度进行分析,我们可以了解到poll的执行逻辑为:
- 如果tail指向的节点的下一个节点(next域)为null的话,
说明tail指向的节点即为队列真正的队尾节点,因此可以通过casNext插入当前待插入的节点,但此时tail并未变化,如下图;
- 如果tail指向的节点的下一个节点(next域)不为null的话,
说明tail指向的节点不是队列的真正队尾节点。通过q(Nodeq = p.next)指针往前递进去找到队尾节点,然后通过casNext插入当前待插入的节点,并通过casTail方式更改tail,如下图。 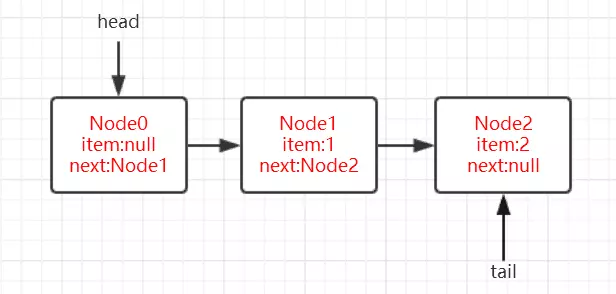
我们回过头再来看p = (p != t && t != (t = tail)) ? t : q;这行代码(第12行)在单线程中,这段代码永远不会将p赋值为t,
那么这么写就不会有任何作用,那我们试着在多线程的情况下进行分析。
多线程分析offer
很显然这么写另有深意,其实在多线程环境下这行代码很有意思的。t != (t = tail)这个操作并非一个原子操作, 有这样一种情况:
如图,
- 假设线程A此时读取了变量t,
- 线程B刚好在这个时候offer一个Node后,此时会修改tail指针,
- 那么这个时候线程A再次执行t=tail时t会指向另外一个节点,
很显然线程A前后两次读取的变量t指向的节点不相同,即t != (t = tail)为true,并且由于t指向节点的变化p != t也为true,
此时该行代码的执行结果为p和t(最新的t指针)指向了同一个节点,并且此时t也是队列真正的尾节点。
那么,现在已经定位到队列真正的队尾节点,就可以执行offer操作了。
offer->poll->offer(在offer的过程中,执行了poll)
那么还剩下第11行的代码我们没有分析,大致可以猜想到应该就是回答一部分线程offer,一部分poll的这种情况。
当if (p == q)为true时,说明p指向的节点的next也指向它自己,这种节点称之为哨兵节点,这种节点在队列中存在的价值不大,一般表示为要删除的节点或者是空节点。
为了能够很好的理解这种情况,我们先看看poll方法的执行过程后,再回过头来看,总之这是一个很有意思的事情。
poll方法
1 | public E poll() { |
单线程分析poll
假设ConcurrentLinkedQueue初始状态如下图所示:
参数offer时的定义,我们还是先将变量p作为队列要删除真正的队头节点,h(head)指向的节点并不一定是队列的队头节点。
- 先来看poll出Node1时的情况,由于p=h=head,参照上图,
- 很显然此时p指向的Node1的数据域不为null,
- 在第4行代码中item!=null判断为true后接下来通过casItem将Node1的数据域设置为null。如果CAS设置失败则此次循环结束等待下一次循环进行重试。
- 若第4行执行成功进入到第5行代码,此时p和h都指向Node1,第5行if判断为false,
- 然后直接到第7行return回Node1的数据域item 1,方法运行结束,
此时的队列状态如下图。
下面继续从队列中poll,很显然当前h和p指向的Node1的数据域为null,
那么第一件事就是要定位准备删除的队头节点(找到数据域不为null的节点)。
定位删除的队头节点
继续看,
- 第三行代码item为null,
- 第4行代码if判断为false,
- 走到第8行代码(q = p.next)if也为false,
- 由于p指向Node1,q指向了Node2,在第11行的if判断也为false,
- 因此代码走到了第13行,这个时候p和q共同指向了Node2,也就找到了要删除的真正的队头节点。
可以总结出,定位待删除的队头节点的过程为:如果当前节点(Node)的数据域(item)为null,很显然该节点不是待删除的节点,就用当前节点的下一个节点去试探。
在经过第一次循环后,此时状态图为下图: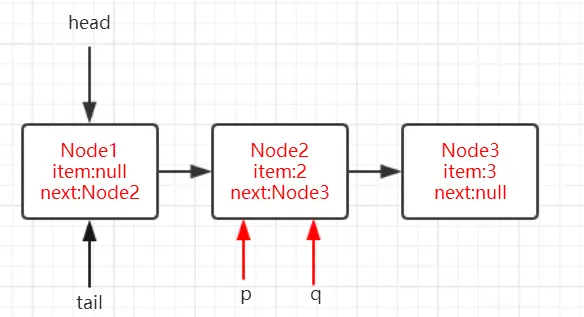
进行下一次循环,
- 第4行的操作同上述,当前假设第4行中casItem设置成功,
- 由于p已经指向了Node2,而h还依旧指向Node1,此时第5行的if判断为true,
- 然后执行
updateHead(h, ((q = p.next) != null) ? q : p),此时q指向Node3,所以传入updateHead方法的分别是指向Node1的h引用和指向Node3的q引用。
updateHead方法的源码为:1
2
3
4final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);
} - 该方法主要是通过
casHead将队列的head指向Node3,并且通过h.lazySetNext将Node1的next域指向它自己。 - 最后在第7行代码中返回Node2的值。
此时队列的状态如下图所示: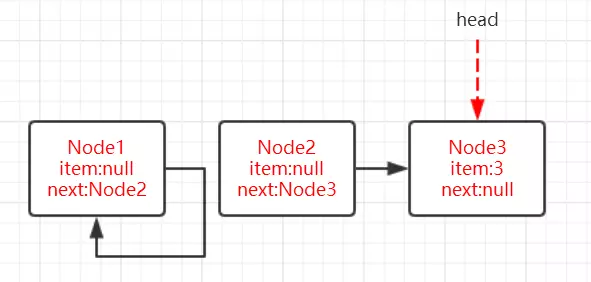
Node1的next域指向它自己,head指向了Node3。
再执行一次方法,Node3的item设置为null
再执行一次,就会执行到代码的第8行(q = p.next) == null,if判断为true,因此在第10行中直接返回null。
以上的分析是从单线程执行的角度去看,也可以让我们了解poll的整体思路,现在来做一个总结:
- 如果当前head,h和p指向的节点的Item不为null的话,说明该节点为真正的头节点(待删除节点,需移出队列),只需要通过casItem方法将item域设置为null,然后将原来的item直接返回即可。
- 如果当前head,h和p指向的节点的item为null的话,则说明该节点不是真正的待删除节点,那么应该做的就是寻找item不为null的节点。
通过让q指向p的下一个节点(q = p.next)进行试探,若找到则通过updateHead方法更新head指向的节点以及构造哨兵节点(通过updateHead方法的h.lazySetNext(h))。
接下来,按照上面分析offer的思维方式,下面来分析一下多线程的情况,第一种情况是;
多线程分析poll
现在回过头来看poll方法的源码,有这样一部分:
1 | else if (p == q) |
这一部分就是处理多个线程poll的情况,q = p.next也就是说q永远指向的是p的下一个节点,
那么什么情况下会使得p,q指向同一个节点呢?根据上面我们的分析,只有p指向的节点在poll的时候转变成了哨兵节点(通过updateHead方法中的h.lazySetNext)。
当线程A在执行q = p.next之前一步,线程B已经将执行完poll方法将p指向的节点转换为哨兵节点并且head指向的节点已经发生了改变,所以q = p.next就需要从restartFromHead处执行,保证用到的是最新的head。
poll->offer->poll(在poll的过程中,执行了offer)
试想,还有这样一种情况,如果当前队列为空队列,线程A进行poll操作,同时线程B执行offer,然后线程A在执行poll,那么此时线程A返回的是null还是线程B刚插入的最新的那个节点呢?
- 我们来写一代demo:
1
2
3
4
5
6
7
8
9
10
11
12public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
Integer value = queue.poll();
System.out.println(Thread.currentThread().getName() + " poll 的值为:" + value);
System.out.println("queue当前是否为空队列:" + queue.isEmpty());
});
thread1.start();
Thread thread2 = new Thread(() -> {
queue.offer(1);
});
thread2.start();
} - 输出结果为:通过debug控制线程thread1和线程thread2的执行顺序,
1
Thread-0 poll 的值为:null queue当前是否为空队列:false
- thread1先执行到第8行代码if ((q = p.next) == null),由于此时队列为空队列if判断为true,进入if块,
- 此时先让thread1暂停,然后thread2进行offer插入值为1的节点后,thread2执行结束。
- 再让thread1执行,这时thread1并没有进行重试,而是代码继续往下走,返回null,尽管此时队列由于thread2已经插入了值为1的新的节点。
- 所以输出结果为thread0 poll的为null,然队列不为空队列。
因此,在判断队列是否为空队列的时候是不能通过线程在poll的时候返回为null进行判断的,可以通过isEmpty方法进行判断。
在offer过程中执行了poll
在分析offer方法的时候我们还留下了一个问题,即对offer方法中第11行代码的理解。
offer->poll->offer(在offer过程中,执行了poll)
在offer方法的第11行代码if (p == q),能够让if判断为true的情况为p指向的节点为哨兵节点,
而什么时候会构造哨兵节点呢?在对poll方法的讨论中,我们已经找到了答案,即
当head指向的节点的item域为null时会寻找真正的队头节点,等到待插入的节点插入之后,会更新head,并且将原来head指向的节点设置为哨兵节点。
假设队列初始状态如下图所示: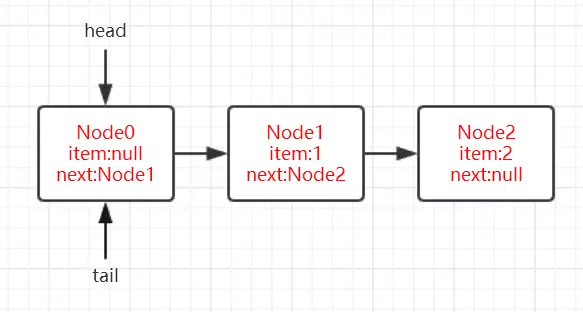
因此在线程A执行offer时,线程B执行poll就会存在如下一种情况: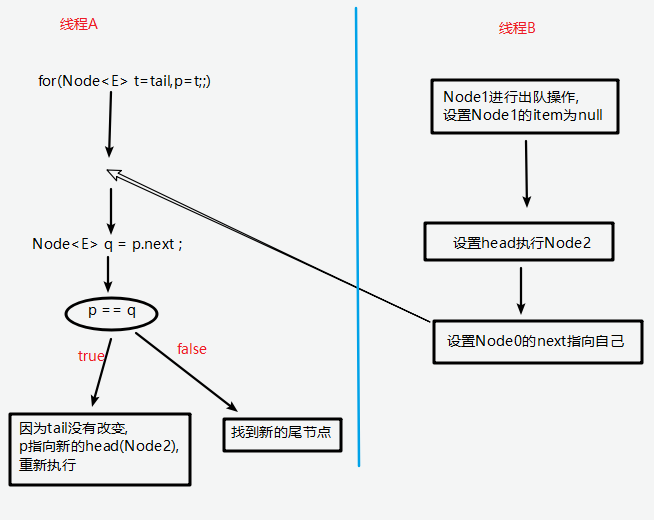
如图,
线程A执行q=p.next之前,线程B执行了poll,线程A再执行q=p.next就会导致p == q成立,
此时,队列状态为下图: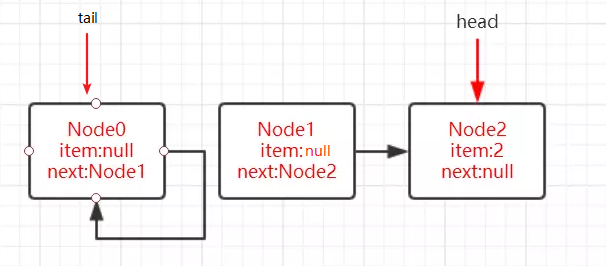
此时线程A在执行判断if (p == q)时就为true,会继续执行p = (t != (t = tail)) ? t : head;,由于tail指针没有发生改变所以p被赋值为head,从新的head(Node2)开始完成插入操作。
HOPS的设计
HOPS为HOP的复数,(hop two nodes at a time一次跳转两个节点)
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
offer插入,tail更新触发时机
当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail;
当tail指向的节点的下一个节点不为null的时候,会定位队列真正的尾节点,找到队尾节点后完成插入之后才会通过casTail进行tail更新.poll移出,head更新触发时机
当head指向的节点的item域不为null的时候,只删除(设置item为null)节点不更新head。
当head指向的节点的item域为null的时候,会定位队列真正的头节点,找到队头节点后完成删除(设置原head.next指向自己)之后才会通过updateHead进行head更新;
并且在更新操作时,源码中会有注释为:hop two nodes at a time一次跳转两个节点。
所以这种延迟更新的策略就被叫做HOPS的大概原因是这个(猜的),从上面更新时的状态图可以看出,head和tail的更新是“跳着的”即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。
但是,这样做有一个缺点:**如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。**
对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的。
我的理解offer,poll
结合两个方法来看,一遍看不懂那就看两遍.
1 | public boolean offer(E e) { |
1 | public E poll() { |
并发容器之ThreadLocal
关于本章的问题,关于内存处理的方法,下面四个会作为下一章(ThreadLocal内存泄漏问题)进行讲解
expungeStaleEntriesexpungeStaleEntrycleanSomeSlotsreplaceStaleEntry
本章只做简单描述,不作为探讨要点
ThreadLocal的简介
在多线程编程中通常我们会利用synchronzed或者lock控制线程对临界区资源的同步顺序从而解决线程安全的问题,但是这种加锁的方式会让未获取到锁的线程进行阻塞等待,很显然这种方式的时间效率并不是很好。线程安全问题的核心在于多个线程会对同一个临界区共享资源进行操作,那么,如果每个线程都使用自己的“共享资源”,各自使用各自的,又互相不影响到彼此即让多个线程间达到隔离的状态,这样就不会出现线程安全的问题。
事实上,每个线程都会都拥有自己的“共享资源”无疑内存会大很多,但是由于不需要同步,也就不会出现阻塞等待的情况,从而执行时间更短,程序执行更快了,但是会比以前耗内存。
虽然ThreadLocal并不在java.util.concurrent包中而在java.lang包中,但我更倾向于把它当作是一种并发容器(虽然真正存放数据的是ThreadLoclMap)进行归类。
从ThreadLocal这个类名可以顾名思义的进行理解,表示线程的“本地变量”,即每个线程都拥有该变量副本,达到人手一份的效果,各用各的这样就可以避免共享资源的竞争。
ThreadLocal的实现原理
要想学习到ThreadLocal的实现原理,就必须了解它的几个核心方法,包括怎样存取删等等,下面我们一个个来看。
set
set方法设置在当前线程中threadLocal变量的值,该方法的源码为:
1 | public void set(T value) { |
方法的逻辑很清晰,具体请看上面的注释。
通过源码我们知道value是存放在了ThreadLocalMap里了,当前先把它理解为一个普普通通的map即可,
也就是说,数据value是真正的存放在了ThreadLocalMap这个容器中了,并且是以当前threadLocal实例为key。
先简单的看下ThreadLocalMap是什么,有个简单的认识就好,下面会具体说的。
首先ThreadLocalMap是怎样来的?从刚才注释2来看,是通过getMap(t)进行获取:
1 | ThreadLocalMap getMap(Thread t) { |
该方法直接返回的就是当前线程对象t(Thread类)的一个成员变量threadLocals:
1 | /* ThreadLocal values pertaining to this thread. This map is maintained by the ThreadLocal class. */ |
看注释,回过头再来看看set方法,当map为null的时候会通过createMap(t,value)方法:
1 | void createMap(Thread t, T firstValue) { |
该方法就是new一个ThreadLocalMap实例对象,然后同样以当前threadLocal实例作为key,
值为传入的value存放到threadLocalMap中,然后将这个ThreadLocalMap实例对象赋值给当前线程对象的threadLocals。
set方法总结
- 通过当前线程对象thread获取该thread的变量threadLocals,也就是获取ThreadLocalMap,
- 若threadLocalMap不为null,则以threadLocal实例为key,值为value的键值对存入threadLocalMap,(set方法逻辑,后续会讲到)
- 若threadLocalMap为null的话,就新建threadLocalMap然后在以threadLocal为键,值为value的键值对存入即可。
get
get方法是获取当前线程中threadLocal变量的值,同样的还是来看看源码:
1 | public T get() { |
弄懂了set方法的逻辑,看get方法只需要带着逆向思维去看就好,如果是那样存的,反过来去拿就好。
代码逻辑请看注释,另外,看下setInitialValue主要做了些什么事情?
1 | private T setInitialValue() { |
1 | protected T initialValue() { |
这段方法的逻辑和set方法几乎一致,区别在于initialValue方法:
这个方法是protected修饰的也就是说继承ThreadLocal的子类可重写该方法,实现赋值为其他的初始值。
get方法总结
- 通过当前线程对象thread获取该thread的变量threadLocals,也就是获取ThreadLocalMap,
- 若threadLocalMap不为null,当前threadLocal实例为key获取该map中的键值对(Entry),若Entry不为null则返回Entry的value
- 若threadLocalMap为null或者Entry为null的话,就以当前threadLocal实例为key,value为null存入map后,并返回null。
remove
1 | public void remove() { |
- 删除数据是从map中删除数据,先获取与当前线程相关联的threadLocalMap,
- 然后map不为null的话,从map中删除该threadLocal实例为key的键值对即可
ThreadLocalMap详解
从上面的分析我们已经知道,数据其实都放在了threadLocalMap中,
threadLocal的get,set和remove方法实际上具体是通过threadLocalMap的getEntry,set和remove方法实现的。
如果想真正全方位的弄懂threadLocal,势必得在对threadLocalMap做一番理解。
Entry数据结构
ThreadLocalMap是ThreadLocal一个静态内部类,和大多数容器一样内部维护了一个数组,同样的threadLocalMap内部维护了一个Entry类型的table数组。
1 | /** |
通过注释可以看出,table数组的长度为2的幂次方。接下来看下Entry是什么:
1 | static class Entry extends WeakReference<ThreadLocal<?>> { |
Entry是一个以ThreadLocal为key,Object为value的键值对,
另外需要注意的是这里的threadLocal是弱引用,因为Entry继承了WeakReference(弱引用),在Entry的构造方法中,调用了super(k)方法就会将threadLocal实例包装成一个WeakReferenece。
到这里我们可以用一个图来理解下thread,threadLocal,threadLocalMap,Entry之间的关系:
注意上图中的实线表示强引用,虚线表示弱引用。
如图所示,每个线程实例中可以通过线程实例.threadLocals获取到threadLocalMap,而threadLocalMap实际上就是一个以threadLocal实例为key,传入值(任意对象)为value的Entry数组。
当我们为threadLocal变量赋值,实际上就是以当前threadLocal实例为key,值为value的Entry往这个threadLocalMap中存放。
需要注意这里存在的内存泄漏问题Entry中的key是弱引用,threadLocal外部强引用被置为null(也就是New一个ThreadLocal对象,并设置实例对象为null)或new了这个ThreadLocal对象之后未被使用,那么系统 GC 的时候,根据可达性分析,这个threadLocal实例就没有任何一条链路能够引用到它,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null(因为设置了ThreadLocal的实例对象为null)的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话(例如放入了线程池),这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> threadLocals -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
当然,如果当前thread运行结束,threadLocal,threadLocalMap,Entry没有引用链可达,在垃圾回收的时候都会被系统进行回收。
在实际开发中,会使用线程池去维护线程的创建和复用,比如固定大小的线程池,线程为了复用是不会主动结束的,
所以,threadLocal的内存泄漏问题,是应该值得我们思考和注意的问题,关于这个问题可以看下一篇文章详解threadLocal内存泄漏问题
散列表(Hash Table),也称为哈希表
与concurrentHashMap,hashMap等容器一样,threadLocalMap也是采用散列表进行实现的。
在了解set方法前,我们先来回顾下关于散列表相关的知识.
理想状态下,散列表就是一个包含关键字(key)的固定大小的数组,通过使用散列函数,将关键字映射到数组的不同位置。
下面是存放k v的散列表,数组长度为10
在理想状态下,哈希函数可以将关键字均匀的分散到数组的不同位置,不会出现两个关键字散列值相同的情况。(假设关键字(key)数量小于数组的长度)
但是在实际使用中,经常会出现多个关键字散列值相同的情况(被映射到数组的同一个位置),我们将这种情况称为散列冲突。
为了解决散列冲突,主要采用下面两种方式:
- 分离链表法(separate chaining)
- 开放定址法(open addressing)
1. 分离链表法
分散链表法使用链表解决冲突,将散列值相同的元素(通过哈希函数处理后的值相同)都保存到一个链表中。
当查询的时候,首先找到元素所在的链表,然后遍历链表查找对应的元素,典型实现为hashMap,concurrentHashMap的拉链法。
下面是一个示意图:
2. 开放定址法
开放定址法不会创建链表,当关键字散列到的数组单元已经被另外一个关键字占用的时候(通过哈希函数处理后的值相同),就会尝试在数组中寻找其他的单元,直到找到一个空的单元。
探测数组空单元的方式有很多,这里介绍一种最简单的线性探测法从冲突的数组单元开始,依次往后搜索空单元,如果到数组尾部,再从头开始搜索(环形查找),直到搜索都空单元为止
如下图所示:
ThreadLocalMap中使用开放地址法来处理散列冲突,而HashMap中使用的分离链表法。
之所以采用不同的方式主要是因为:
- 在 ThreadLocalMap 中的散列值分散的十分均匀,很少会出现冲突。
- 并且 ThreadLocalMap 经常需要清除无用的对象,使用纯数组更加方便。
set方法
1 | private void set(ThreadLocal<?> key, Object value) { |
set方法的关键部分请看上面的注释,主要有这样几点需要注意:
- threadLocal的hashcode怎么计算?从源码中我们可以清楚的看到threadLocal实例的hashCode是通过nextHashCode()方法实现的,该方法实际上总是用一个AtomicInteger的getAndAdd(原子操作)方法传入0x61c88647来实现的。
1
2
3
4
5
6
7
8
9
10private final int threadLocalHashCode = nextHashCode();
private static AtomicInteger nextHashCode =
new AtomicInteger();
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
0x61c88647这个数是有特殊意义的,它能够保证hash表的每个散列桶能够均匀的分布,这是Fibonacci Hashing(斐波那契哈希),
也正是能够均匀分布,所以threadLocal选择使用开放地址法来解决hash冲突的问题。
为什么能够均匀分布,做个小测试
- 实例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public static void main(String[] args) throws Exception
{
testGetAndAdd(8);
testGetAndAdd(16);
testGetAndAdd(32);
}
public static void testGetAndAdd(Integer len)
{
AtomicInteger atomicInteger = new AtomicInteger();
int hash_increment = 0x61c88647;
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < len; i++)
{
arrayList.add(atomicInteger.getAndAdd(hash_increment) & (len - 1));
}
System.out.println();
System.out.println(len + "排序前: " + arrayList);
Collections.sort(arrayList);
System.out.println(len + "排序后: " + arrayList);
} - 执行结果

- 怎样确定新值插入到哈希表中的位置?
该操作源码为:key.threadLocalHashCode & (len-1),同hashMap和ConcurrentHashMap等容器的方式一样,
利用当前key(即threadLocal实例)的hashcode与哈希表大小相与,因为哈希表大小总是为2的幂次方,所以相与等同于一个取模的过程,这样就可以通过Key分配到具体的哈希桶中去。而至于为什么取模要通过位与运算的原因就是位运算的执行效率远远高于了取模运算。1
2
3
4
5
6
720%8=4 就相当于 20&(8-1)=4
10100=20
&(同为1才为1)
00111=8-1
-----
00100=4 - 怎样解决hash冲突?源码中通过
1
2
3private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}nextIndex(i, len)方法解决hash冲突的问题,该方法为((i + 1 < len) ? i + 1 : 0);,也就是不断往后线性探测,当到哈希表末尾的时候再从0开始,成环形。 - 怎样解决“脏”Entry?
在分析threadLocal,threadLocalMap以及Entry的关系的时候,我们已经知道使用threadLocal有可能存在内存泄漏
(对象创建出来后,在之后的逻辑一直没有使用该对象或设置了这个New的ThreadLocal实例对象为null,但是垃圾回收器无法回收这个部分的内存,上面在Entry数据结构已经分析了)
在源码中针对这种key为null的Entry称之为“stale entry(不新鲜的entry)”,我把它理解为“脏entry”,
自然而然,Josh Bloch and Doug Lea大师考虑到了这种情况,在set方法的for循环中寻找和当前Key相同的可覆盖entry的过程中通过replaceStaleEntry方法解决脏entry的问题。
如果当前table[i]为null的话,直接插入新entry后也会通过cleanSomeSlots来解决脏entry的问题, - 如何进行扩容?
1
2
3
4
5
6
7
8
9
10
11
12...
//5. 新建entry并插入table中i处,新增之后大小+1
tab[i] = new Entry(key, value);
int sz = ++size;
//6.
//插入后再次清除一些key为null的“脏”entry,如果大于阈值就需要扩容
//阈值=2/3 len长度,当size=>3/4阈值时,进行扩容,也就是size>=(2/3)*(3/4)=1/2 len长度
//扩容size为原本的len长度的二倍,阈值再设为2/3 size
//关于cleanSomeSlots与rehash后续会讲到
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}threshold(阈值)的确定
根据threshold(阈值)的确定,因为在插入了新Entry之后,
(在Table[]数组中,Entry不为null的大小就是size)size的大小增加了1,如果size>=threshold阈值,就需要扩容
1 | private int threshold; // 默认为0 |
rehash();方法
1 | private void rehash() { |
扩容resize(size是数组中不为null的Entry数量)
从set方法中可以看出当hash表的size大于threshold的时候,会通过resize方法进行扩容。
1 | /** |
方法逻辑请看注释,新建一个大小为原来数组长度的两倍的数组,然后遍历旧数组中的entry并将其插入到新的hash数组中,
主要注意的是,在扩容的过程中针对脏entry的话会令value为null,以便能够被垃圾回收器能够回收,解决隐藏的内存泄漏的问题。
getEntry方法
getEntry方法源码为:
1 | private Entry getEntry(ThreadLocal<?> key) { |
方法逻辑很简单,若能当前定位的entry的key和查找的key相同的话就直接返回这个entry,
否则的话就是在set的时候存在hash冲突的情况,需要通过getEntryAfterMiss做进一步处理。
getEntryAfterMiss方法为:
1 | private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { |
这个方法同样很好理解,通过nextIndex往后环形查找,如果找到和查询的key相同的entry的话就直接返回,如果在查找过程中遇到脏entry的话使用expungeStaleEntry方法进行处理。
到目前为止,为了解决潜在的内存泄漏的问题,在set,resize,getEntry这些地方都会对这些脏entry进行处理,可见为了尽可能解决这个问题几乎无时无刻都在做出努力。
remove
1 | /** |
该方法逻辑很简单,通过往后环形查找到与指定key相同的entry后,先通过clear方法将key置为null后,使其转换为一个脏entry,
然后调用expungeStaleEntry方法将其value置为null,以便垃圾回收时能够清理,同时将table[i]置为null。
ThreadLocal的使用场景
最常见的ThreadLocal使用场景为 用来解决 数据库连接、Session管理等。
ThreadLocal 不是用来解决共享对象的多线程访问问题的,数据实质上是放在每个thread实例引用的threadLocalMap,也就是说每个不同的线程都拥有专属于自己的数据容器(threadLocalMap),彼此不影响。
因此threadLocal只适用于共享对象会造成线程安全的业务场景。
比如hibernate中通过threadLocal管理Session就是一个典型的案例,不同的请求线程(用户)拥有自己的session,若将session共享出去被多线程访问,必然会带来线程安全问题。
例子1,SimpleDateFormat
下面,我们自己来写一个例子,SimpleDateFormat.parse方法会有线程安全的问题,我们可以尝试使用threadLocal包装SimpleDateFormat,将该实例不被多线程共享即可。
1 | public class ThreadLocalDemo { |
- 如果当前线程不持有SimpleDateformat对象实例,那么就新建一个并把它设置到当前线程中,如果已经持有,就直接使用。另外,从
if (sdf.get() == null){....}else{.....}可以看出为每一个线程分配一个SimpleDateformat对象实例是从应用层面(业务代码逻辑)去保证的。 - 在上面我们说过threadLocal有可能存在内存泄漏,在使用完之后,最好使用remove方法将这个变量移除,就像在使用数据库连接一样,及时关闭连接。
例子2,Session
1 | private static ThreadLocal < Connection > connectionHolder = new ThreadLocal < Connection > () { |
1 | private static final ThreadLocal threadSession = new ThreadLocal(); |
一篇文章,从源码深入详解ThreadLocal内存泄漏问题
造成内存泄漏的原因?
threadLocal是为了解决对象不能被多线程共享访问的问题,通过threadLocal.set方法将对象实例保存在每个线程自己所拥有的threadLocalMap中,
这样每个线程使用自己的对象实例,彼此不会影响达到隔离的作用,从而就解决了对象在被共享访问带来线程安全问题。
简单说,同步机制就是通过控制线程访问共享对象的顺序,而threadLocal就是为每一个线程分配一个该对象,各用各的互不影响。
打个比方说,现在有100个同学需要填写一张表格但是只有一支笔,同步就相当于A使用完这支笔后给B,B使用后给C用……老师就控制着这支笔的使用顺序,使得同学之间不会产生冲突。threadLocal就相当于,老师直接准备了100支笔,这样每个同学都使用自己的,同学之间就不会产生冲突。
很显然这就是两种不同的思路,同步机制由于每个线程在同一时刻共享对象只能被一个线程访问造成整体上响应时间增加,但是对象只占有一份内存,牺牲了时间效率换来了空间效率即“时间换空间”。threadLocal为每个线程都分配了一份对象,自然而然内存使用率增加,每个线程各用各的,整体上时间效率要增加很多,牺牲了空间效率换来时间效率即“空间换时间”。
关于threadLocal,threadLocalMap更多的细节可以看上篇文章,给出了很详细的各个方面的知识(很多也是面试高频考点)。
threadLocal,threadLocalMap,entry之间的关系如下图所示: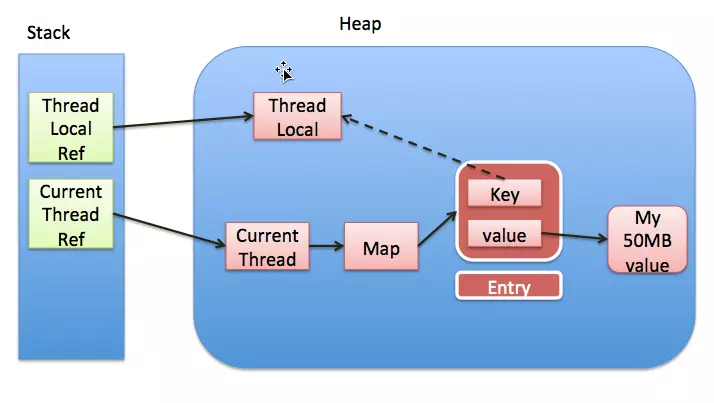
注意上图中的实线表示强引用,虚线表示弱引用。
如图所示,每个线程实例中可以通过线程实例.threadLocals获取到threadLocalMap,而threadLocalMap实际上就是一个以threadLocal实例为key,传入值(任意对象)为value的Entry数组。
当我们为threadLocal变量赋值,实际上就是以当前threadLocal实例为key,值为value的Entry往这个threadLocalMap中存放。
需要注意这里存在的内存泄漏问题Entry中的key是弱引用,threadLocal外部强引用被置为null(也就是New一个ThreadLocal对象,并设置实例对象为null)或new了这个ThreadLocal对象之后未被使用,那么系统 GC 的时候,根据可达性分析,这个threadLocal实例就没有任何一条链路能够引用到它,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null(因为设置了ThreadLocal的实例对象为null)的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话(例如放入了线程池),这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> threadLocals -> ThreaLocalMap -> Entry -> value永远无法回收,造成内存泄漏。
当然,如果当前thread运行结束,threadLocal,threadLocalMap,Entry没有引用链可达,在垃圾回收的时候都会被系统进行回收。
在实际开发中,会使用线程池去维护线程的创建和复用,比如固定大小的线程池,线程为了复用是不会主动结束的,所以threadLocal内存泄漏就值得我们关注。
已经做出了哪些改进?
实际上,为了解决threadLocal潜在的内存泄漏的问题,Josh Bloch and Doug Lea大师已经做了一些改进,在threadLocal的set和get等方法中都有相应的处理。
下文为了叙述,针对key为null的entry,源码注释为stale entry,直译为不新鲜的entry,这里我就称之为“脏entry”。
ThreadLocalMap的set方法
1 | private void set(ThreadLocal<?> key, Object value) { |
在该方法中针对脏entry做了这样的处理:
- 如果当前
table[i]!=null的话说明hash冲突就需要向后环形查找,若在查找过程中遇到脏entry就通过replaceStaleEntry进行处理; - 如果当前
table[i]==null的话说明新的entry可以直接插入,但是插入后会调用cleanSomeSlots方法检测并清除脏entry
cleanSomeSlots
1 | private boolean cleanSomeSlots(int i, int n) { |
传入的参数:
- 第一个参数 i 表示:在ThreadLocalMap的set方法中插入的位置,但是这个插入是
Table[i]==null的情况下插入的,所以不会是脏entry. - 第二个参数 n
- 用于循环控制,从while中通过n来控制循环次数.
如果循环log2(n)次,没有遇到脏entry
在扫描过程中,也就是if (e != null && e.get() == null)为false,n就不会重新赋值为len.
这时n的改变,也可说是循环次数的控制条件就是(n >>>= 1) != 0,它其实是保护两行代码n = n >>> 1;和n != 0;
其中n>>>1的具体意思可以查看>>>位右移
循环的次数相当于log2(n)(2³=8,log2(8)=3),log2(n)的得来是因为n >>>= 1,每次n右移一位相当于n除以2取整。遇到脏entry
此时n=len,就会重新被赋值,也就是重新再循环log2(n’)次,使nextIndex继续环形清理脏entry.
注意此时的n为数组的长度,而不是size
按照n的初始值,搜索范围为黑线,当遇到了脏entry,此时n变成了哈希数组的长度(n取值增大),搜索范围log2(n)增大,红线表示。
如果在整个搜索过程没遇到脏entry的话,搜索结束。
- n的取值
如果是在set方法插入新的entry后调用,n位当前已经插入的entry个数size(entry不为null的数量),
如果是在set方法中的replaceSateleEntry方法中调用,传入的n就为哈希表的长度len。
- 用于循环控制,从while中通过n来控制循环次数.
expungeStaleEntry
如果对输入参数能够理解的话,那么cleanSomeSlots方法搜索基本上清楚了,
但是全部搞定还需要掌握expungeStaleEntry方法,当在搜索过程中遇到了脏entry的话就会调用该方法去清理掉脏entry。
源码为:
1 | private int expungeStaleEntry(int staleSlot) { |
- 简要说明
expungeStaleEntry方法不止清理了staleSlot位置上的entry,还把staleSlot之后的key为null的entry都清理了,并且顺带将一些有哈希冲突的entry给填充回可用的index中。 - else块表示的意思,再做解释
1
2
3
4
5
6
7
8
9
10假设之前这个key(循环位置i获取到entry的key),也就是ThreadLocal变量定位的位置是7,7这个位置的entry不是null,
也就是有了其他的数据,这时候也就哈希冲突了,它就会插入到后面为null的地方,假设它插入了14的位置,
进入这个方法,假设12 13位置的entry不为null,key为null,则会清理脏entry,
这时候,循环到i = 14,它不是脏entry,重新定位是7,把14的数据设为null,
这时7是有数据的,所以它又回不到真正定位的位置了,只能往后插入,
这时候判断到12的时候,它是null,可以插入这个位置,把14的数据赋值到12的位置.
总结:把因为冲突而移动的entry移动的真正定位的位置,如果真正定位的位置有数据,就尽可能往前移.
目的:暂时想不明白.(猜想:由key获取数据的速度更快了,因为nextIndex的循环次数少了.))
cleanSomeSlot方法总结
其方法执行示意图如下:
如图所示,cleanSomeSlot方法主要有这样几点:
- 从当前位置i处(位于i处的entry一定不是脏entry)为起点在初始小范围(log2(n),n为entry不为null的数量)开始向后搜索脏entry,若在整个搜索过程没有脏entry,方法结束退出
- 如果在搜索过程中遇到脏entryt通过expungeStaleEntry方法清理掉当前脏entry(并且还会清理之后的脏entry,直到循环
table[i] == null时结束循环),并且该方法会返回下一个entry为null的索引位置为i。
这时重新令搜索起点为索引位置i,n为哈希表的长度len,再次扩大搜索范围为log2(n’)继续搜索(此时的n’不等于之前的n)。 - 返回值问题,发现entry返回true,没发现返回false.
举个例子说明cleanSomeSlot方法
下面,以一个例子更清晰的来说一下,假设当前table数组的情况如下图。
- 如图当前n等于hash表的size即n=10,i=1,在第一趟搜索过程中通过nextIndex,i指向了索引为2的位置,此时
table[2]为null,说明第一趟未发现脏entry,则第一趟结束进行第二趟的搜索。 - 第二趟所搜先通过nextIndex方法,索引由2的位置变成了i=3,当前table[3]!=null但是该entry的key为null,说明找到了一个脏entry,
先将n置为哈希表的长度len,然后继续调用expungeStaleEntry方法,该方法会将当前索引为3的脏entry给清除掉(设置value为null,并且table[3]也为null),
但是该方法可不想偷懒,它会继续往后环形搜索,往后会发现索引为4,5的位置的entry同样为脏entry,进行清除,索引为6的位置的entry不是脏entry(操作逻辑看expungeStaleEntry方法的else块解释),
直至i=7的时候此处table[7]位null,该方法就以i=7返回。至此,第二趟搜索结束;
3. 由于在第二趟搜索中发现脏entry,n增大为数组的长度len,因此扩大搜索范围(增大循环次数,为log2(len))继续向后环形搜索;
4. 如果在存在log2(len)次中,又发现了脏entry,会继续重复上述步骤,把n再设置为len,再往后循环log2(len)次,如果未发现脏entry,cleanSomeSlot方法执行结束退出。
理解了上面所介绍的cleanSomeSlot方法,我们来看看下面
1 | private void set(ThreadLocal<?> key, Object value) { |
1 | private void rehash() { |
1 | private void expungeStaleEntries() { |
replaceStaleEntry
1 | private void replaceStaleEntry(ThreadLocal<?> key, Object value, |
具体含义都写在注释里面了,具体要理解进入这个方法的条件是什么,传入的参数是什么意思.重要记住:其中的slotToExpunge一直都表示table数组中第一个脏entry.进入的条件:是因为当前key通过key.threadLocalHashCode & (len-1);定位的位置已经有数据存在,
只能往定位的位置后遍历,寻找entry为null的位置进行插入新数据,在寻找的途中遇到的脏entry才会进入此方法.
所以replaceStaleEntry方法的作用:
- 插入你传入的数据
- 清除脏entry
之前我们讲到,
当我们
调用threadLocal的get方法时,当table[i]不是和所要找的key相同的话,
会继续通过threadLocalMap的getEntryAfterMiss方法向后环形去找,
当key==null的时候,即遇到脏entry也会调用expungeStleEntry对脏entry进行清理。
具体方法为: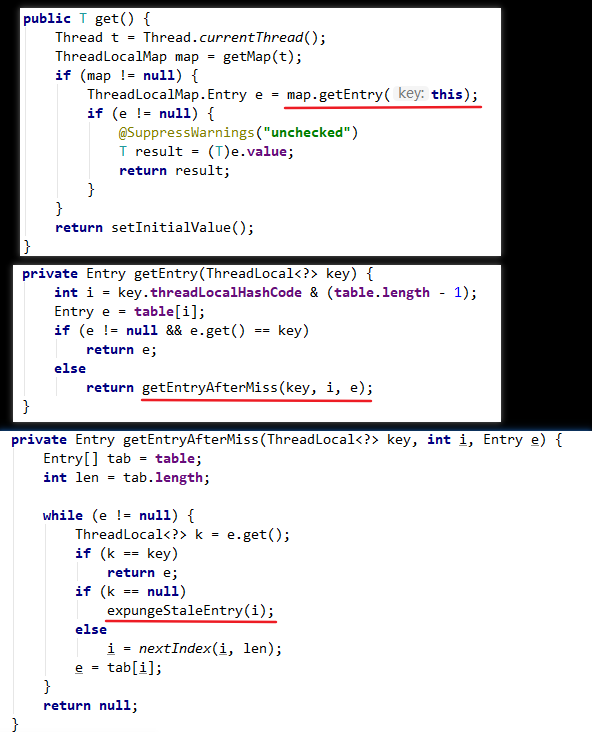
当我们
调用threadLocal.remove方法时,实际上会调用threadLocalMap的remove方法,
同样的可以看出,当遇到了key为null的脏entry的时候,也会调用expungeStaleEntry清理掉脏entry。
为什么使用弱引用?
从文章开头通过threadLocal,threadLocalMap,entry的引用关系看起来threadLocal存在内存泄漏的问题似乎是因为threadLocal是被弱引用修饰的。
那为什么要使用弱引用呢?
如果使用强引用
假设threadLocal使用的是强引用,在业务代码中执行threadLocal实例对象==null操作,以清理掉threadLocal实例的目的,
但是因为threadLocalMap的Entry强引用threadLocal,因此在gc的时候进行可达性分析,threadLocal依然可达,对threadLocal并不会进行垃圾回收,
这样就无法真正达到业务逻辑的目的,出现逻辑错误.(不想使用,也无法清除,依然占内存)如果使用弱引用
假设Entry弱引用threadLocal,尽管会出现内存泄漏的问题,
但是在threadLocal的生命周期里(set,getEntry,remove)里,都会针对key为null的脏entry进行处理。
答:从以上的分析可以看出,使用弱引用的话在threadLocal生命周期里会尽可能的保证不出现内存泄漏的问题,达到安全的状态。
Thread.exit()
1 | /** |
从源码可以看出当线程结束时,会令threadLocals=null,也就意味着GC的时候就可以将threadLocalMap进行垃圾回收,
换句话说threadLocalMap生命周期实际上thread的生命周期相同(线程结束则结束)。
threadLocal最佳实践
通过这篇文章对threadLocal的内存泄漏做了很详细的分析,我们可以完全理解threadLocal内存泄漏的前因后果,那么实践中我们应该怎么做?
- 每次使用完ThreadLocal,都调用它的remove()方法,清除数据。
- 在使用线程池的情况下,没有及时清理ThreadLocal,不仅是内存泄漏的问题,更严重的是可能导致业务逻辑出现问题。所以,使用ThreadLocal就跟加锁完要解锁一样,用完就清理。
ThreadLocal结语
把这两部分看了,基本就可以领略其中的奥义了,
看完之后,再从ThreadLocal里面的set,get,remove里面的方法都点进去看看,搞懂里面的顺序,
想想程序为什么这样设计,想不明白,百度一下看看能不能从中找出答案.
并发容器之BlockingQueue
BlockingQueue简介
在实际编程中,会经常使用到JDK中Collection集合框架中的各种容器类如实现List,Map,Queue接口的容器类,
但是这些容器类基本上不是线程安全的,除了使用Collections可以将其转换为线程安全的容器,Doug Lea大师为我们都准备了对应的线程安全的容器,
如实现List接口的CopyOnWriteArrayList,实现Map接口的ConcurrentHashMap,实现Queue接口的ConcurrentLinkedQueue
最常用的“生产者-消费者”问题中,队列通常被视作线程间操作的数据容器,这样,可以对各个模块的业务功能进行解耦,
生产者将“生产”出来的数据放置在数据容器中,而消费者仅仅只需要在“数据容器”中进行获取数据即可,这样生产者线程和消费者线程就能够进行解耦,只专注于自己的业务功能即可。
阻塞队列(BlockingQueue)被广泛使用在“生产者-消费者”问题中,其原因是BlockingQueue提供了可阻塞的插入和移除的方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
基本操作
- 插入元素
boolean add(E e);往队列插入数据成功返回true;当队列满时,插入元素时会抛出IllegalStateException异常;boolean offer(E e);当往队列插入数据时,插入成功返回true,否则则返回false。当队列满时也不会抛出异常;void put(E e) throws InterruptedException;当阻塞队列容量已经满时,往阻塞队列插入数据的线程会被阻塞,直至阻塞队列已经有空余的容量可供使用;boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;若阻塞队列已经满时,同样会阻塞插入数据的线程,直至阻塞队列已经有空余的地方,与put方法不同的是,该方法会有一个超时时间,若超过当前给定的超时时间,插入数据的线程会退出; - 删除元素
boolean remove(Object o);从队列中删除数据,成功则返回true,否则为falseE poll();从队列中取数据(设为null)并返回;如果队列为空返回null;E take() throws InterruptedException;当阻塞队列为空时,获取队头数据的线程会被阻塞;E poll(long timeout, TimeUnit unit) throws InterruptedException;当阻塞队列为空时,获取数据的线程会被阻塞,另外,如果被阻塞的线程超过了给定的时长,该线程会退出 - 查看元素
E element();检索但不删除头元素;若队列为空,则抛 NoSuchElementException异常;E peek();检索但不删除头元素;若队列为空,则返回 null。
常用的BlockingQueue
实现BlockingQueue接口的有ArrayBlockingQueue DelayQueue LinkedBlockingDequeLinkedBlockingQueue LinkedTransferQueue PriorityBlockingQueue SynchronousQueue
而这几种常见的阻塞队列也是在实际编程中会常用的,下面对这几种常见的阻塞队列进行说明:
ArrayBlockingQueue
由数组实现的有界阻塞队列。FIFO(先进先出)。
因此,对头元素时队列中存在时间最长的数据元素,而对尾数据则是当前队列最新的数据元素。
ArrayBlockingQueue可作为“临界区”,生产者插入数据到队列容器中,并由消费者提取。
ArrayBlockingQueue一旦创建,容量不能改变。
当队列容量满时,尝试将元素放入队列将导致操作阻塞;
尝试从一个空队列中取一个元素也会同样阻塞。
ArrayBlockingQueue默认是非公平的.公平锁: 每次取等待队列的第一个节点,FIFO.非公平锁: 随机的,可能导致其他线程永远无法获得锁.
保证公平性会降低吞吐量.
LinkedBlockingQueue
用链表实现的有界阻塞队列,同样满足FIFO的特性,比ArrayBlockingQueue吞吐量还大.
为了防止LinkedBlockingQueue容量迅速增,从而损耗大量内存,通常在创建LinkedBlockingQueue对象时,会指定其大小;如果未指定,容量等于Integer.MAX_VALUE
PriorityBlockingQueue
一个支持优先级的无界阻塞队列。
默认情况下元素采用自然顺序进行排序,也可以通过自定义类实现compareTo()方法来指定元素排序规则,或 初始化时通过构造器参数Comparator来指定排序规则。
SynchronousQueue
每个插入操作必须等待另一个线程进行相应的删除操作.
因此,SynchronousQueue实际上没有存储任何数据元素,因为只有线程在删除数据时,其他线程才能插入数据,同样的,如果当前有线程在插入数据时,线程才能删除数据。
SynchronousQueue也可以通过构造器参数来为其指定公平性。
LinkedTransferQueue
一个由链表数据结构构成的无界阻塞队列.
由于该队列实现了TransferQueue接口,与其他阻塞队列相比主要有以下不同的方法:
void transfer(E e) throws InterruptedException;
如果当前有线程(消费者)正在调用take()方法或者可延时的poll()方法进行消费数据时,生产者线程可以调用transfer方法将数据传递给消费者线程。
如果当前没有消费者线程的话,生产者线程就会将数据插入到队尾,直到有消费者能够进行消费才能退出;boolean tryTransfer(E e);
如果当前有消费者线程(调用take方法或者具有超时特性的poll方法)正在消费数据的话,该方法可以将数据立即传送给消费者线程;
如果当前没有消费者线程消费数据的话,就立即返回false。
因此,transfer方法是必须等到有消费者线程消费数据时,生产者线程才能够返回。而tryTransfer方法能够立即返回结果退出。boolean tryTransfer(E e, long timeout, TimeUnit unit) throws InterruptedException;
与transfer基本功能一样,只是增加了超时特性.
如果规定的超时时间内没有消费者进行消费的话,就返回false。
LinkedBlockingDeque
基于链表数据结构的有界阻塞双端队列.
可在创建对象时来指定大小,其默认为Integer.MAX_VALUE。
与LinkedBlockingQueue相比,主要的不同点在于:LinkedBlockingDeque具有双端队列的特性。
LinkedBlockingDeque基本操作如下图所示(来源于java文档)
如上图所示,LinkedBlockingDeque的基本操作可以分为四种类型:
- 特殊情况,抛出异常;
- 特殊情况,返回特殊值如null或者false;
- 当线程不满足操作条件时,线程会被阻塞直至条件满足;
- 操作具有超时特性。
另外,LinkedBlockingDeque实现了BlockingDueue接口,而LinkedBlockingQueue实现的是BlockingQueue,
这两个接口的主要区别如下图所示(来源于java文档):
从上图可以看出,两个接口的功能是可以等价使用的,比如BlockingQueue的add方法和BlockingDeque的addLast方法的功能是一样的。
DelayQueue
一个存放实现Delayed接口的数据的无界阻塞队列,只有当数据对象的延时时间达到时才能插入到队列进行存储。
如果当前所有的数据都还没有达到创建时所指定的延时期,则队列没有队头,并且线程通过poll等方法获取数据元素则返回null。
所谓数据延时期满时,则是通过Delayed接口的getDelay(TimeUnit.NANOSECONDS)来进行判定,如果该方法返回的是小于等于0则说明该数据元素的延时期已满。
并发容器之ArrayBlockingQueue和LinkedBlockingQueue实现原理详解
在多线程编程过程中,为了业务解耦和架构设计,经常会使用并发容器用于存储多线程间的共享数据,这样不仅可以保证线程安全,还可以简化各个线程操作。
例如在“生产者-消费者”问题中,会使用阻塞队列(BlockingQueue)作为数据容器。
为了加深对阻塞队列的理解,唯一的方式是对其实验原理进行理解.
接下来就主要来看看ArrayBlockingQueue和LinkedBlockingQueue的实现原理。
ArrayBlockingQueue
8方法简介
1 | ArrayBlockingQueue |
一个例子
代码比较简单, Consumer 消费者和 Producer 生产者,通过ArrayBlockingQueue 队列获取和添加元素.
其中消费者调用了take()方法获取元素当队列没有元素就阻塞,生产者调用put()方法添加元素,当队列满时就阻塞,通过这种方式便实现生产者消费者模式。
比直接使用等待唤醒机制或者Condition条件队列来得更加简单。
- 实例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.TimeUnit;
public class ArrayBlockingQueueDemo {
private final static ArrayBlockingQueue<Apple> queue= new ArrayBlockingQueue<>(1);
public static void main(String[] args){
new Thread(new Producer(queue)).start();
new Thread(new Producer(queue)).start();
new Thread(new Consumer(queue)).start();
new Thread(new Consumer(queue)).start();
}
}
class Apple {
public Apple(){
}
}
/**
* 生产者线程
*/
class Producer implements Runnable{
private final ArrayBlockingQueue<Apple> mAbq;
Producer(ArrayBlockingQueue<Apple> arrayBlockingQueue){
this.mAbq = arrayBlockingQueue;
}
public void run() {
while (true) {
Produce();
}
}
private void Produce(){
try {
Apple apple = new Apple();
mAbq.put(apple);
System.out.println("生产:"+apple);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
/**
* 消费者线程
*/
class Consumer implements Runnable{
private ArrayBlockingQueue<Apple> mAbq;
Consumer(ArrayBlockingQueue<Apple> arrayBlockingQueue){
this.mAbq = arrayBlockingQueue;
}
public void run() {
while (true){
try {
TimeUnit.MILLISECONDS.sleep(1000);
comsume();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private void comsume() throws InterruptedException {
Apple apple = mAbq.take();
System.out.println("消费Apple="+apple);
}
} - 打印结果
1
2
3
4
5
6
7生产:com.zejian.concurrencys.Queue.Apple@109967f
消费Apple=com.zejian.concurrencys.Queue.Apple@109967f
生产:com.zejian.concurrencys.Queue.Apple@269a77
生产:com.zejian.concurrencys.Queue.Apple@1ce746e
消费Apple=com.zejian.concurrencys.Queue.Apple@269a77
消费Apple=com.zejian.concurrencys.Queue.Apple@1ce746e
...
实现原理
阻塞队列最核心的功能是:能够可阻塞式的插入和删除队列元素。
当队列为空,会阻塞消费数据的线程,直至队列非空时,通知被阻塞的线程;
当队列满时,会阻塞插入数据的线程,直至队列未满时,通知插入数据的线程(生产者线程)。
那么,多线程中消息通知机制最常用的是lock的condition机制.
ArrayBlockingQueue的实现是不是也会采用Condition的通知机制呢?下面来看看。
主要属性
- 主要属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** 存储数据的数组 */
final Object[] items;
/**获取数据的索引,主要用于take,poll,peek,remove方法 */
int takeIndex;
/**添加数据的索引,主要用于 put, offer, or add 方法*/
int putIndex;
/** 队列元素的个数 */
int count;
/** 控制并非访问的锁 */
final ReentrantLock lock;
/**notEmpty条件对象,用于通知take方法队列已有元素,可执行获取操作 */
private final Condition notEmpty;
/**notFull条件对象,用于通知put方法队列未满,可执行添加操作 */
private final Condition notFull;
/**迭代器 */
transient Itrs itrs = null;
...
} - 可以看出ArrayBlockingQueue内部是采用数组进行数据存储的(属性items),
- 为了保证线程安全,采用的是ReentrantLock lock,
值得注意的是ArrayBlockingQueue通过一个ReentrantLock来同时控制添加线程与移除线程的并非访问,这点与LinkedBlockingQueue区别很大(稍后会分析)。 - 为了保证可阻塞式的插入删除数据利用的是Condition,
而对于notEmpty条件对象则是用于存放等待或唤醒调用take方法的线程,告诉他们队列已有元素,可以执行获取操作。
同理notFull条件对象是用于等待或唤醒调用put方法的线程,告诉它们,队列未满,可以执行添加元素的操作。 - takeIndex代表的是下一个方法(take,poll,peek,remove)被调用时获取数组元素的索引
putIndex则代表下一个方法(put, offer, or add)被调用时元素添加到数组中的索引。
而notEmpty和notFull等中要属性在构造方法中进行创建:
构造方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14//默认非公平
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
//可指定公平性
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}其他方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//自动移除此队列中的所有元素。
void clear()
//如果此队列包含指定的元素,则返回 true。
boolean contains(Object o)
//移除此队列中所有可用的元素,并将它们添加到给定collection中。
int drainTo(Collection<? super E> c)
//最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定collection 中。
int drainTo(Collection<? super E> c, int maxElements)
//返回在此队列中的元素上按适当顺序进行迭代的迭代器。
Iterator<E> iterator()
//返回队列还能添加元素的数量
int remainingCapacity()
//返回此队列中元素的数量。
int size()
//返回一个按适当顺序包含此队列中所有元素的数组。
Object[] toArray()
//返回一个按适当顺序包含此队列中所有元素的数组;返回数组的运行时类型是指定数组的运行时类型。
<T> T[] toArray(T[] a)put方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public void put(E e) throws InterruptedException {
//1. 数据为null抛异常NullPointerException
checkNotNull(e);
final ReentrantLock lock = this.lock;
//2. 中断式获取锁
lock.lockInterruptibly();
try {
//3. 如果队列已满,则等待
while (count == items.length)
notFull.await();
//4. 如果不满,插入数据
enqueue(e);
} finally {
//5. 最后再释放锁
lock.unlock();
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14private void enqueue(E x) {
final Object[] items = this.items;
//1. 在指定位置插入数据
items[putIndex] = x;
//2. putIndex索引自增
// 如果已是最后一个位置,重新设为第一个位置
if (++putIndex == items.length)
putIndex = 0;
//3. 队列元素数量+1
count++;
//4. 唤醒调用take()方法的线程
// 已有元素存在,不为空了,可以执行获取操作
notEmpty.signal();
}为什么是最后一个位置,要设置
putIndex = 0;?
一直插入,putIndex一直增大,当指向最后一个位置时,此时后面就没有可插入的位置了,只能向前指向,
因为FIFO(First In First Out 先进先出),如果可以插入,前面第一个肯定有位置,这时就应该指向第一个位置.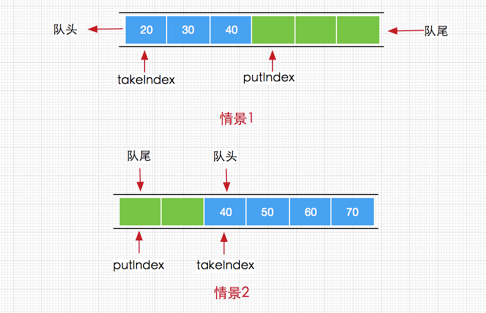
take方法
1 | public E take() throws InterruptedException { |
1 | private E dequeue() { |
从以上分析,可以看出put和take方法主要是通过condition的通知机制来完成可阻塞式的插入数据和获取数据。
在理解ArrayBlockingQueue后再去理解LinkedBlockingQueue就很容易了。
LinkedBlockingQueue
基本概要
由链表实现的有界队列阻塞队列,但大小默认值为Integer.MAX_VALUE
所以我们在使用LinkedBlockingQueue时建议手动传值,为其提供我们所需的大小,避免队列过大造成机器负载或者内存爆满等情况。
其构造函数如下:
1 | //默认大小为Integer.MAX_VALUE |
从源码看,有三种方式可以构造LinkedBlockingQueue,通常情况下,我们建议创建指定大小的LinkedBlockingQueue阻塞队列。
LinkedBlockingQueue队列也是按 FIFO(先进先出)排序元素。
队列的头部是在队列中时间最长的元素,队列的尾部是在队列中时间最短的元素,插入元素到队列的尾部,而队列执行获取操作会获得位于队列头部的元素。
在正常情况下,链接队列的吞吐量要高于基于数组的队列(ArrayBlockingQueue),因为其内部实现添加和删除操作使用的两个ReenterLock来控制并发执行,而ArrayBlockingQueue内部只是使用一个ReenterLock控制并发,因此LinkedBlockingQueue的吞吐量要高于ArrayBlockingQueue。
使用LinkedBlockingQueue,我们同样也能实现生产者消费者模式。只需把前面ArrayBlockingQueue案例中的阻塞队列对象换成LinkedBlockingQueue即可,这里限于篇幅就不贴重复代码了。
接下来我们重点分析LinkedBlockingQueue的内部实现原理,最后我们将对ArrayBlockingQueue和LinkedBlockingQueue 做总结,阐明它们间的不同之处。
主要属性
1 | public class LinkedBlockingQueue<E> extends AbstractQueue<E> |
从上述可看成,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。
与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,由这两个lock生成了两个对应的condition(notEmpty和notFull)来实现可阻塞的插入和删除数据, 也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。
这里再次强调如果没有给LinkedBlockingQueue指定容量大小,其默认值将是Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。
至于LinkedBlockingQueue的实现原理图与ArrayBlockingQueue是类似的,除了对添加和移除方法使用单独的锁控制外,两者都使用了不同的Condition条件对象作为等待队列,用于挂起take线程和put线程。
put方法
1 | public void put(E e) throws InterruptedException { |
1 | private void enqueue(Node<E> node) { |
1 | private void signalNotEmpty() { |
要理解预留本地变量 c 的含义,count.getAndIncrement();表示返回进行CAS操作之前的数据,它表示先返回再进行+1操作.
take方法
1 | public E take() throws InterruptedException { |
1 | // 把头节点.next指向自己,方便GC |
1 | private void signalNotFull() { |
ArrayBlockingQueue VS LinkedBlockingQueue
相同点
都是通过condition通知机制来实现可阻塞式插入和删除元素,并满足线程安全的特性;
不同点
队列大小有所不同
ArrayBlockingQueue是有界的初始化必须指定大小,
LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),当添加速度大于移除速度时,可能会造成内存溢出等问题。公平性
ArrayBlockingQueue可以知道公平性,
LinkedBlockingQueue只能使用非公平锁.数据存储容器不同
ArrayBlockingQueue底层是采用的数组进行实现,
LinkedBlockingQueue则是采用链表数据结构.两者的实现队列添加或移除的锁不一样
ArrayBlockingQueue队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,
LinkedBlockingQueue队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能提高吞吐量,意味着高并发情况下生产(入队)消费(出队)可以同时进行.
线程池ThreadPoolExecutor实现原理
可以参考http://www.ideabuffer.cn/2017/04/04/深入理解Java线程池:ThreadPoolExecutor
四种线程池对比
newCachedThreadPool概述如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。注意一定要控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
newFixedThreadPool作用创建一个指定工作线程数量的线程池概述每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。优点它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。缺点在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
newSingleThreadExecutor作用创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任务概述它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。如果这个线程异常结束,会有另一个取代它,保证顺序执行。
newScheduleThreadPool作用创建一个定长的线程池优点支持定时的以及周期性的任务执行,支持定时及周期性任务执行。
为什么要使用线程池
在实际使用中,线程是很占用系统资源的,如果对线程管理不善很容易导致系统问题。
因此,在大多数并发框架中都会使用线程池来管理线程,使用线程池管理线程主要有如下好处:
降低资源消耗。通过复用已存在的线程和降低线程关闭的次数来尽可能降低系统性能损耗;提升系统响应速度。通过复用线程,省去创建线程的过程,因此整体上提升了系统的响应速度;提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,因此,需要使用线程池来管理线程。
线程池的工作原理
当一个并发任务提交给线程池,线程池分配线程去执行任务的过程如下图所示:
从图可以看出,线程池执行所提交的任务过程主要有这样几个阶段:
- 先判断线程池中核心线程池所有的线程是否都在执行任务。如果不是,则新创建一个线程执行刚提交的任务,否则,核心线程池中所有的线程都在执行任务,则进入第2步;
- 判断当前阻塞队列是否已满,如果未满,则将提交的任务放置在阻塞队列中;否则,则进入第3步;
- 判断线程池中所有的线程是否都在执行任务,如果没有,则创建一个新的线程来执行任务,否则,则交给饱和策略进行处理
线程池的创建
创建线程池主要是ThreadPoolExecutor类来完成,ThreadPoolExecutor的有许多重载的构造方法,通过参数最多的构造方法来理解创建线程池有哪些需要配置的参数。
ThreadPoolExecutor的构造方法为:
1 | ThreadPoolExecutor(int corePoolSize, |
corePoolSize:表示核心线程池的大小。
当提交一个任务时,如果当前核心线程池的线程个数没有达到corePoolSize,则会创建新的线程来执行所提交的任务,即使当前核心线程池有空闲的线程。
如果当前核心线程池的线程个数已经达到了corePoolSize,则不再重新创建线程。
如果调用了prestartCoreThread()或者 prestartAllCoreThreads(),线程池创建的时候所有的核心线程都会被创建并且启动。maximumPoolSize:表示线程池能创建线程的最大个数。
如果当阻塞队列已满时,并且当前线程池线程个数没有超过maximumPoolSize的话,就会创建新的线程来执行任务。keepAliveTime:空闲线程存活时间。
如果当前线程池的线程个数已经超过了corePoolSize,并且线程空闲时间超过了keepAliveTime的话,就会将这些空闲线程销毁,这样可以尽可能降低系统资源消耗。unit:时间单位。
为keepAliveTime指定时间单位。workQueue:阻塞队列。
用于保存任务的阻塞队列,可以使用ArrayBlockingQueue, LinkedBlockingQueue, SynchronousQueue, PriorityBlockingQueue。threadFactory:创建线程的工程类。
可以通过指定线程工厂为每个创建出来的线程设置更有意义的名字,如果出现并发问题,也方便查找问题原因。handler:饱和策略。
当线程池的阻塞队列已满和指定的线程都已经开启,说明当前线程池已经处于饱和状态了,那么就需要采用一种策略来处理这种情况。
采用的策略有这几种:AbortPolicy: 直接拒绝所提交的任务,并抛出RejectedExecutionException异常;CallerRunsPolicy:只用调用者所在的线程来执行任务;DiscardPolicy:不处理直接丢弃掉任务;DiscardOldestPolicy:丢弃掉阻塞队列中存放时间最久的任务,执行当前任务
线程池执行逻辑
通过ThreadPoolExecutor创建线程池后,提交任务后执行过程是怎样的,下面来通过源码来看一看。
execute方法源码如下:
1 | public void execute(Runnable command) { |
ThreadPoolExecutor的execute方法执行逻辑请见注释,不清楚可以参考深入理解Java线程池:ThreadPoolExecutor
下图为ThreadPoolExecutor的execute方法的执行示意图:
execute方法执行逻辑有这样几种情况:
- 如果当前运行的线程少于corePoolSize,则会创建新的线程来执行新的任务;
- 如果运行的线程个数等于或者大于corePoolSize,则会将提交的任务存放到阻塞队列workQueue中;
- 如果当前workQueue队列已满的话,则会创建新的线程来执行任务;
- 如果线程个数已经超过了maximumPoolSize,则会使用饱和策略RejectedExecutionHandler来进行处理。
需要注意的是,线程池的设计思想就是使用了核心线程池corePoolSize,阻塞队列workQueue,线程池maximumPoolSize,
这样的缓存策略来处理任务,实际上这样的设计思想在需要框架中都会使用。
线程池的关闭
关闭线程池,可以通过shutdown和shutdownNow这两个方法。
它们的原理都是遍历线程池中所有的线程,然后依次中断线程。
shutdown和shutdownNow还是有不一样的地方:
- shutdown只是将线程池的状态设置为
SHUTDOWN,然后中断所有空闲的线程 - shutdownNow首先将线程池的状态设置为
STOP,然后尝试停止所有的正在执行和未执行任务的线程,并返回等待执行任务的列表;
可以看出shutdown方法会将正在执行的任务继续执行完,而shutdownNow会直接中断正在执行的任务。
调用了这两个方法的任意一个,isShutdown方法都会返回true,
当所有的线程都关闭成功,才表示线程池成功关闭,这时调用isTerminated方法才会返回true。
如何合理配置线程池参数?
要想合理的配置线程池,就必须首先分析任务特性,可以从以下几个角度来进行分析:
任务的性质:CPU密集型任务,IO密集型任务和混合型任务。
任务性质不同的任务可以用不同规模的线程池分开处理。
CPU密集型任务配置尽可能少的线程数量,如配置Ncpu+1个线程的线程池。
IO密集型任务则由于需要等待IO操作,线程并不是一直在执行任务,则配置尽可能多的线程,如2xNcpu。
混合型的任务,如果可以拆分,则将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐率要高于串行执行的吞吐率,如果这两个任务执行时间相差太大,则没必要进行分解。
我们可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。任务的优先级:高,中和低。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。
它可以让优先级高的任务先得到执行,需要注意的是如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。任务的执行时间:长,中和短。
执行时间不同的任务可以交给不同规模的线程池来处理,或者也可以使用优先级队列,让执行时间短的任务先执行。任务的依赖性:是否依赖其他系统资源,如数据库连接。
依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果.
如果等待的时间越长CPU空闲时间就越长,那么线程数应该设置越大,这样才能更好的利用CPU。
并且,阻塞队列最好是使用有界队列,如果采用无界队列的话,一旦任务积压在阻塞队列中的话就会占用过多的内存资源,甚至会使得系统崩溃。
线程池之ScheduledThreadPoolExecutor
简单实用
1 | public static void main(String args[]) |
简介
ScheduledThreadPoolExecutor可以用来在给定延时后执行异步任务或者周期性执行任务,相对于任务调度的Timer来说,其功能更加强大,Timer只能使用一个后台线程执行任务,而ScheduledThreadPoolExecutor则可以通过构造函数来指定后台线程的个数。
ScheduledThreadPoolExecutor类的关系图如下: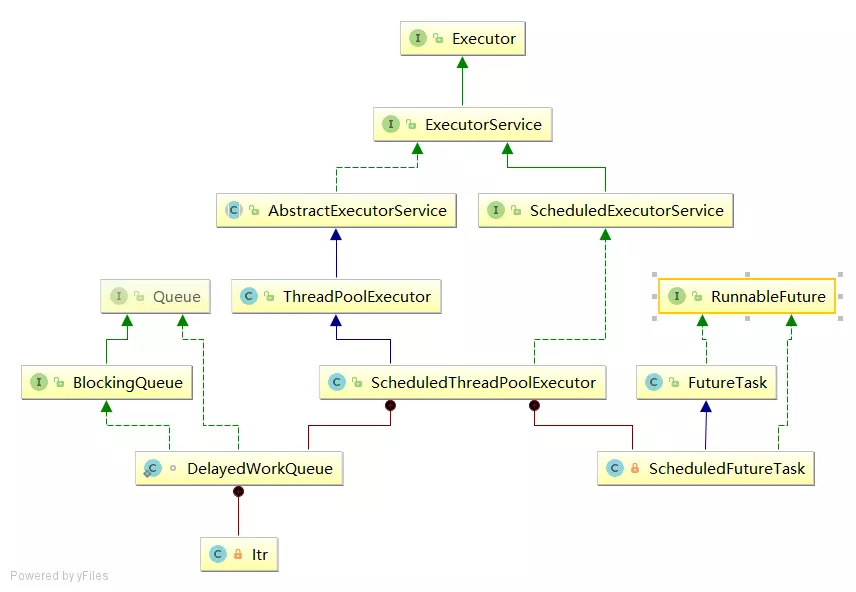
- 可以看出,ScheduledThreadPoolExecutor继承了ThreadPoolExecutor, 也就是说ScheduledThreadPoolExecutor拥有execute()和submit()提交异步任务的基础功能。
- ScheduledThreadPoolExecutor也两个重要的内部类:
DelayedWorkQueueScheduledFutureTask。
可以看出DelayedWorkQueue实现了BlockingQueue接口,也就是一个阻塞队列,ScheduledFutureTask则是继承了FutureTask类,也表示该类用于返回异步任务的结果。
这两个关键类,下面会具体详细来看。
构造方法
ScheduledThreadPoolExecutor有如下几个构造方法:
1 | public ScheduledThreadPoolExecutor(int corePoolSize) { |
由于ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,它的构造方法实际上是调用了ThreadPoolExecutor, 理解ThreadPoolExecutor构造方法的几个参数的意义后,理解这就很容易了。
可以看出,ScheduledThreadPoolExecutor的核心线程池的线程个数为指定的corePoolSize,当核心线程池的线程个数达到corePoolSize后,就会将任务提交给有界阻塞队列DelayedWorkQueue,
对DelayedWorkQueue在下面进行详细介绍,线程池允许最大的线程个数为Integer.MAX_VALUE,也就是说理论上这是一个大小无界的线程池。
特有方法
ScheduledThreadPoolExecutor实现了ScheduledExecutorService接口,
该接口定义了可延时执行异步任务和可周期执行异步任务的特有功能,相应的方法分别为:
1 | //1. 达到给定的延时时间后,执行任务。这里传入的是实现Runnable接口的任务, |
ScheduledFutureTask可周期性执行的任务
ScheduledThreadPoolExecutor最大的特色是能够周期性执行异步任务.
当调用schedule scheduleAtFixedRate scheduleWithFixedDelay方法时,实际上是将提交的任务转换成的ScheduledFutureTask类,从源码就可以看出。
以schedule方法为例:
1 | public ScheduledFuture<?> schedule(Runnable command, |
可以看出,通过decorateTask方法会将传入的Runnable参数转换成ScheduledFutureTask类。
线程池最大作用是将任务和线程进行解耦,线程主要是任务的执行者,而任务也就是现在所说的ScheduledFutureTask。
紧接着,会想到任何线程执行任务,总会调用run()方法。
为了保证ScheduledThreadPoolExecutor能够延时执行任务以及能够周期性执行任务,ScheduledFutureTask重写了run方法:
1 | public void run() { |
从源码可以很明显的看出,在重写的run方法中会先if (!periodic)判断当前任务是否是周期性任务,
如果不是的话就直接调用run()方法;
否则的话执行setNextRunTime()方法重设下一次任务执行的时间,并通过reExecutePeriodic(outerTask)方法将下一次待执行的任务放置到DelayedWorkQueue中。
结论
ScheduledFutureTask最主要的功能是根据当前任务是否具有周期性,对异步任务进行进一步封装。
若不是周期性任务(调用schedule方法)则直接通过run()执行;
若是周期性任务,则需要在每一次执行完后,重设下一次执行的时间,然后将下一次任务继续放入到阻塞队列中。
DelayedWorkQueue阻塞队列
在ScheduledThreadPoolExecutor中还有另外的一个重要的类就是DelayedWorkQueue。
为了实现其ScheduledThreadPoolExecutor能够延时执行异步任务以及能够周期执行任务,DelayedWorkQueue进行相应的封装。
DelayedWorkQueue是一个基于堆的数据结构,类似于DelayQueue和PriorityQueue。
在执行定时任务的时候,每个任务的执行时间都不同,所以DelayedWorkQueue的工作就是按照执行时间的升序来排列,执行时间距离当前时间越近的任务在队列的前面。
为什么要使用DelayedWorkQueue呢?
定时任务执行时需要取出最近要执行的任务,所以任务在队列中每次出队时一定要是当前队列中执行时间最靠前的,所以自然要使用优先级队列。
DelayedWorkQueue是一个优先级队列,它可以保证每次出队的任务都是当前队列中执行时间最靠前的.
由于它是基于堆结构的队列,堆结构在执行插入和删除操作时的最坏时间复杂度是 O(logN)。
DelayedWorkQueue的数据结构
1 | //初始大小 |
可以看出DelayedWorkQueue底层是采用数组构成的.
结论
DelayedWorkQueue是基于堆的数据结构,按照时间顺序将每个任务进行排序,将待执行时间越近的任务放在在队列的队头位置,以便于最先进行执行。
ScheduledThreadPoolExecutor执行过程
现在我们对ScheduledThreadPoolExecutor的两个内部类ScheduledFutueTask和DelayedWorkQueue进行了了解,
实际上这也是线程池工作流程中最重要的两个关键因素:任务 阻塞队列
现在我们来看下ScheduledThreadPoolExecutor提交一个任务后,整体的执行过程。
以ScheduledThreadPoolExecutor的schedule方法为例,具体源码为:
1 | public ScheduledFuture<?> schedule(Runnable command, |
方法很容易理解,为了满足ScheduledThreadPoolExecutor能够延时执行任务和能周期执行任务的特性,会先将实现Runnable接口的类转换成ScheduledFutureTask。
然后会调用delayedExecute方法进行执行任务,这个方法也是关键方法,来看下源码:
1 | private void delayedExecute(RunnableScheduledFuture<?> task) { |
delayedExecute方法的主要逻辑请看注释,可以看出该方法的重要逻辑会是在ensurePrestart()方法中,它的源码为:
1 | void ensurePrestart() { |
可以看出该方法逻辑很简单,关键在于它所调用的addWorker方法,
- addWorker方法方法主要功能:
新建Worker类,当执行任务时,就会调用被Worker所重写的run方法,进而会继续执行runWorker方法。
在runWorker方法中会调用getTask方法从阻塞队列中不断的去获取任务进行执行,直到从阻塞队列中获取的任务为null的话,线程结束终止。
addWorker方法是ThreadPoolExecutor类中的方法,可以查看深入理解Java线程池:ThreadPoolExecutor
总结
- ScheduledThreadPoolExecutor继承了ThreadPoolExecutor类,因此,整体上功能一致,也是线程池主要负责创建线程(Worker类),线程从阻塞队列中不断获取新的异步任务,直到阻塞队列中已经没有了异步任务为止。
但是相较于ThreadPoolExecutor来说,ScheduledThreadPoolExecutor具有延时执行任务和可周期性执行任务的特性.
ScheduledThreadPoolExecutor重新设计了任务类ScheduleFutureTask,ScheduleFutureTask重写了run方法使其具有可延时执行和可周期性执行任务的特性。
另外,阻塞队列DelayedWorkQueue是可根据优先级排序的队列,采用了堆的底层数据结构,使得与当前时间相比,待执行时间越靠近的任务放置队头,以便线程能够获取到任务进行执行; - 线程池无论是ThreadPoolExecutor还是ScheduledThreadPoolExecutor,在设计时的三个关键要素是:
任务执行者任务结果。
它们的设计思想也是完全将这三个关键要素进行了解耦。任务
任务的执行机制,完全交由Worker类,也就是进一步了封装了Thread。
向线程池提交任务,无论为ThreadPoolExecutor的execute方法和submit方法,还是ScheduledThreadPoolExecutor的schedule方法,都是先将任务移入到阻塞队列中,
然后通过addWork方法新建了Worker类,并通过runWorker方法启动线程,并不断的从阻塞对列中获取异步任务执行交给Worker执行,直至阻塞队列中无法取到任务为止。执行者
在ThreadPoolExecutor和ScheduledThreadPoolExecutor中任务是指实现了Runnable接口和Callable接口的实现类。
ThreadPoolExecutor中会将任务转换成FutureTask类,
而在ScheduledThreadPoolExecutor中为了实现可延时执行任务和周期性执行任务的特性,任务会被转换成ScheduledFutureTask类,该类继承了FutureTask,并重写了run方法。任务结果
在ThreadPoolExecutor中提交任务后,获取任务结果可以通过Future接口的类.
在ThreadPoolExecutor中实际上为FutureTask类,而在ScheduledThreadPoolExecutor中则是ScheduledFutureTask类
FutureTask基本操作总结
源码分析
2020-06-22 10:14:43记录
0)、先查看FutureTask<V>的继承关系,看看为什么可以作为Thread构造方法的参数
1 | // FutureTask<V>传入泛型,实现RunnableFuture<V>接口 |
1)、FutureTask<Integer> futureTask = new FutureTask<>(() -> 1024);
创建FutureTask
1 | public FutureTask(Callable<V> callable) { |
2)、new Thread(futureTask).start();
执行线程,会执行FutureTask中的run()方法,在run方法中,调用了Callable的call()方法,
并用成员变量outcome接收call()方法的返回值,
设置完成之后调用finishCompletion()方法,唤醒waiters上的所有阻塞线程(run方法执行完成了,可以get()获取值了)
1 | // 执行的start()会开辟新线程,执行 run() 方法 |
3)、System.out.println(futureTask.get());// 1024
若call()方法执行完成,调用成员变量outcome的值进行返回(call方法的返回值)
若未完成,或设置了超时,则加入等待队列,若被中断,则从队列中移除
1 | public V get() throws InterruptedException, ExecutionException { |
4)、System.out.println(futureTask.get(3L,TimeUnit.SECONDS));// 1024
不让get方法一直阻塞,设置一个超时时间
1 | public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { |
5)、System.out.println(futureTask.cancel(true));// false
取消成功返回true,否则返回false
、cancel( true ):中断正在运行的线程
、cancel( false ):不中断正在运行的线程
1 | public boolean cancel(boolean mayInterruptIfRunning) { |
6)、判断状态
1 | // 已取消,正在中断,已中断:返回true |
FutureTask的简介
在Executors框架体系中,FutureTask用来表示可获取结果的异步任务。
FutureTask实现了Future接口,FutureTask提供了启动异步任务 取消异步任务 查询异步任务是否计算结束 获取最终的异步任务的结果的一些常用的方法。
通过get()方法来获取异步任务的结果,但是会阻塞当前线程直至异步任务执行结束,一旦任务执行结束,任务不能重新启动或取消,除非调用runAndReset()方法。
一个FutureTask 可以用来包装一个 Callable(一个有返回值的runnable) 或是一个runnable对象。
因为FurtureTask实现了Runnable方法,所以一个 FutureTask可以提交(submit)给一个Excutor执行(excution).
FutureTask可用于异步获取执行结果或取消执行任务的场景。
通过传入Runnable或者Callable的任务给FutureTask,直接调用其run方法或者放入线程池执行,之后可以在外部通过FutureTask的get方法异步获取执行结果,
因此,FutureTask非常适合用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。
另外,FutureTask还可以确保即使调用了多次run方法,它都只会执行一次Runnable或者Callable任务,或者通过cancel取消FutureTask的执行等。
在FutureTask的源码中为其定义了这些状态:
1 | private static final int NEW = 0; |
另外,在《java并发编程的艺术》一书,作者根据FutureTask.run()方法的执行的时机,FutureTask分为了3种状态:
未启动。FutureTask.run()方法还没有被执行之前,FutureTask处于未启动状态。当创建一个FutureTask,还没有执行FutureTask.run()方法之前,FutureTask处于未启动状态。已启动。FutureTask.run()方法被执行的过程中,FutureTask处于已启动状态。已完成。FutureTask.run()方法执行结束,或调用FutureTask.cancel(…)方法取消任务,或在执行任务期间抛出异常,这些情况都称之为FutureTask的已完成状态。
下图总结了FutureTask的状态变化的过程: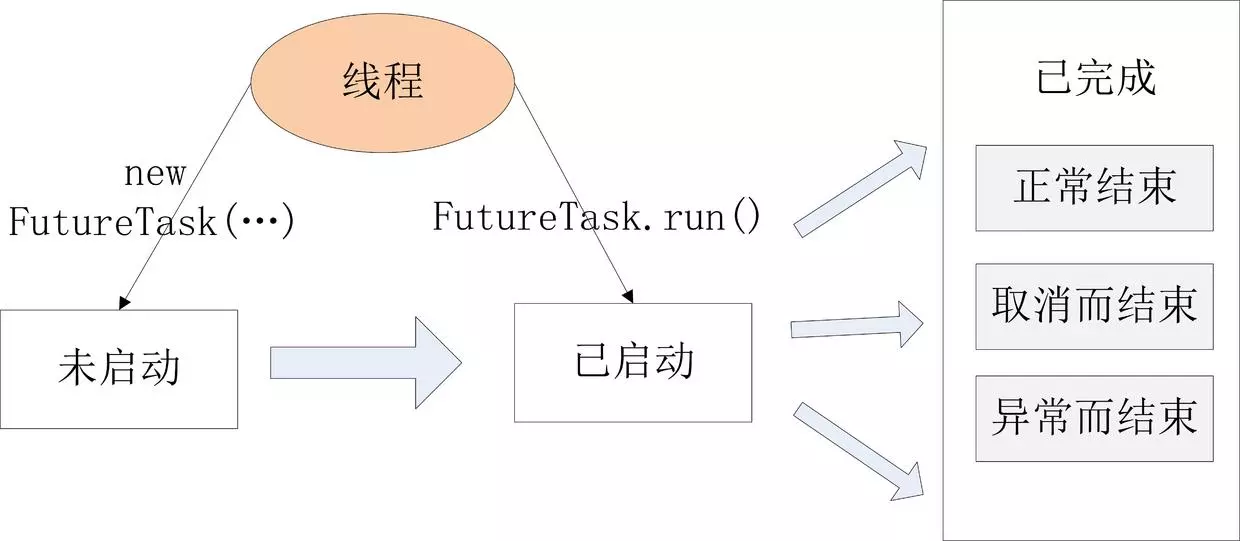
由于FutureTask具有这三种状态,因此执行FutureTask的get方法和cancel方法,当前处于不同的状态对应的结果也是大不相同。
这里对get方法和cancel方法做个总结: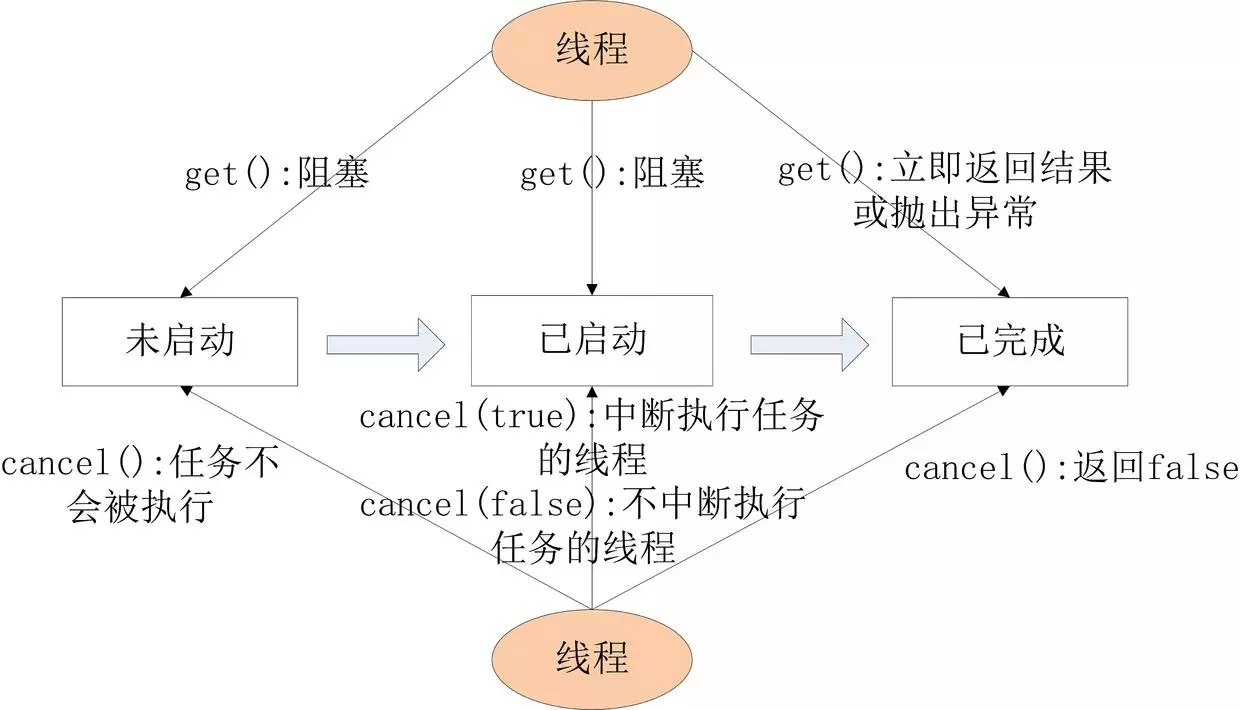
- get方法
当FutureTask处于未启动或已启动状态时,执行FutureTask.get()方法将导致调用线程阻塞。
如果FutureTask处于已完成状态,调用FutureTask.get()方法将导致调用线程立即返回结果或者抛出异常 - cancel方法
当FutureTask处于未启动状态时,执行FutureTask.cancel()方法将此任务永远不会执行;
当FutureTask处于已启动状态时,执行FutureTask.cancel(true)方法将以中断线程的方式来阻止任务继续进行,如果执行FutureTask.cancel(false)将不会对正在执行任务的线程有任何影响;
当FutureTask处于已完成状态时,执行FutureTask.cancel(…)方法将返回false。
基本使用,总结,应用场景
FutureTask除了实现Future接口外,还实现了Runnable接口。
因此,FutureTask可以交给Executor执行,也可以由调用的线程直接执行FutureTask.run()。
另外,FutureTask的获取也可以通过ExecutorService.submit()方法返回一个FutureTask对象,然后在通过FutureTask.get()获取。
1 | ExecutorService executorService1=Executors.newFixedThreadPool(1); |
总结
- FutureTask是类似于Runnable的一种存在,可以接受Callable这种带返回结果的接口作构造参数
- FutureTask可以脱离主线程而单独开线程去执行其他运算操作
- 一个FutureTask不论被多少个线程执行run,都只会执行一次,执行一次后就保持在“运算完成”的状态而不会回滚
- FutureTask可以保证:从运算线程返回的结果,可以安全的抵达调用运算线程的线程,中间不会出现线程安全问题
应用场景
- 当一个线程需要等待另一个线程把某个任务执行完后它才能继续执行,此时可以使用FutureTask。
- 假设有多个线程执行若干任务,每个任务最多只能被执行一次。
- 当多个线程试图执行同一个任务时,只允许一个线程执行任务,其他线程需要等待这个任务执行完后才能继续执行。
Java中atomic包中的原子操作类总结
原子操作类介绍
在并发编程中很容易出现并发安全的问题,有一个很简单的例子就是多线程更新变量i+1,
比如多个线程执行i++操作,就有可能获取不到正确的值,而这个问题,最常用的方法是通过Synchronized 进行控制来达到线程安全的目的。
但是由于synchronized是采用的是悲观锁策略,并不是特别高效的一种解决方案。
实际上,在J.U.C下的atomic包提供了一系列的操作简单,性能高效,并能保证线程安全的类去更新基本类型变量,数组元素,引用类型以及更新对象中的字段类型。
atomic包下的这些类都是采用的是乐观锁策略去更新原子数据,在java中则是使用CAS操作具体实现。
预备知识–CAS操作
能够弄懂atomic包下这些原子操作类的实现原理,就要先明白什么是CAS操作。
原子更新基本类型
atomic包提高原子更新基本类型的工具类,主要有这些:
- AtomicBoolean:以原子更新的方式更新boolean;
- AtomicInteger:以原子更新的方式更新Integer;
- AtomicLong:以原子更新的方式更新Long;
这几个类的用法基本一致,这里以AtomicInteger为例总结常用的方法
- addAndGet(int delta) :以原子方式将输入的数值与实例中原本的值相加,并返回最后的结果;
- incrementAndGet() :以原子的方式将实例中的原值进行加1操作,并返回最终相加后的结果;
- getAndIncrement():以原子的方式将实例中的原值加1,返回的是自增前的旧值;
- getAndSet(int newValue):将实例中的值更新为新值,并返回旧值;
还有一些方法,可以查看API,不再赘述。为了能够弄懂AtomicInteger的实现原理,以getAndIncrement方法为例,来看下源码:
1 | public final int getAndIncrement() { |
可以看出,该方法实际上是调用了unsafe实例的getAndAddInt方法,unsafe实例的获取时通过UnSafe类的静态方法getUnsafe获取:
1 | private static final Unsafe unsafe = Unsafe.getUnsafe(); |
Unsafe类在sun.misc包下,Unsafer类提供了一些底层操作,atomic包下的原子操作类的也主要是通过Unsafe类提供的compareAndSwapInt,compareAndSwapLong等一系列提供CAS操作的方法来进行实现。
下面用一个简单的例子来说明AtomicInteger的用法:
1 | public class AtomicDemo { |
例子很简单,就是新建了一个atomicInteger对象,而atomicInteger的构造方法也就是传入一个基本类型数据即可,对其进行了封装。
对基本变量的操作比如自增,自减,相加,更新等操作,atomicInteger也提供了相应的方法进行这些操作。
但是,因为atomicInteger借助了UnSafe提供的CAS操作能够保证数据更新的时候是线程安全的,并且由于CAS是采用乐观锁策略,因此,这种数据更新的方法也具有高效性。
AtomicLong的实现原理和AtomicInteger一致,只不过一个针对的是long变量,一个针对的是int变量。
而boolean变量的更新类AtomicBoolean类是怎样实现更新的呢?核心方法是compareAndSet方法,其源码如下:
1 | public final boolean compareAndSet(boolean expect, boolean update) { |
可以看出,compareAndSet方法的实际上也是先转换成0,1的整型变量,然后是通过针对int型变量的原子更新方法compareAndSwapInt来实现的。
可以看出atomic包中只提供了对boolean,int ,long这三种基本类型的原子更新的方法,参考对boolean更新的方式,原子更新char,doule,float也可以采用类似的思路进行实现。
原子更新数组类型
atomic包下提供能原子更新数组中元素的类有:
- AtomicIntegerArray:原子更新整型数组中的元素;
- AtomicLongArray:原子更新长整型数组中的元素;
- AtomicReferenceArray:原子更新引用类型数组中的元素
这几个类的用法一致,就以AtomicIntegerArray来总结下常用的方法:
- addAndGet(int i, int delta):以原子更新的方式将数组中索引为i的元素与输入值相加;返回相加后的值.
- getAndAdd(int i, int delta):以原子更新的方式将数组中索引为i的元素与输入值相加;返回旧值.
- getAndIncrement(int i):以原子更新的方式将数组中索引为i的元素自增加1;
- compareAndSet(int i, int expect, int update):将数组中索引为i的位置的元素进行更新
可以看出,AtomicIntegerArray与AtomicInteger的方法基本一致,只不过在AtomicIntegerArray的方法中会多一个指定数组索引位i。下面举一个简单的例子:
1 | public class AtomicDemo { |
原子更新引用类型
如果需要原子更新引用类型变量的话,为了保证线程安全,atomic也提供了相关的类:
- AtomicReference:原子更新引用类型;
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段;
- AtomicMarkableReference:原子更新带有标记位的引用类型;
这几个类的使用方法也是基本一样的,以AtomicReference为例,来说明这些类的基本用法。下面是一个demo
1 | public class AtomicDemo { |
原子更新字段类型
如果需要更新对象的某个字段,并在多线程的情况下,能够保证线程安全,atomic同样也提供了相应的原子操作类:
- AtomicIntegeFieldUpdater:原子更新整型字段类;
- AtomicLongFieldUpdater:原子更新长整型字段类;
- AtomicStampedReference:原子更新引用类型,这种更新方式会带有版本号。而为什么在更新的时候会带有版本号,是为了解决CAS的ABA问题;
要想使用原子更新字段需要两步操作:
- 原子更新字段类都是抽象类,只能通过
静态方法newUpdater来创建一个更新器,并且需要设置想要更新的类和属性; - 更新类的属性必须使用
public volatile进行修饰;
这几个类提供的方法基本一致,以AtomicIntegerFieldUpdater为例来看看具体的使用:
1 | public class AtomicDemo { |
大白话说java并发工具类(CountDownLatch,CyclicBarrier)
CountDownLatch
2020-06-18 13:01:34 三步源码分析
1)、 CountDownLatch countDownLatch = new CountDownLatch(5);
初始化,设置锁的state=5
1 | public CountDownLatch(int count) { |
2)、 countDownLatch.await();
进行获取锁,如果state不为0,就一直自旋等待,也就是阻塞,不会执行countDownLatch.await();之后的代码。
如果state=0,才能获取到锁,从而取消阻塞,执行countDownLatch.await();之后的代码。
1 | public void await() throws InterruptedException { |
3)、 countDownLatch.countDown();
执行一次,state-1,此时,只有执行5次,state才能为0。
当state=0时,才能使上面一步countDownLatch.await();停止自旋,获取到锁,进而执行countDownLatch.await();之后的代码
1 | public void countDown() { |
在多线程协作完成业务功能时,有时候需要等待其他多个线程完成任务之后,主线程才能继续往下执行业务功能,
在这种的业务场景下,通常可以使用Thread类的join方法,让主线程等待被join的线程执行完之后,主线程才能继续往下执行。
当然,使用线程间消息通信机制(等待,通知)也可以完成。
其实,java并发工具类中为我们提供了类似“倒计时”这样的工具类,可以十分方便的完成所说的这种业务场景。
- 为了能够理解CountDownLatch,举个栗子,
运动员进行跑步比赛时,假设有6个运动员参与比赛,裁判员在终点会为这6个运动员分别计时,可以想象没当一个运动员到达终点的时候,对于裁判员来说就少了一个计时任务。直到所有运动员都到达终点了,裁判员的任务也才完成。这6个运动员可以类比成6个线程,当线程调用CountDownLatch.countDown方法时就会对计数器的值减一,直到计数器的值为0的时候,裁判员(调用await方法的线程)才能继续往下执行。
下面来看些CountDownLatch的一些重要方法。
先从CountDownLatch的构造方法看起:
1 | public CountDownLatch(int count) |
构造方法会传入一个整型数N,之后调用CountDownLatch的countDown方法会对N减一,直到N减到0的时候,当前调用await方法的线程继续执行。
CountDownLatch的方法不是很多,将它们一个个列举出来:
await() throws InterruptedException:调用该方法的线程等到构造方法传入的N减到0的时候,才能继续往下执行;await(long timeout, TimeUnit unit):与上面的await方法功能一致,只不过这里有了时间限制,调用该方法的线程等到指定的timeout时间后,不管N是否减至为0,都会继续往下执行;countDown():使CountDownLatch初始值N减1;long getCount():获取当前CountDownLatch的N值;
下面用一个具体的例子来说明CountDownLatch的具体用法:
1 | import java.util.concurrent.*; |
记住,await是使当前线程暂停,不往下执行,但暂停的线程一直在监听N的值是否为0,一旦为0就往下执行.
调用countDown是使N减1,一旦减到0,所有的await都继续往下执行.
知道这个,这个案例再看注释就不难理解了.
- 再写一次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46// 2020-04-07 17:01:42
public static void main(String[] args) throws InterruptedException
{
CountDownLatch one = new CountDownLatch(1);
CountDownLatch five = new CountDownLatch(5);
ExecutorService threadPool = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++)
{
threadPool.execute(() ->
{
System.out.println(Thread.currentThread().getName() + "---准备就绪。。。");
five.countDown();
try {
one.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "---跑。。。");
System.out.println(Thread.currentThread().getName() + "---到达。。。");
});
}
five.await();
System.out.println("发号施令。。。");
one.countDown();
Thread.sleep(10);// 五名成员跑步中
System.out.println("比赛结束。。。");
}
// pool-1-thread-3---准备就绪。。。
// pool-1-thread-5---准备就绪。。。
// pool-1-thread-4---准备就绪。。。
// pool-1-thread-1---准备就绪。。。
// pool-1-thread-2---准备就绪。。。
// 发号施令。。。
// pool-1-thread-3---跑。。。
// pool-1-thread-4---跑。。。
// pool-1-thread-4---到达。。。
// pool-1-thread-2---跑。。。
// pool-1-thread-2---到达。。。
// pool-1-thread-1---跑。。。
// pool-1-thread-1---到达。。。
// pool-1-thread-3---到达。。。
// pool-1-thread-5---跑。。。
// pool-1-thread-5---到达。。。
// 比赛结束。。。
CyclicBarrier
2020-06-18 16:36:46 四步源码分析
CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> System.out.println("111..."));
初始化一个数量5,和一个λ表达式。
count用于控制循环,当count为0时,执行λ表达式。1
2
3
4
5
6
7
8
9
10
11
12
13
14public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;// 5
this.count = parties;// 5
this.barrierCommand = barrierAction;// 传入的λ表达式
}
private final ReentrantLock lock = new ReentrantLock();
private final Condition trip = lock.newCondition();
private final int parties;// 用于保存传入的数量 5
private final Runnable barrierCommand;// 传入的λ表达式
private Generation generation = new Generation();
private int count;// 用来控制数量,数量为0执行λ表达式
cyclicBarrier.await();
当count为0时,执行λ表达式的run()方法,执行完run()方法之后,重置count数量,唤醒所有等待线程。
count不为0,进入await()方法,等待count为0时唤醒。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94public int await() throws InterruptedException, BrokenBarrierException {
try {
// 进入dowait方法
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe); // cannot happen
}
}
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
final Generation g = generation;
if (g.broken)
throw new BrokenBarrierException();
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
// count为0时,执行一次run()方法
int index = --count;
if (index == 0) { // tripped
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
// 进入nextGeneration()
// 1. 唤醒所有线程
// 2. count恢复为初始值5
// 3. generation指向新对象new Generation()
nextGeneration();
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
// 循环,直到中断或超时
for (;;) {
try {
// 进入await();等待,等待执行breakBarrier();或nextGeneration();来唤醒。
// 也就是上面count为0时,执行nextGeneration();来唤醒
if (!timed)
trip.await();
else if (nanos > 0L)
// 用于await(long timeout, TimeUnit unit)方法,进行有限时间的等待
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
if (g != generation)
return index;
// 用于await(long timeout, TimeUnit unit)方法,判断时间到了进行重置count数
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
private void nextGeneration() {
trip.signalAll();// 唤醒所有睡觉的线程
count = parties;// 初始化count数量
generation = new Generation();// 初始化generation对象
}
private void breakBarrier() {
generation.broken = true;// 用于中断线程
count = parties;// 恢复数量5
trip.signalAll();// 通知其他await()的线程
}cyclicBarrier.await(1L, TimeUnit.SECONDS);
不等于await()方法的是,它会进行固定时间的等待,而不是一直等待,时间到了之后再进行重置。1
2
3
4
5
6
7
8public int await(long timeout, TimeUnit unit)
throws InterruptedException,
BrokenBarrierException,
TimeoutException {
// 参考上面的dowait方法,注意这里传入的参数为true
// 不会进入等待,会进入时间的自旋
return dowait(true, unit.toNanos(timeout));
}cyclicBarrier.reset();
用于重置,这个没什么好说的。主要调用了breakBarrier();和nextGeneration();方法1
2
3
4
5
6
7
8
9
10
11
12
// 用于重置
public void reset() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
breakBarrier(); // break the current generation
nextGeneration(); // start a new generation
} finally {
lock.unlock();
}
}
CyclicBarrier也是一种多线程并发控制的实用工具,和CountDownLatch一样具有等待计数的功能,但是相比于CountDownLatch功能更加强大。
我们先来看一下
- 构造方法:第一个参数我们叫作计数
1
2
3
4
5
6
7
8
9
10public CyclicBarrier(int parties) {
this(parties, null);
}
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}N,第二个参数我们称为屏障方法,屏障方法可以不传. - 其他方法:当线程执行了await方法之后,会等待,在await方法之后的代码都不会执行,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//使当前线程永久等待
await() throws InterruptedException, BrokenBarrierException
//与上面的await方法不同的是,只会等待一定的时间.
await(long timeout, TimeUnit unit) throws InterruptedException,
BrokenBarrierException, TimeoutException
//获取当前有多少个线程等待
int getNumberWaiting()
//等待线程超时,或被中断才返回true.
boolean isBroken()
//将屏障重置为初始状态。
//如果当前有线程正在等待的话,抛异常BrokenBarrierException。
void reset()
当N个线程都等待之后,就会执行屏障方法,当屏障方法执行完成之后,
所有等待的线程都会被唤醒,同时继续往下执行.
如果在往下执行的过程中再次碰到await,同上.
CyclicBarrier的执行示意图如下:
- 一个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CyclicBarrierTest
{
private static final int num=5;
private static final CyclicBarrier CYCLIC_BARRIER=new CyclicBarrier(num,()->{
System.out.println("111...");
});
public static void main(String[] args)
{
ExecutorService executorService= Executors.newFixedThreadPool(num);
System.out.println("准备...");
for (int i = 0; i < num; i++)
{
executorService.execute(()->{
System.out.println(Thread.currentThread().getName()+"准备完成...");
try
{
CYCLIC_BARRIER.await();
System.out.println(Thread.currentThread().getName()+"冲啊...");
CYCLIC_BARRIER.await();
} catch (Exception e)
{
e.printStackTrace();
}
});
}
executorService.shutdown();
}
}
// 准备...
// pool-1-thread-2准备完成...
// pool-1-thread-5准备完成...
// pool-1-thread-4准备完成...
// pool-1-thread-3准备完成...
// pool-1-thread-1准备完成...
// 111...
// pool-1-thread-1冲啊...
// pool-1-thread-4冲啊...
// pool-1-thread-3冲啊...
// pool-1-thread-2冲啊...
// pool-1-thread-5冲啊...
// 111...
CountDownLatch VS CyclicBarrier
CountDownLatch与CyclicBarrier都是用于控制并发的工具类,都可以理解成维护的就是一个计数器,但是这两者还是各有不同侧重点的:
- CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
CountDownLatch强调一个线程等多个线程完成某件事情。CyclicBarrier是多个线程互等,等大家都完成,再携手共进。 - 调用CountDownLatch的await方法后,当前线程阻塞,不会继续往下执行,调用countDown是使N减1,减到0时,阻塞线程才会被唤醒;
而调用CyclicBarrier的await方法,阻塞当前线程,直到CyclicBarrier指定的线程全部都到达了指定点的时候,才能继续往下执行; - CountDownLatch方法比较少,操作比较简单,而CyclicBarrier提供的方法更多,比如能够通过getNumberWaiting(),isBroken()这些方法获取当前多个线程的状态,
并且CyclicBarrier的构造方法可以传入barrierAction,指定当所有线程都到达时执行的业务功能; - CountDownLatch是不能复用的,而CyclicLatch是可以复用的。
大白话说java并发工具类(Semaphore,Exchanger)
三步分析
1)、Semaphore semaphore = new Semaphore(6);// 6个停车位
初始化锁的标志位state=6,默认非公平锁
1 | private final Sync sync; |
2)、semaphore.acquire(1);// 获得一个停车位许可证,进行停车
获取锁,获取一次,state-1,如果减之后小于0,则进入park阻塞当前线程
1 | public void acquire() throws InterruptedException { |
3)、semaphore.release(1);// 停车结束,要走了,归还一个停车位许可证
释放锁,释放一次,state+1,加成功之后,unpark取消前面获取锁的阻塞线程,让他们获取到锁
1 | public void release() { |
Semaphore控制资源并发访问
Semaphore 是 synchronized 的加强版,作用是控制线程的并发数量。
就这一点而言,单纯的synchronized 关键字是实现不了的。
1 | synchronized 是 jvm 层面的实现,ReentrantLock 是 jdk 层面的实现,synchronized 的缺点如下: |
Semaphore可以理解为信号量,用于控制资源能够被并发访问的线程数量,以保证多个线程能够合理的使用特定资源。
Semaphore就相当于一个许可证,线程需要先通过acquire方法获取该许可证,该线程才能继续往下执行,否则只能在该方法出阻塞等待。
当执行完业务功能后,需要通过release()方法将许可证归还,以便其他线程能够获得许可证继续执行。
Semaphore可以用于做流量控制,特别是公共资源有限的应用场景,比如数据库连接。
假如有多个线程读取数据后,需要将数据保存在数据库中,而可用的最大数据库连接只有10个,这时候就需要使用Semaphore来控制能够并发访问到数据库连接资源的线程个数最多只有10个。
在限制资源使用的应用场景下,Semaphore是特别合适的。
下面来看下Semaphore的主要方法:
1 | //获取许可,如果无法获取到,则阻塞等待直至能够获取为止 |
示例1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public static void main(String[] args)
{
int count = 15;
ExecutorService threadPool = Executors.newFixedThreadPool(count);
Semaphore semaphore = new Semaphore(6);//permits=许可证
System.out.println(LocalDateTime.now() + "---" + Thread.currentThread().getName()+" 开始");
for (int i = 0; i < count; i++)
{
threadPool.execute(() ->
{
try
{
semaphore.acquire();// 获得
Thread.sleep(3000);
System.out.println(LocalDateTime.now() + "---" + Thread.currentThread().getName());
semaphore.release();// 释放
} catch (InterruptedException e)
{
e.printStackTrace();
}
});
}
threadPool.shutdown();
// 2020-06-18T17:03:30.653---main 开始
// 2020-06-18T17:03:33.663---pool-1-thread-5
// 2020-06-18T17:03:33.663---pool-1-thread-6
// 2020-06-18T17:03:33.663---pool-1-thread-2
// 2020-06-18T17:03:33.663---pool-1-thread-3
// 2020-06-18T17:03:33.663---pool-1-thread-4
// 2020-06-18T17:03:33.663---pool-1-thread-1
// 2020-06-18T17:03:36.664---pool-1-thread-9
// 2020-06-18T17:03:36.664---pool-1-thread-11
// 2020-06-18T17:03:36.664---pool-1-thread-8
// 2020-06-18T17:03:36.664---pool-1-thread-10
// 2020-06-18T17:03:36.664---pool-1-thread-12
// 2020-06-18T17:03:36.664---pool-1-thread-7
// 2020-06-18T17:03:39.664---pool-1-thread-13
// 2020-06-18T17:03:39.664---pool-1-thread-14
// 2020-06-18T17:03:39.664---pool-1-thread-15
}Executors.newFixedThreadPool(THREAD_COUNT);表示线程池数量=15new Semaphore(6);permits=许可证表示并发线程的数量=6s.acquire();//acquire=获得这里的s.acquire();相当于s.acquire(1);
控制并发的数量,6/1=6,所以可以并发开始6个线程,s.release();//release=释放默认也是1,可以并发结束6个线程,修改内容
s.acquire(3);s.release(3);这时可以并发通过6/3=2个1
2
3
4
5
6
7
8
9
10
11
12
13
14
1513:44:55---pool-1-thread-4
13:44:55---pool-1-thread-1
13:44:55---pool-1-thread-2
13:44:58---pool-1-thread-5
13:44:58---pool-1-thread-3
13:44:58---pool-1-thread-6
13:45:01---pool-1-thread-7
13:45:01---pool-1-thread-9
13:45:01---pool-1-thread-8
13:45:04---pool-1-thread-14
13:45:04---pool-1-thread-12
13:45:04---pool-1-thread-11
13:45:07---pool-1-thread-13
13:45:07---pool-1-thread-10
13:45:07---pool-1-thread-15我的理解:一般不设置acquire与release传参不相同,或传参超出Semaphore初始化的数量,因为这样并没有任何意义.
这里的获取和释放,就是获取锁,释放锁的意思.示例2
理解了上面的基本使用,下面假设一个场景:
有一天,班主任需要班上10个同学到讲台上来填写一个表格,但是老师只准备了5支笔,因此,只能保证同时只有5个同学能够拿到笔并填写表格,没有获取到笔的同学只能够等前面的同学用完之后,才能拿到笔去填写表格。
1 | public class SemaphoreDemo |
1 | 01:55:02pool-1-thread-5 同学准备获取笔...... |
从这个例子就可以看出,Semaphore用来做特殊资源的并发访问控制是相当合适的,如果有业务场景需要进行流量控制,可以优先考虑Semaphore。
Exchanger线程间交换数据的工具
Exchanger是一个用于线程间协作的工具类,用于两个线程间能够交换。
它提供了一个交换的同步点,在这个同步点两个线程能够交换数据。
具体交换数据是通过exchange方法来实现的,如果一个线程先执行exchange方法,那么它会同步等待另一个线程也执行exchange方法,这个时候两个线程就都达到了同步点,两个线程就可以交换数据。
Exchanger除了一个无参的构造方法外,主要方法也很简单:
1 | //当一个线程执行该方法的时候,会等待另一个线程也执行该方法,因此两个线程就都达到了同步点 |
- 一个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class ExchangerTest
{
public static void main(String[] args)
{
Exchanger<Object> exchanger = new Exchanger<>();
new Thread(() ->
{
Object object = new Object();
System.out.println(Thread.currentThread().getName() + "创建的对象是" + object);
try
{
object = exchanger.exchange(object);
System.out.println(Thread.currentThread().getName() + "交换后得到的对象是" + object);
} catch (InterruptedException e)
{
e.printStackTrace();
}
}, "线程1").start();
new Thread(() ->
{
Object object = new Object();
System.out.println(Thread.currentThread().getName() + "创建的对象是" + object);
try
{
Thread.sleep(2 * 1000);
object = exchanger.exchange(object);
System.out.println(Thread.currentThread().getName() + "交换后得到的对象是" + object);
} catch (InterruptedException e)
{
e.printStackTrace();
}
}, "线程2").start();
}
}这个例子很简单,也很能说明Exchanger的基本使用。当两个线程都到达调用exchange方法的同步点的时候,两个线程就能交换彼此的数据。1
2
3
4线程1创建的对象是java.lang.Object@25f209f5
线程2创建的对象是java.lang.Object@2fff0d30
线程2交换后得到的对象是java.lang.Object@25f209f5
线程1交换后得到的对象是java.lang.Object@2fff0d30
一篇文章,让你彻底弄懂生产者–消费者问题
wait/notify的消息通知机制
预备知识
Java 中,可以通过配合调用 Object 对象的 wait() 方法和 notify()方法或 notifyAll() 方法来实现线程间的通信。
在线程中调用 wait() 方法,将阻塞当前线程,直至等到其他线程调用了调用 notify() 方法或 notifyAll() 方法进行通知之后,当前线程才能从wait()方法处返回,继续执行下面的操作。
wait
该方法用来将当前线程置入休眠状态,直到接到通知或被中断为止。
在调用 wait()之前,线程必须要获得该对象的对象监视器锁,即只能在同步方法或同步块中调用 wait()方法。
调用wait()方法之后,当前线程会释放锁。
如果调用wait()方法时,线程并未获取到锁的话,则会抛出IllegalMonitorStateException异常.notify
该方法也要在同步方法或同步块中调用,即调用前线程也必须要获得该对象的对象级别锁,如果调用 notify()时没有持有适当的锁,也会抛出 IllegalMonitorStateException。
该方法任意从WAITTING状态的线程中挑选一个进行通知,使得调用wait()方法的线程从等待队列移入到同步队列中,等待有机会再一次获取到锁。
调用notify后,当前线程不会马上释放该对象锁,要等到程序退出同步块后,当前线程才会释放锁。notifyAll
该方法与 notify ()方法的工作方式相同,重要的一点差异是:
notifyAll 使所有原来在该对象上 wait 的所有线程都退出WAITTING状态,使得他们全部从等待队列中移入到同步队列中去,等待下一次能够有机会获取到对象监视器锁。
wait/notify消息通知潜在的一些问题
通知过早
notify 通知的遗漏很容易理解,即 threadA 还没开始 wait 的时候,threadB 已经 notify 了,这样,threadB 通知是没有任何响应的,当 threadB 退出 synchronized 代码块后,threadA 再开始 wait,便会一直阻塞等待,直到被别的线程打断。
比如在下面的示例代码中,就模拟出notify早期通知带来的问题:
1 | public class EarlyNotify { |
示例中开启了两个线程,一个是WaitThread,另一个是NotifyThread。NotifyThread会先启动,先调用notify方法。然后WaitThread线程才启动,调用wait方法,但是由于通知过了,wait方法就无法再获取到相应的通知,因此WaitThread会一直在wait方法出阻塞,这种现象就是通知过早的现象。
针对这种现象,解决方法,一般是添加一个状态标志,让waitThread调用wait方法前先判断状态是否已经改变了没,如果通知早已发出的话,WaitThread就不再去wait。
对上面的代码进行更正:
1 | public class EarlyNotify { |
这段代码只是增加了一个isWait状态变量,NotifyThread调用notify方法后会对状态变量进行更新,在WaitThread中调用wait方法之前会先对状态变量进行判断,
在该示例中,调用notify后将状态变量isWait改变为false,因此,在WaitThread中while对isWait判断后就不会执行wait方法,从而避免了Notify过早通知造成遗漏的情况。
总结
在使用线程的等待/通知机制时,一般都要配合一个 boolean 变量值(或者其他能够判断真假的条件),在 notify 之前改变该 boolean 变量的值,
让 wait 返回后能够退出 while 循环(一般都要在 wait 方法外围加一层 while 循环,以防止早期通知),或在通知被遗漏后,不会被阻塞在 wait 方法处。这样便保证了程序的正确性。
等待wait的条件发生变化
如果线程在等待时接受到了通知,但是之后等待的条件发生了变化,并没有再次对等待条件进行判断,也会导致程序出现错误。
下面用一个例子来说明这种情况
1 | public class ConditionChange { |
1 | Thread-1 list为空 |
异常原因分析:在这个例子中一共开启了3个线程,Consumer1,Consumer2以及Productor。
- 首先Consumer2调用了wait方法后,线程处于了WAITTING状态,并且将对象锁释放出来。
- 因此,Consumer1能够获取对象锁,从而进入到同步代块中,当执行到wait方法时,同样的也会释放对象锁。
- 因此,productor能够获取到对象锁,进入到同步代码块中,向list中插入数据后,通过notifyAll方法通知处于WAITING状态的Consumer1和Consumer2线程。
- consumer1得到对象锁后,从wait方法出退出,删除了一个元素让List为空,方法执行结束,退出同步块,释放掉对象锁。
- 这个时候Consumer2获取到对象锁后,从wait方法退出,继续往下执行,这个时候Consumer2再执行lock.remove(0);就会出错,因为List由于Consumer1删除一个元素之后已经为空了。
解决方案:
过上面的分析,可以看出Consumer2报异常是因为线程从wait方法退出之后没有再次对wait条件进行判断,
因此,此时的wait条件已经发生了变化。解决办法就是,在wait退出之后再对条件进行判断即可。
1 | public class ConditionChange { |
上面的代码与之前的代码仅仅只是将 wait 外围的 if 语句改为 while 循环即可,(使用while被称为自旋锁,一直自旋,等待不符合时退出)
这样当 list 为空时,线程便会继续等待,而不会继续去执行删除 list 中元素的代码。总结
在使用线程的等待/通知机制时,一般都要在 while 循环中调用 wait()方法,
因此需要配合使用一个 boolean 变量(或其他能判断真假的条件,如本文中的 list.isEmpty()),
满足 while 循环的条件时,进入 while 循环,执行 wait()方法,
不满足 while 循环的条件时,跳出循环,执行后面的代码。
“假死”状态
现象
如果是多消费者和多生产者情况,如果使用notify方法可能会出现“假死”的情况,即唤醒的是同类线程。原因分析
假设当前多个生产者线程会调用wait方法阻塞等待,当其中的生产者线程获取到对象锁之后使用notify通知处于WAITTING状态的线程,
如果唤醒的仍然是生产者线程,就会造成所有的生产者线程都处于等待状态。解决办法
将notify方法替换成notifyAll方法,如果使用的是lock的话,就将signal方法替换成signalAll方法。
总结
在Object提供的消息通知机制应该遵循如下这些条件:
- wait要加条件判断,避免先通知
- wait条件判断要在while循环中(使用while被称为自旋锁),而不是在if中,避免条件改变
- 使用notifyAll而不是notify,避免’假死’
基本的使用范式如下:
1 | // 在Java中调用wait方法的标准习惯用法 |
wait/notifyAll实现生产者-消费者
利用wait/notifyAll实现生产者和消费者代码如下:
1 | public class ProductorConsumer { |
输出结果:
1 | 生产者pool-1-thread-1 生产数据-232820990 |
使用Lock中Condition的await/signalAll实现生产者-消费者
参照Object的wait和notify/notifyAll方法,Condition也提供了同样的方法:
针对wait方法void await() throws InterruptedException当前线程进入等待状态,如果其他线程调用condition的signal或者signalAll方法并且当前线程获取Lock从await方法返回,如果在等待状态中被中断会抛出被中断异常;long awaitNanos(long nanosTimeout)当前线程进入等待状态直到被通知,中断或者超时;boolean await(long time, TimeUnit unit)throws InterruptedException同第二种,支持自定义时间单位boolean awaitUntil(Date deadline) throws InterruptedException当前线程进入等待状态直到被通知,中断或者到了某个时间针对notify方法void signal()唤醒一个等待在condition上的线程,将该线程从等待队列中转移到同步队列中,如果在同步队列中能够竞争到Lock则可以从等待方法中返回。void signalAll()与上面的区别在于能够唤醒所有等待在condition上的线程
也就是说wait—>await,notify—->Signal。另外,关于lock中condition消息通知的原理解析可以看详解Condition的await等待和signal通知机制
如果采用lock中Conditon的消息通知原理来实现生产者-消费者问题,原理同使用wait/notifyAll一样。
直接上代码:
1 | public class ProductorConsumer { |
输出结果:
1 | 消费者pool-1-thread-9 消费数据:1146627506 |
使用BlockingQueue实现生产者-消费者
由于BlockingQueue内部实现就附加了两个阻塞操作。
- 当队列已满时,阻塞向队列中插入数据的线程,直至队列中未满;
- 当队列为空时,阻塞从队列中获取数据的线程,直至队列非空时为止。
关于BlockingQueue更多细节可以看并发容器之BlockingQueue
可以利用BlockingQueue实现生产者-消费者为题,阻塞队列完全可以充当共享数据区域,就可以很好的完成生产者和消费者线程之间的协作。
1 | public class ProductorConsumer { |
输出结果:
1 | 消费者pool-1-thread-7正在消费数据1520577501 |
可以看出,使用BlockingQueue来实现生产者-消费者很简洁,这正是利用了BlockingQueue插入和获取数据附加阻塞操作的特性。
